YOLO系列之YOLO V1
1.写在前面
这是我发布的目标检测系列论文之二,前面一个章节,我们已经讨论过了目标检测系列中最基础的东西,常见指标以及相关的一些概念。那么本次,我将介绍一下YOLO系列的初代版本,YOLO V1
论文链接点击直达
2. 模型介绍
前面我们已经说过了,One-Stage算法具有实时检测的FPS,实用性特别的好,因此作为YOLO系列的第一代版本,论文的名字就已经说明了一切You only Look Once
我们先来看一下效果:


再来看看YOLO V1在当时的性能如何?

我们可以看到YOLO在损失比较小mAP的情况下,带来了极大的FPS增益效果,因此在当时还是引发了不小的轰动,所以我们来看看他是怎么实现的吧!
3.原理讲解
那么作者是怎么做的呢?首先我们来看一张图片:
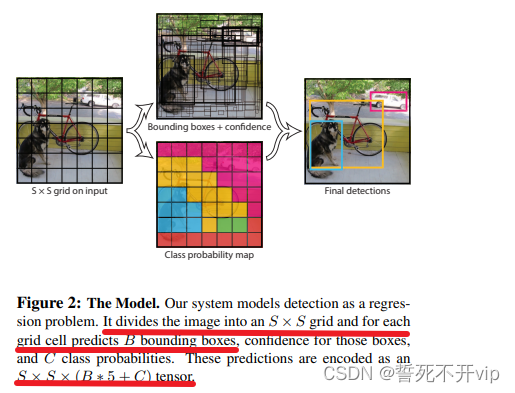
这张图像很好得诠释了YOLO V1的模型,它先把图像resize成448x448的大小,然后将这个图像分割成SxS的大小,也就是说哈,我拿一个刀,将图像切成一个个的豆腐块。
再之后,每个豆腐块(网格)需要预测B个bounding box(论文中指出,B=2),除了预测位置信息之外,还要预测一个confidence参数,表示该候选框能有多大的把握框中了物体。
这里可能有小伙伴就迷糊了,你一个豆腐块你怎么预测候选框(bounding box)呢?其实意思是这样的,就是你可以理解成以豆腐块为中心,画B个框出来,然后如果有物体就逐步调整和Ground truth最大IOU的那个框,直到这个框和ground truth 的IOU最大。还是不理解就看下面的图:
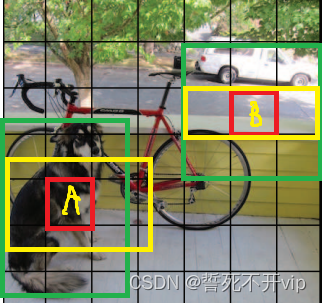
A,B这两个格子是SxS格子中的任意两个,以A为中心,画出了一个绿色一个黄色连个框框,同样B也是如此。之后我们发现。,B这个格子里好像没有物体欸,那么他的confidence必然很低,那么我们不管他,我们看A这个格子,直观上看,确实是框中了物体,所以他的confidence必然高。那么我们继续看,明显绿色这个框要比黄色这个框要好,因为啥?因为绿色框和Ground Truth的IOU高呀!那么我们就舍弃黄色的框,保留绿色的框。
那么明白了之后,我们就要分析每个豆腐块会预测出多少个数字了,这很重要!
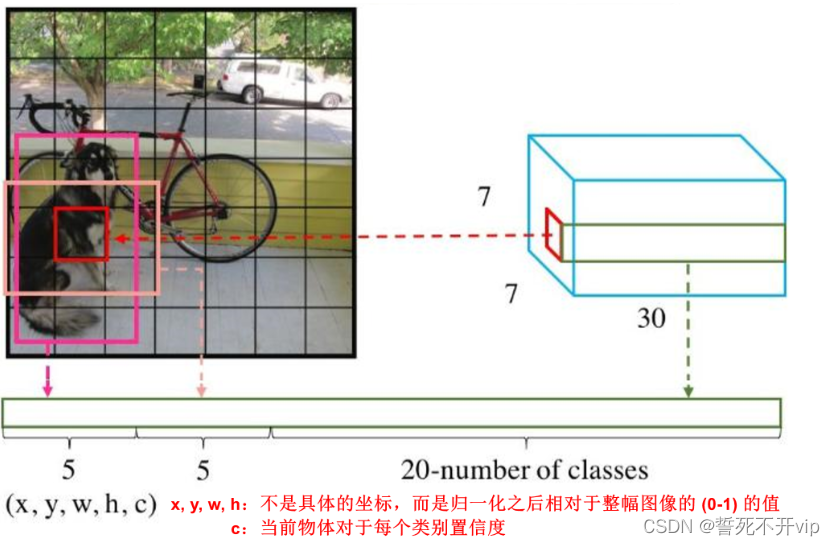
首先,对于一个豆腐块,我要知道候选框的框框左上角的x,y值,以及这个框的宽和高吧
然后刚才说了,还要有一个置信度吧,表示这个框有多大可能圈中了物体
并且每个豆腐块产出B个框,如图,粉色和橙红色的框。
那么就有B*5个数了,然后这个豆腐块还要预测我框出的是什么类别,因为pascal voc数据集一共有20个类别,那么我们还要带上20个类别概率,表示当前框框框中的是当前类别的概率是多少。就像这样:
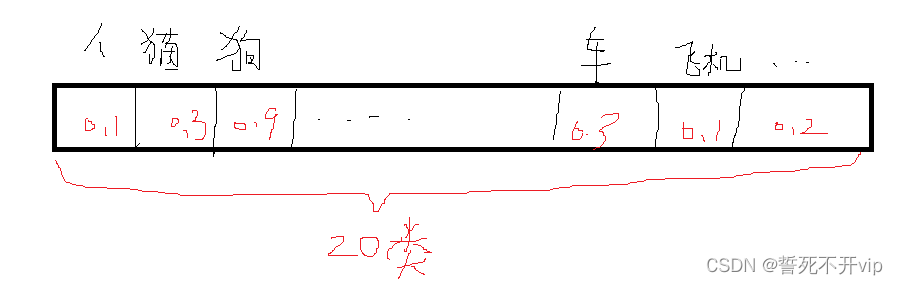
好了,接下来我们来讨论一下是如何调整候选框,使得候选框的IOU最大的呢?这时候不得不提到它的损失函数:
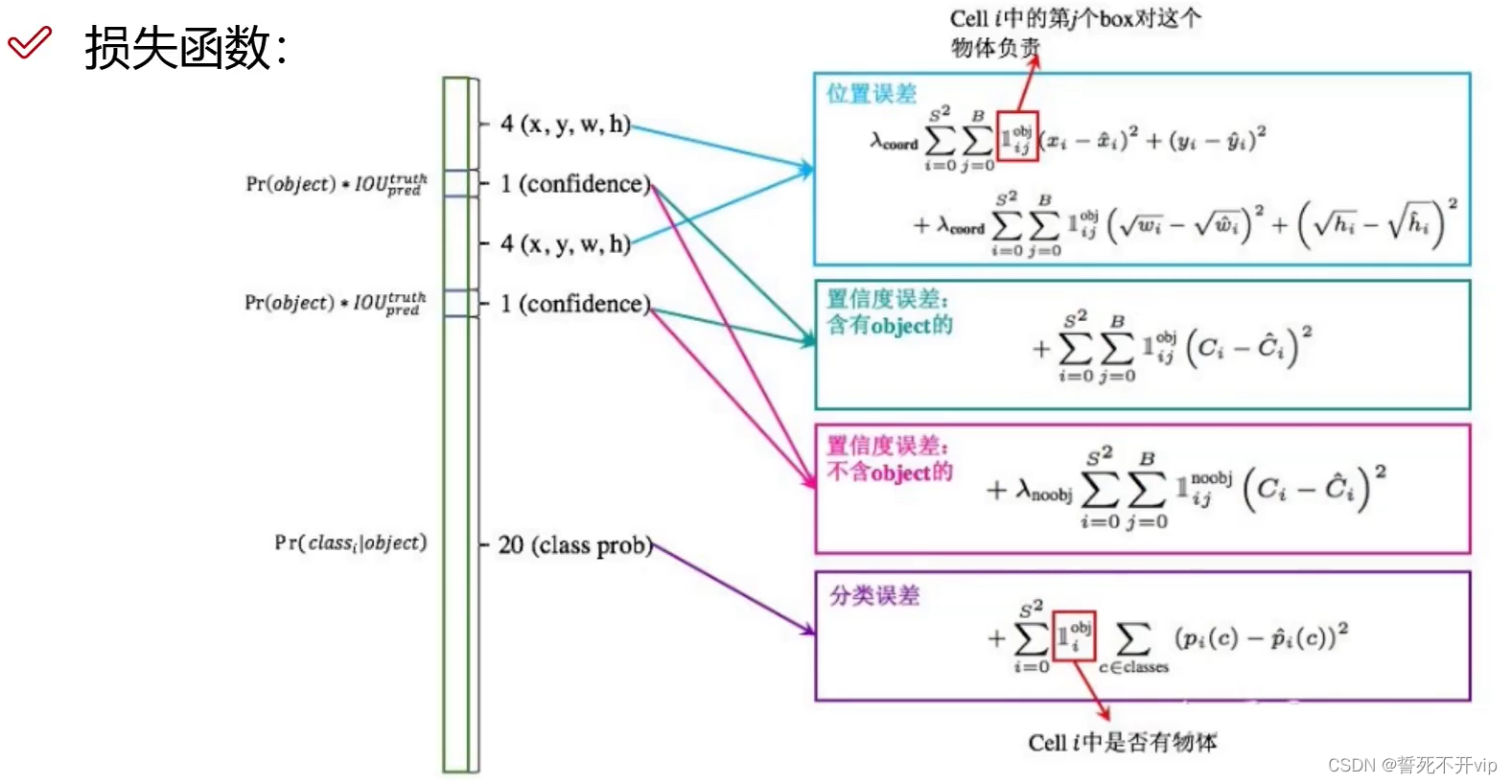
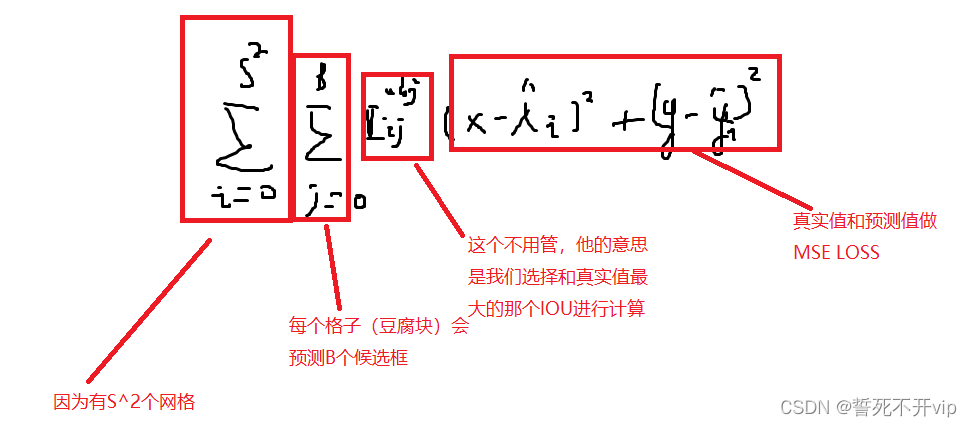
首先我们看位置误差。
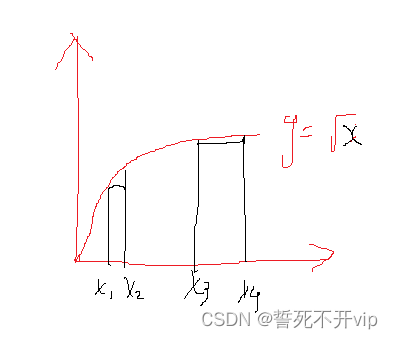
如图:对于这个函数,当时小物体的时候,你移动非常小的距离,他变化的很快,但是对于大物体,你移动比较大的距离,他变得很小。不敏感。
然后我们再来看看置信误差,这里为什么含有obj的误差和不含obj的误差分开来算呢?
这是因为呀,在图像中,一般前景比较少,背景比较多,那如果两者一起算了,很容易出现负样本过多,正负比例不均衡!所以要加一个 λ n o o b j \lambda_{noobj} λnoobj作为惩罚因子!
最后的分类误差就是简单的MSE Loss,在这里不再赘述。
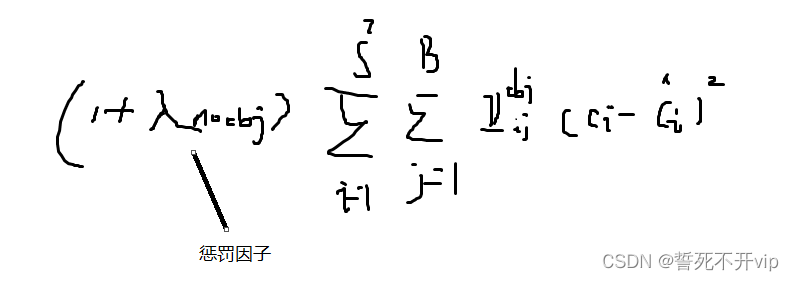
总结一下:
- 一共有SxS个格子,然后每个格子会画两个框
- 根据置信度,看看哪些框圈中了物体
- 再比较框和Grouth Truth 的IOU大小,保留大的
- 通过Loss逐步调整候选框的大小
4.写在最后
这次我们分析了yolo 的第一个版本,他虽然有诸多优点,比如快速简单,但是还是存在如下缺点:
- 每个Cell(豆腐块)只预测一个类别,如果重叠那么就无解
- 小物体效果检测很一般,候选框长宽比可选但是单一