问题描述:在进行PyTorch调用时报如下错误
AssertionError: The NVIDIA driver on your system is too old (found version 9010). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver. 原因分析:刚刚重装的系统,其显卡驱动是由Windows 10自身提供的,可能版本比较旧,需要安装最新的驱动。
解决:在NVIDIA官网上重新下载对应的显卡驱动并安装即可(注意:是驱动,并非CUDA)
将指定的模块加载到调用进程的地址空间中。指定的模块可能会导致其他模块被加载。对于其他加载选项,请使用 LoadLibraryEx函数。
LoadLibrary是一个宏定义:
def UNICODE #define LoadLibrary LoadLibraryW #else #define LoadLibrary LoadLibraryA #endif // !UNICODE HMODULE WINAPI LoadLibrary( _In_ LPCTSTR lpFileName ); 入参说明:
lpFileName [in]
模块的名称。这可以是库模块(.dll文件)或可执行模块(.exe文件)。指定的名称是模块的文件名,与模块定义(.def)文件中的LIBRARY关键字所指定的与库模块本身中存储的名称无关。
如果字符串指定完整路径,则该函数仅搜索该模块的路径。
如果字符串指定一个没有路径的模块名称或者相对路径,则该函数使用标准搜索策略来查找模块;
如果该功能找不到该模块,则该功能失败。
指定路径时,一定要使用反斜杠(\),而不是正斜杠(/)。
如果字符串指定了没有路径的模块名称,并且省略了文件扩展名,则函数会将缺省库扩展名.dll附加到模块名称。要防止函数将.dll附加到模块名称,请在模块名称字符串中包含尾随点字符(.)。
--------------------- 返回值:
如果函数成功,则返回值是模块的句柄。
如果函数失败,则返回值为NULL。要获得扩展错误信息,请调用 GetLastError
-----------------------------------------------------------------------------------------------------------------
__stdcall约定
如果通过VC++编写的DLL欲被其他语言编写的程序调用,应将函数的调用方式声明为__stdcall方式,WINAPI都采用这种方式,而C/C++缺省的调用方式却为__cdecl。__stdcall方式与__cdecl对函数名最终生成符号的方式不同。若采用C编译方式(在C++中需将函数声明为extern "C"),__stdcall调用约定在输出函数名前面加下划线,后面加“@”符号和参数的字节数,形如_functionname@number;而__cdecl调用约定仅在输出函数名前面加下划线,形如_functionname。
Windows编程中常见的几种函数类型声明宏都是与__stdcall和__cdecl有关的(节选自windef.h):
#define CALLBACK __stdcall //这就是传说中的回调函数
#define WINAPI __stdcall //这就是传说中的WINAPI
#define WINAPIV __cdecl
#define APIENTRY WINAPI //DllMain的入口就在这里
#define APIPRIVATE __stdcall
#define PASCAL __stdcall
在lib.h中,应这样声明add函数:
int __stdcall add(int x, int y);
依赖库:push.js
npm安装:npm install push.js --save
第一步:获取弹出消息的权限
页面:login.vue
代码如下:
import Push from 'push.js'
created(){
Push.Permission.request();
},
第二步:推送桌面通知消息
页面:header.js(或其它使用页面)
代码如下:
import Push from 'push.js'
mounted(){
this.pushMessage('消息通知的内容');
},
methods: {
//推送弹框消息
pushMessage(message){
Push.create("消息通知的标题", {
body: message,
requireInteraction: true,
//icon: '/icon.png',
timeout: 600000,
});
},
}
转载于:https://www.cnblogs.com/yanganglanyu/p/11088536.html
在线免费图片压缩工具 前端技术站 1、for(let item of response.data.result) { 用item操作每一条数据。 } item:定义的每一条的变量
response.data.result:要循环的数组
2、response.data.result.forEach((item, index) => { 用item操作每一条数据。 }) response.data.result:要循环的数组
index:索引
在小程序中 查看
输入个链表的头结点,从尾到头反过来打印出每个结点的值 public static void printListInverselyUsingIteration(ListNode root) { Stack<ListNode> stack = new Stack<>(); while (root != null) { stack.push(root); root = root.nxt; } ListNode tmp; while (!stack.isEmpty()) { tmp = stack.pop(); System.out.print(tmp.val + " "); } }
解决方法:
移除pom.xml中相关依赖,再重新添加即可。
情况及具体解决方法如下:
1、在Maven Project中 Dependencies 出现红色波浪线
Maven项目展示 2、查询本地仓库:jar包已存在
存在的报错文件 3、解决方法:把对应项目的pom.xml中相关依赖剪切,然后回退即可,效果如图:
修改pom.xml文件 4、恢复正常,不再出现红色波浪线 (最好是在剪切以后执行以下maven的clean操作)。
总结:当不是由于引入jar包不存在的情况的时候,就要考虑到这种情况问题(IDEA的BUG),先删除pom.xml文件的依赖,然后执行Maven的clean方法,最后回撤删除的pom.xml文件的依赖,即可成功。
template<typename PointT, class Tree > int pcl::search::KdTree< PointT, Tree >::nearestKSearch (
const PointT & point,
int k,
std::vector< int > & k_indices,
std::vector< float > & k_sqr_distances
) const
Search for the k-nearest neighbors for the given query point. 搜索给定查询点邻域周围最近的K个点
Parameters: [in] p_q the given query point
[in] k the number of neighbors to search for
[out] k_indices the resultant indices of the neighboring points
[out] k_sqr_distances the resultant squared distances to the neighboring points
目录
1.千篇一律
2.点睛之笔
所做项目与第三方合作,系统间存在接口调用,需要做授权登录。我们的项目整体使用SSM框架,认证登陆采用了shiro框架,密码在数据库中经过盐值(salt)+Md5加密,外部无法获知密码明文,导致无法验证通过,所以想到了免密登录的方式解决。
在网上查阅了一些贴子,套路基本一样,照搬了全部代码,发现在强转AuthenticationToken为自定义Token时报错,父类无法强转为子类。经过研究源码,只需要再多复写一个类就可以解决。具体过程如下:
1.千篇一律 1)创建枚举类LoginType
/** * 登录类型 */ public enum LoginType { PASSWORD("password"), // 密码登录 NOPASSWD("nopassword"); // 免密登录 private String code;// 状态值 private LoginType(String code) { this.code = code; } public String getCode() { return code; } } 2)自定义token类CustomeToken,继承UsernamePasswordToken类,通过构造方法区分密码登录和免密登录。
/** * 自定义token 继承UsernamePasswordToken, * 账号密码登陆(password) 和 免密登陆(nopassword) */ public class CustomeToken extends UsernamePasswordToken { private static final long serialVersionUID = -2564928913725078138L; private LoginType type; public CustomeToken() { super(); } public CustomeToken(String username, String password, LoginType type, boolean rememberMe, String host) { super(username, password, rememberMe, host); this.
【博物纳新】是UWA旨在为开发者推荐新颖、易用、有趣的开源项目,帮助大家在项目研发之余发现世界上的热门项目、前沿技术或者令人惊叹的视觉效果,并探索将其应用到自己项目的可行性。很多时候,我们并不知道自己想要什么,直到某一天我们遇到了它。
更多精彩内容请关注:lab.uwa4d.com
简介 Deform是一个Unity的网格变形工具框架,使用JoySystem+Burst编译器工作,在CPU端获得更好的性能。它拥有便捷易用的Editor工具,可实现包括Blend、Twist等内置的40多种变形效果,当然也支持用户自己编写的Custom Deformer。
以下为部分效果图:
每一种类型的变形效果称为Deformer,而接收变形效果的网格物体称为Deformable。在每一类Deformer中会把计算量较大的顶点位置计算逻辑定位为IJobParallelFor类型的Job。
以下为预制的膨胀变形器BulgeDeformer中定义的网格顶点位置算法:
[BurstCompile(CompileSynchronously = COMPILE_SYNCHRONOUSLY)] public struct BulgeJob : IJobParallelFor { public float factor; public float top; public float bottom; public bool smooth; public float4x4 meshToAxis; public float4x4 axisToMesh; public NativeArray<float3> vertices; public void Execute(int index) { var point = mul(meshToAxis, float4(vertices[index], 1f)); var normalizedDistanceBetweenBounds = (clamp(point.z, bottom, top) - bottom) / (top - bottom); if (smooth) normalizedDistanceBetweenBounds = smoothstep(0f, 1f, normalizedDistanceBetweenBounds); var signedDistanceBetweenBounds = (normalizedDistanceBetweenBounds - 0.
文章目录 一、什么是后缀式?1.后缀式的特点是什么?2.如何将中缀式转换成后缀式? 二、图表示法1.什么是抽象语法树,举例说明?2. 举例说明什么是DAG,与抽象语法树有什么区别?3.产生赋值语句抽象语法树的属性文法 三、地址码1.什么是三地址码?各种语句的三地址码形式;2.三地址码的三种表示形式:三元式、四元式、间接三元式;3.三元式、四元式、间接三元式各自优缺点4. 三元式与间接三元式之间的区别5. 对赋值语句产生地址代码的属性文法 一、什么是后缀式? 1.后缀式的特点是什么? 每一运算符都置于其运算对象之后,即操作数写在前面,算符写在后面。
表达式中各个运算是按运算符出现的顺序进行的,故无需用括号来指示运算顺序,因而又称为无括号式。
2.如何将中缀式转换成后缀式? 从左到右遍历中缀表达式的每个数字和符号,若是数字就输出,即成为后缀表达式的一部分;
若是符号,则判断其与栈顶符号的优先级,是右括号或者优先级低于栈顶符号(乘除优先加减,)则栈顶元素依次出栈并输出,并将当前符号进栈,一直到最终输出后缀表达式为止
二、图表示法 1.什么是抽象语法树,举例说明? 在语法树中去掉一些对翻译不必要的信息后,获得
的更有效的源程序的中间表示,这种经过变换后的语法
树称为抽象语法树。
内部结点代表操作符,它的孩子代表对应的操作数。
树表示法:
索引法:
2. 举例说明什么是DAG,与抽象语法树有什么区别? DAG(Directed Acyclic Graph)无循环有向图, 与抽象语法树类似,但是在一个DAG中代表公共子表达式的结点可有多个父结点
区别: DAG可以成环 抽象语法树没有环表现在公共子表达式上,DAG中代表公共子表达式的结点具有多个父结点,而一棵语法树中公共子表达式被表示为重复子树。 3.产生赋值语句抽象语法树的属性文法 三、地址码 1.什么是三地址码?各种语句的三地址码形式; 最基本的形式: x=y op z
其中x、y、z为名字、常数或编译时产生的临时变量;
op代表运算符号。每个语句的右边只能有一个运算符
2.三地址码的三种表示形式:三元式、四元式、间接三元式; 三元式: 三元式顾名思义就是带有三个域的记录结构(i)(op,arg1,arg2)
四元式:四元式实际上是一种“三地址语句”的等价表示,是一个带有四个域的记录结构。(op,arg1,arg2,result)四元式只能有一个运算符,所以,一个复杂的表达式只能由多个四元式构成的序列表示。
间接三元式:建立两个与三元式有关的表格,一个称为三元式表,用于存放各元式本身;另一个称为执行表,它按照三元式的执行顺序,依次列出相应各三元式在三元式表中的位置,也就是说我们用一个三元式表连同执行表来表示中间代码。通常我们称这种表示方法为间接三元式。
3.三元式、四元式、间接三元式各自优缺点 三元式没有result字段,且不需要临时变量,故三元式比四元式占用的存储空间少在进行代码优化处理时,需要从现有的运算序列中删去某些运算或挪动一些运算的位置,这对三元式来说是很困难的,但四元式之间的相互联系是通过临时变量来实现的,所以影响就比较小由于间接三元式在执行表中已经依次列出每次要执行的那个三元式,若其中有相同的三元式,则仅需在三元式表中保存其中之一,即就是说三元式的项数一般比执行表的项数少当进行代码优化需要挪动运算顺序时,则只需对执行表进行相应地调整,而不必再改动三元式本身 4. 三元式与间接三元式之间的区别 由于间接三元式在执行表中已经依次列出每次要执行的那个三元式,若其中有相同的三元式,则仅需在三元式表中保存其中之一,即三元式的项数一般比执行表的项数少;当进行代码优化需要挪动运算顺序时,则只需对执行表进行相应地调整,而不必再改动三元式本身,这样,就避免了前面讲到的因改变三元式的顺序所引起的麻烦 5. 对赋值语句产生地址代码的属性文法
参考:https://www.cnblogs.com/enumhack/p/7474731.html
以下是参考以上链接大佬博客内容:
QT中加载动态链接库 一.添加第三方的头文件
首先,添加头文件 #include "ControlCAN.h"
然后,再将这个头文件放到工程的目录下,就OK了,非常的简单
二.添加.lib文件
首先,将.lib文件放到对应的工程目录下(当然,放到其他路径也可以)。
但是,仅仅做这一步是不行的,工程不会主动去包含这个.lib文件,你必须告诉他,lib文件在哪里,才可以。
然后,在QT的工程中,你会看到一个.pro文件,比如,我的工程名为test_qt,那么我的文件就是test_qt.pro文件,在整 个QT界面的左上角,.pro文件是管理整个工程的,当要打开一个工程的时候,只要打开.pro,就可以打开整个工 程的所有东西。
所以,我们要做的,就是在.pro文件中,加上一句话,告诉工程,.lib在哪里
LIBS += -LE:/project/QT/usbcan_info/ -lControlCAN //注意这边添加的是绝对路径
下面对这句话进行解析:
1)+=这个符号是连接在一起的,不要自做聪明,给分开了,写成+ = ,这样就是错的!
2)+=的左右两边可以有空格,也可以没有空格,随意的
3)-L之后紧接着就跟着.lib文件所在的目录,比如,我的目录是在E盘下的project目录下的QT目录下的usbcan_info下,注意,是紧跟着,不要分开,分开就错啦!
4)-l后面跟着的是.lib的文件名,注意,比如你的.lib文件时ControlCAN.lib,不要傻乎乎的写成了-lControlCAN.lib,不要带后缀,要写成-lControlCAN,同样,-l后面也没有空格
完成以上的操作,就可以指定.lib文件了。其实说穿了很简单,就是把.lib随便放到一个目录下,然后告诉工程,你的.lib放到哪里了,叫什么名字。
三.添加.dll文件
一个工程编译成功后,会在工程目录下生成2个目录,一个是debug目录,一个是release目录(注意,如果一个工程刚刚新建,是没有这2二个目录的,不信的朋友可以看看)。
其中,debug就叫做输出目录!因为工程编译后的.exe就在这个目录下。
然后,将.dll文件放到这个目录下。
以上内容为网上看到的第一种:
第二种:首先将你想要用的dll添加到你的工程文件中去,也就是跟你的mainwidows在一级中,然后
(1)在你的工程文件.h文件中加上一句:
extern "C"{ #include "xxxxxx.h"}//或者是在头文件中加上这样一句引用
(2)在你的pro文件中添加一句:
添加相对路径:LIBS += -L$$PWD/./ -lxxxxx(xxxxx这个表示的就是文件名)
这样你就可以找到你想要的dll文件了
pro文件中添加的内容参考博客:https://blog.csdn.net/Littlehero_121/article/details/104819235
【H5】 两种屏幕宽度大小自适应方式: 第一种 由于rem是获取html根属性的字体大小 改变html的字体大小,通过rem设置所以样式的宽高:
//rem为html的字体大小 通过改变html的字体大小达到适配的效果 remChange(); //监听屏幕改变resize事件 触发remChange方法 window.addEventListener("resize", remChange) function remChange() { const html = document.querySelector("html"); const width = html.getBoundingClientRect().width; //拿到适配器的宽度值 //若屏幕宽为375px则1rem = 100px 若不是则按比例增大或减小 html.style.fontSize = width / 3.75 + 'px'; } 第二种 将宽度固定为750px; 通过获取屏幕宽度与750的比例关系将所有样式宽高按照相对应的比例缩放:
remChange(); window.addEventListener('resize', remChange); function remChange() { remove(); let width = window.screen.width; let fixedw = 750; let scale = width / fixedw; //获取到的屏幕宽度比上自定义的750宽度 获得对应比例 let meta = document.createElement("meta"); meta.setAttribute('name', 'viewport'); //将对应比例填入meta标签即可实现宽度自适应 meta.
06 19 矩阵链(LINIX):
是去信任分类账,它跟踪、存储和确认交易和钱包地址,权力制衡证明(PoCB)用以维护平台的共识和安全。在矩阵链中,矿工和验证者共同控制共识。
TokenGazer《一问到底》是一档辨析区块链领域一级市场项目优劣的优质栏目。每一期将针对区块链领域早期的一级市场项目,邀请项目负责人做客现场,和社群内百余名研究员深度问答、科学辨析。旨在通过项目方与研究员高质量的对弈问答,打造专业级别的项目评析平台,厘清项目价值,探寻早期优质项目。同时,让社群用户真正参与价值评析,传递评析方法,在“问与答”中获取价值信息。
矩阵链 CTO Henry Duong
TokenGazer 研究员 Tiger
01 TokenGazer Researcher Tiger:
There are many cryptocurrency projects using DAG, such as IOTA, NANO and MIXIN. How is LINIX different from them? Why do you call LINIX “The World's First DAG Infused Blockchain”?
Henry ¦ LINIX :
LINIX is completely different from existing DAG based networks on the market currently. NANO and IOTA are all trying to use DAG as a replacement data structure for blockchain, LINIX isn’t.
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-2-2
今天在学习使用tabBar的时候引用pagePath的路径的时候出现的错误,该错误的原因是所有的页面路径都需要在pages这个集合中先声明。所以,出现错误的原因也就是要么你的路径写错了,要么就是你的页面路径没有在pages中定义,其实也就是一个问题就是你的路径和在pages中的声明的路径不一致。
我就是写错了页面名字导致的
git clone http://邮箱(或用户名):密码@仓库 示例:
邮箱 xw@qq.com 密码: xw 仓库: http://git.test.com/abc/demo 注意: 邮箱中的 @ 要使用 %40 代替。仓库 URL 不需要 http:// 。 命令:
git clone http://xw%40qq.com:xw@git.test.com/abc/demo 转载于:https://www.cnblogs.com/daysme/p/11038988.html
树形菜单的制作
开发工具与关键技术:Visual Studio 2015 制作树形菜单
作者:李国旭
撰写时间:2019年6月16日
首先,这个树形菜单在我们做的项目里面使用的频率呢可以经常见得到的,接下来我给大家介绍一下这个树形菜单的制作程序。
它呢主要是靠一个核心的控件来操作就是“jQuery.ztree”用它来搭建树形菜单既简单又高效,而且效果上也符合我们的需求和项目的需要。
树形菜单方法:第一,树形的样式也可以自己写也可以通过选用它的样式,例如:
<link href="~/Content/zTree/zTreeStyle/zTreeStyle.css" rel="stylesheet" />//基础样式 <link href="~/Content/zTree/awesomeStyle/awesome.css" rel="stylesheet" />//鲜艳样式 <link href="~/Content/zTree/metroStyle/metroStyle.css" rel="stylesheet" />//经典样式 以上的这三个树形菜单的样式呢,每一个的树形样式都是不一样的:有基础的、鲜艳的、经典的样式
第二,要写好树形的ul标签的容器,用来装树形菜单的样式:
然后呢,引入JS的控件下图的第一个是树形菜单的核心控件、第二是树形菜单的勾选控件,第三就是用来编辑的控件。  那么引入了之后就需要给他们配置JS的树形参数,图中的圈是添加和移除的伪类,就是鼠标移入就会显示出添加、编辑和删除子节点,下面的就是他们的代码设置了之后呢就可以自己自定义创建,删除,嵌套,重命名,和选择节点 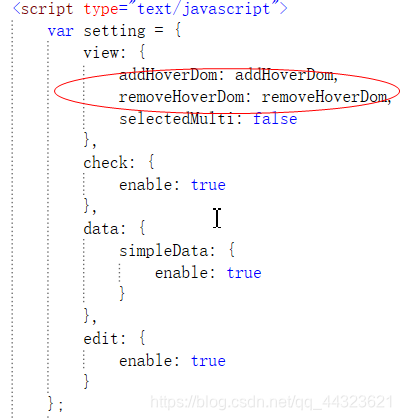 $(document).ready(function () { $.fn.zTree.init($("#treeDemo"), setting, zNodes); }); var newCount = 1; function addHoverDom(treeId, treeNode) { var sObj = $("#" + treeNode.tId + "_span"); if (treeNode.editNameFlag || $("#addBtn_" + treeNode.tId).length > 0) return; var addStr = "<span class='button add' id='addBtn_" + treeNode.tId + "
本文提出一种轻量级级联残差网络,速度快,性能也还不错。
提出问题 尽管深度学习方法提高了SR图像的质量,但速度慢,并不适用于真实场景。从这个角度来看,设计适合实际应用的轻量级深度学习模型非常重要。
一种方法是减少参数的数量,实现这一目标的方法有很多,但最简单和有效的方法是使用递归网络。例如,DRCN使用递归网络来减少冗余参数,而DRRN通过向DRCN添加残差体系结构来改进DRCN。与标准CNN相比,这些模型有效地减少了模型参数的数量,表现出良好的性能。
然而,这些模型有两个缺点:
(1)在将输入图像输入CNN模型之前,先对其进行上采样;
(2)增加网络的深度或宽度,以补偿由于使用递归网络而造成的损失。这些点使模型能够在重构时维持图像的细节,但增加了操作次数和时间。
解决方法 提出了一种级联剩余网络(CARN)及其变体移动网络(CARN-M)。
模型的中间部分是基于ResNet设计,除此之外,还在局部和全局级别使用级联机制来集成来自多个层的特性,这可以反映不同级别的输入表示,以便接收更多信息。除了CARN模型,我们还提供了CARN- m模型,性能稍有下降,但是速度更快。
关于轻量级网络文献:
(1)Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding.
(2)Squeezenet: Alexnet-level accuracy with 50x fewer parameters and 0.5 mb model size.论文构建一个基于alexnet的体系结构,使用50×更少的参数就可以达到类似的性能水平。
(3)Mobilenets: Efficient convolutional neural networks for mobile vision applications
应用深度可分卷积建立高效的网络(出自Rigid-motion scattering for image classification这篇文章)
网络架构 可以看到,CARN就是对残差块进行了局部(级联块内,残差块间)和全局的融合(级联块间)。详细来说,总共有9个残差块,三个为一组,共有三组,也就是图中的三个级联块。三级联块间,进入每一个级联块前,都要对之前的级联块的输出利用1x1的卷积核进行融合压缩;每个级联块内又有三个残差块,三个残差块间也是同样的结构。
级联结构类似于在残差块间进行密集连接,但由于densenet有点区别,他利用1x1,RDN中用3x3。
它具有以下三个特征:
全局和局部级联连接中间特征是级联的,且被组合在1×1大小的卷积块中使多级表示和快捷连接,让信息传递更高效 高效的CARN 为了提升CARN的效率,作者提出了一种残差-E模块。
这种方法和MobileNet类似,但是深度卷积被替换为了分组卷积。因为分组卷积中间必然有trade-off,因此在用户可以选择合适的分组大小。
为了进一步降低参数,论文中用到了一种与递归神经网络相似的技巧,就是将级联模块的参数共享,让模块高效递归。
除了分组卷积这个策略之外,另一种减少参数的策略归残差块,类似于DRRN和MemNet。实验表明,分组卷积似乎优于递归结构。
pull out a half hour chunk from the start of an audio file: ffmpeg -i your_audio_file.mp3 -acodec copy -t 00:30:00 -ss 00:00:00 half_hour_split.mp3 split an audio file (that is just under 5 hours long) into half an hour chunks using ffmpeg, into a folder called “split” mkdir split; X=0; while( [ $X -lt 5 ] ); do echo $X; ffmpeg -i big_audio_file.mp3 -acodec copy -t 00:30:00 -ss 0$X:00:00 split/${X}a.mp3; ffmpeg -i big_audio_file.
【H5】 移动端的基本事件:
一、基础事件 1、PC端事件 onclick 鼠标点击触发
onmousedown 鼠标按下触发
onmousemove 鼠标移动触发
onmouseup 鼠标抬起触发
2、移动端触屏事件 ontouchstart 手指按下触发
ontouchmove 手指移动触发
onTouchend 手指抬起触发
3、PC端事件和移动端事件的区别 通过on的方式添加touch事件在谷歌模拟器下无效
通过on的方式添加事件会前后覆盖
鼠标事件在移动端可以使用,但有300毫秒的延迟
4、事件监听 1 addEventListener(‘不带on的事件名’,事件函数,是否冒泡 )事件绑定
2 绑定多少个事件就执行多少个,不会存在前后事件覆盖的问题
3 在谷歌模拟器下一直识别
4 冒泡 从下往上,把事件一直向上传递,点击最下面的元素,最下面先执行
5 捕获 从上往下,把事件一直向下传递,点击最上面的元素,最上面先执行
5、event对象 1 标准事件函数默认的第一个参数
2 是描述发生事件的详细信息
6、阻止默认事件 1 事件默认行为:当一个事件发生的时候浏览器自己会默认做的事情
2 比如正常情况下,鼠标可以拖拽图片,a标签跳转,手指长按可以选中文字,右键菜单等
3 e.preventDefault( ) 阻止默认行为,且解决在IOS上有网页回弹的橡皮筋现象
4 但网页上的所有滚动条失效
5 一般不会阻止默认
7、阻止冒泡 1 在需要的时候的,标准用e.stopPropagation( ) 阻止冒泡问题,比如有时需要复制文本
8、事件点透问题 a) PC端鼠标事件,在移动端也可以正常使用,事件的执行会有300毫秒的延迟
b) 问题的产生是,点击了页面之后,浏览器会记录点击下去的坐标
c) 300毫秒之后,在该坐标找到现在的元素,执行该事件
9、点透问题解决办法 a) 阻止默认事件,但在部分安卓机不支持