分布式唯一ID生成算法—雪花算法思路
前言
雪花算法用于生成分布式唯一ID,总共有64位
首先想一个问题,我们为什么需要分布式唯一ID呢?
- 数据库自增ID:可用性难以保证,数据库挂了就寄了
- uuid其实是一个不错的本地生成唯一ID方案,但是其无法保证趋势递增,并且uuid过长,往往用字符串表示,作为主键建立索引查询效率低
- 时间戳也可以,但是在并发1000的情况下,会生成重复的ID,这是一个致命弱点
ID结构
雪花算法生成的一个ID长度固定为64字节
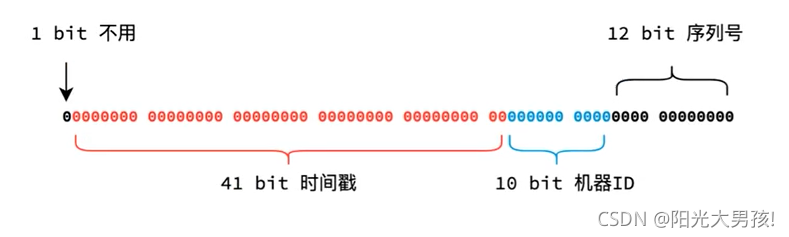
- 第一位是表示正负数,而分布式唯一ID是整数,所以应恒为0
- 后41位是时间戳
- 后10位是机器ID,即最多可以容纳1024个机器
- 最后12位是序列号,即最多4096个ID,从0~4095
那么也就是说一个时间戳的时间范围内,雪花算法可以生成1024*4096个ID,大约是四百万+个,可以看出来效率是非常高的
官方给出的实现示例
/** Copyright 2010-2012 Twitter, Inc.*/
package com.twitter.service.snowflake
import com.twitter.ostrich.stats.Stats
import com.twitter.service.snowflake.gen._
import java.util.Random
import com.twitter.logging.Logger
/**
* An object that generates IDs.
* This is broken into a separate class in case
* we ever want to support multiple worker threads
* per process
*/
class IdWorker(val workerId: Long, val datacenterId: Long, private val reporter: Reporter, var sequence: Long = 0L)
extends Snowflake.Iface {
private[this] def genCounter(agent: String) = {
Stats.incr("ids_generated")
Stats.incr("ids_generated_%s".format(agent))
}
private[this] val exceptionCounter = Stats.getCounter("exceptions")
private[this] val log = Logger.get
private[this] val rand = new Random
val twepoch = 1288834974657L
private[this] val workerIdBits = 5L
private[this] val datacenterIdBits = 5L
private[this] val maxWorkerId = -1L ^ (-1L << workerIdBits)
private[this] val maxDatacenterId = -1L ^ (-1L << datacenterIdBits)
private[this] val sequenceBits = 12L
private[this] val workerIdShift = sequenceBits
private[this] val datacenterIdShift = sequenceBits + workerIdBits
private[this] val timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits
private[this] val sequenceMask = -1L ^ (-1L << sequenceBits)
private[this] var lastTimestamp = -1L
// sanity check for workerId
if (workerId > maxWorkerId || workerId < 0) {
exceptionCounter.incr(1)
throw new IllegalArgumentException("worker Id can't be greater than %d or less than 0".format(maxWorkerId))
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
exceptionCounter.incr(1)
throw new IllegalArgumentException("datacenter Id can't be greater than %d or less than 0".format(maxDatacenterId))
}
log.info("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId)
// 获取ID
def get_id(useragent: String): Long = {
if (!validUseragent(useragent)) {
exceptionCounter.incr(1)
throw new InvalidUserAgentError
}
val id = nextId()
genCounter(useragent)
reporter.report(new AuditLogEntry(id, useragent, rand.nextLong))
id
}
def get_worker_id(): Long = workerId
def get_datacenter_id(): Long = datacenterId
def get_timestamp() = System.currentTimeMillis
protected[snowflake] def nextId(): Long = synchronized {
var timestamp = timeGen()
if (timestamp < lastTimestamp) {
exceptionCounter.incr(1)
log.error("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new InvalidSystemClock("Clock moved backwards. Refusing to generate id for %d milliseconds".format(
lastTimestamp - timestamp))
}
// 如果当前时间戳还是上次生成ID的时间戳
if (lastTimestamp == timestamp) {
// 将序列号+1
sequence = (sequence + 1) & sequenceMask
// 如果序列号大于4095,得等下一个时间戳
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp)
}
} else {// 如果是新的时间戳,序列号从0开始
sequence = 0
}
lastTimestamp = timestamp
((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence
}
protected def tilNextMillis(lastTimestamp: Long): Long = {
var timestamp = timeGen()
while (timestamp <= lastTimestamp) {
timestamp = timeGen()
}
timestamp
}
protected def timeGen(): Long = System.currentTimeMillis()
val AgentParser = """([a-zA-Z][a-zA-Z\-0-9]*)""".r
def validUseragent(useragent: String): Boolean = useragent match {
case AgentParser(_) => true
case _ => false
}
}
雪花算法的问题
- 依赖时间戳,如果机器时间被回退,会出现ID重复的问题
- 而且一般公司如果机器没有1024个那么多,可以将10位长度的机器id进行设计优化。