在java8之后使用stream将list转成map,以及对list中的map分组求和;Stream的常用操作;按条件分割集合;map和flatmap
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import org.junit.Test;
/**
* Created by Jackielee on 2017
* @author: lizhilong
* @date: 2017-11-24 10:13:57
* @Copyright: 2017 www.aliyun.com Inc. All rights reserved.
*/
public class DemoListToMap {
List<Student> list = Arrays.asList(new Student(1, 18, "阿龙", GenderColumn.BOY.getCode()),
new Student(2, 17, "小花", GenderColumn.GIRL.getCode()),
new Student(3, 17, "阿浪", GenderColumn.LADYBOY.getCode()));
@Test
public void listToMapByObjectValue(){
// value 为对象 student -> student jdk1.8返回当前对象
Map<Integer, Student> map = list.stream().collect(Collectors.toMap(Student::getId, student -> student));
// 遍历打印结果
map.forEach((key, value) -> {
System.out.println("key: " + key + " value: " + value);
});
}
@Test
public void listToMapByNameValue(){
// value 为对象中的属性
Map<Integer, String> map = list.stream().collect(Collectors.toMap(Student::getId, Student::getName));
map.forEach((key, value) -> {
System.out.println("key: " + key + " value: " + value);
});
}
}
value为对象执行结果:
key: 1 value: Student [id=1, age=18, name=阿龙, gender=0]
key: 2 value: Student [id=2, age=17, name=小花, gender=1]
key: 3 value: Student [id=3, age=17, name=阿浪, gender=2]
value为字段执行结果:
key: 1 value: 阿龙
key: 2 value: 小花
key: 3 value: 阿浪
要注意的是map的key必须唯一,所以有可能出现不唯一的时候,就会报错
@Test
public void listToMapByAgeKey(){
// value 为对象中的属性
Map<Integer, String> map = list.stream().collect(Collectors.toMap(Student::getAge, Student::getName));
}
会有key重复异常
java.lang.IllegalStateException: Duplicate key 小花
因为age有相同就会报错 此时stream包下Collectors.toMap方法有一个重载方法的参数,这个参数可以传一个合并的函数解决冲突
@Test
public void listToMapByAgeKey(){
// value 为对象中的属性
Map<Integer, String> map = list.stream().collect(
Collectors.toMap(Student::getAge, Student::getName, (key1, key2) -> key1)
);
map.forEach((key, value) -> {
System.out.println("key: " + key + " value: " + value);
});
}
执行结果:
key: 17 value: 小花
key: 18 value: 阿龙
对List<Map>分组求和
List<Map> list = new ArrayList();
Map<String,Integer> test = new HashMap(){{
put("id",1);
put("qty",1);
}};
list.add(test);
test = new HashMap(){{
put("id",1);
put("qty",2);
}};
list.add(test);
test = new HashMap(){{
put("id",2);
put("qty",2);
}};
list.add(test);
test = new HashMap(){{
put("id",2);
put("qty",2);
}};
list.add(test);
test = new HashMap(){{
put("id",3);
put("qty",2);
}};
list.add(test);
test = new HashMap(){{
put("id",4);
put("qty",2);
}};
list.add(test);
Map<Object,List<Map>> result = list.stream().collect(Collectors.groupingBy(it -> it.get("id")));
System.out.println(result);
Map tmpResult = new HashMap();
result.forEach((k,v)->{
tmpResult.put(k,v.stream().mapToInt(e -> (int) e.get("qty")).sum());
});
System.out.println(tmpResult);

简化一些
理解了上面的操作后其实代码还可以简化
这里回顾下 list 的声明类型是List<Map<String,Integer>>
在经过 collect(Collectors.groupingBy(it -> it.get("id"))) 之后获得的数据类型是Map<String,List<Map>>
Map tmpResult = new HashMap();
list.stream()
.collect(Collectors.groupingBy(it -> it.get("id")))
.forEach((k,v)->{
tmpResult.put(k,v.stream().mapToInt(e -> (int) e.get("qty")).sum());
});
System.out.println("tmpResult:" + tmpResult);
中间
list.stream()
.collect(Collectors.groupingBy(it -> it.get("id")))
获得的是一个Map但是这个map不是我们的要最终结果,需要的是最后的tmpResult这个map
再进一步简化
经过了上面2遍的操作后,逐渐加深对stream的理解
其实还可以更加简化
Map result = list.stream()
.collect(Collectors.groupingBy(it -> it.get("id")))
.entrySet().stream()
.collect(Collectors.toMap(e -> e.getKey(),e -> e.getValue().stream().mapToInt(a -> (int) a.get("qty")).sum(),(key1,key2)->key1));
System.out.println("result:" + result);
和之前的结果是一样的,但是这个更简化一步到位
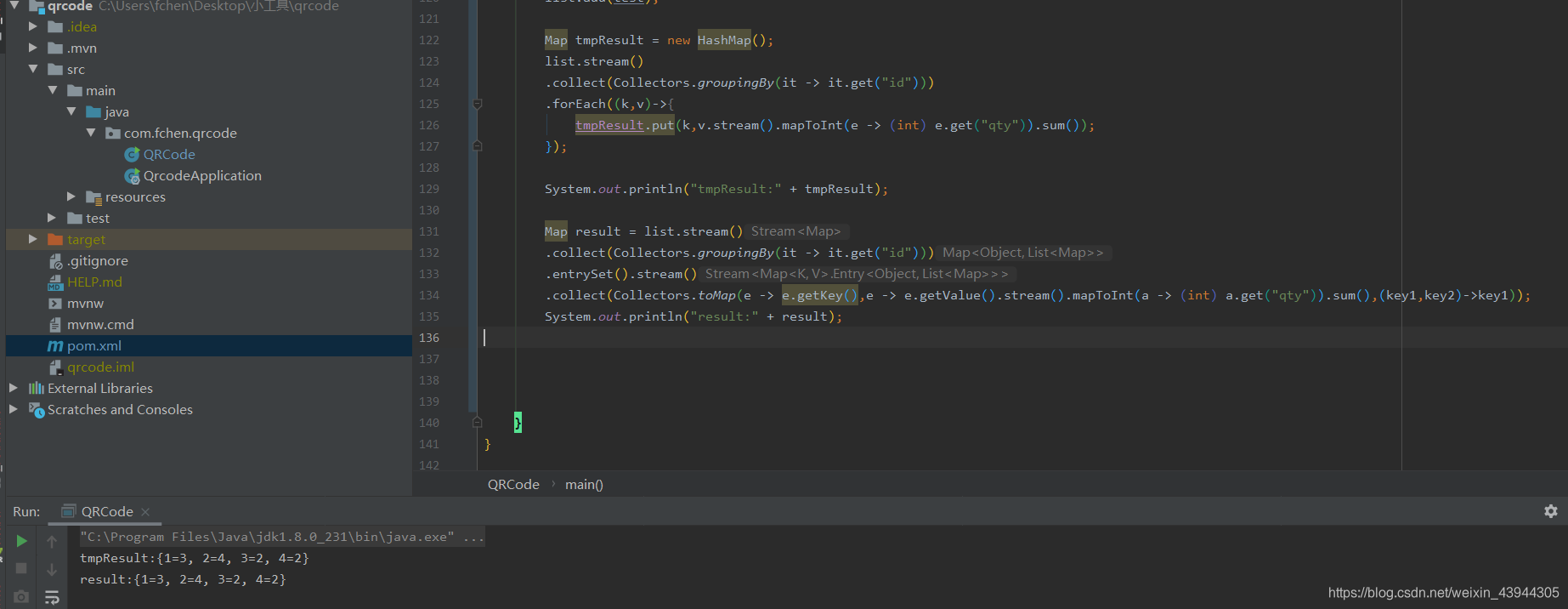
filter过滤
该操作会接受一个谓词(一个返回boolean的函数)作为参数,并返回一个包括所有符合谓词的元素的流
filter中的方法返回 boolean类型 即 true/false,当里面的表达式 = true的时候表明当前元素被过滤掉了,剩下的都是返回false的元素。
list.stream()
.filter(TestObject::isMng)
.collect(Collectors.toList());
distinct去重;自定义distinct
distinct返回一个元素各异(根据流所生成元素的hashCode和equals方法实现)的流
List<Integer> numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
numbers.stream()
.filter(i -> i % 2 == 0)
.distinct()
.forEach(System.out::println);
自定义distinct和filter
默认的distinct用的是LinkedHashSet,其实就是用的HashMap的key的去重原理.
public class DistinctByProperty {
public static void main(String[] args) {
List<Book> list = new ArrayList<>();
{
list.add(new Book("Core Java", 200));
list.add(new Book("Core Java", 300));
list.add(new Book("Learning Freemarker", 150));
list.add(new Book("Spring MVC", 200));
list.add(new Book("Hibernate", 300));
}
list
.stream()
//filter和distinct都可以自定义
.filter(distinctByKey(b -> b.getName()))
.distinct(distinctByKey(b -> b.getName()))
.forEach(b -> System.out.println(b.getName()+ "," + b.getPrice()));
}
private static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) {
Map<Object,Boolean> seen = new ConcurrentHashMap<>();
//putIfAbsent代表put成功时返回null,put的时候key已经存在了就直接返回key对应的值,即不等于null
//通过引入另一个集合,来筛选复杂对象
return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) == null;
}
}
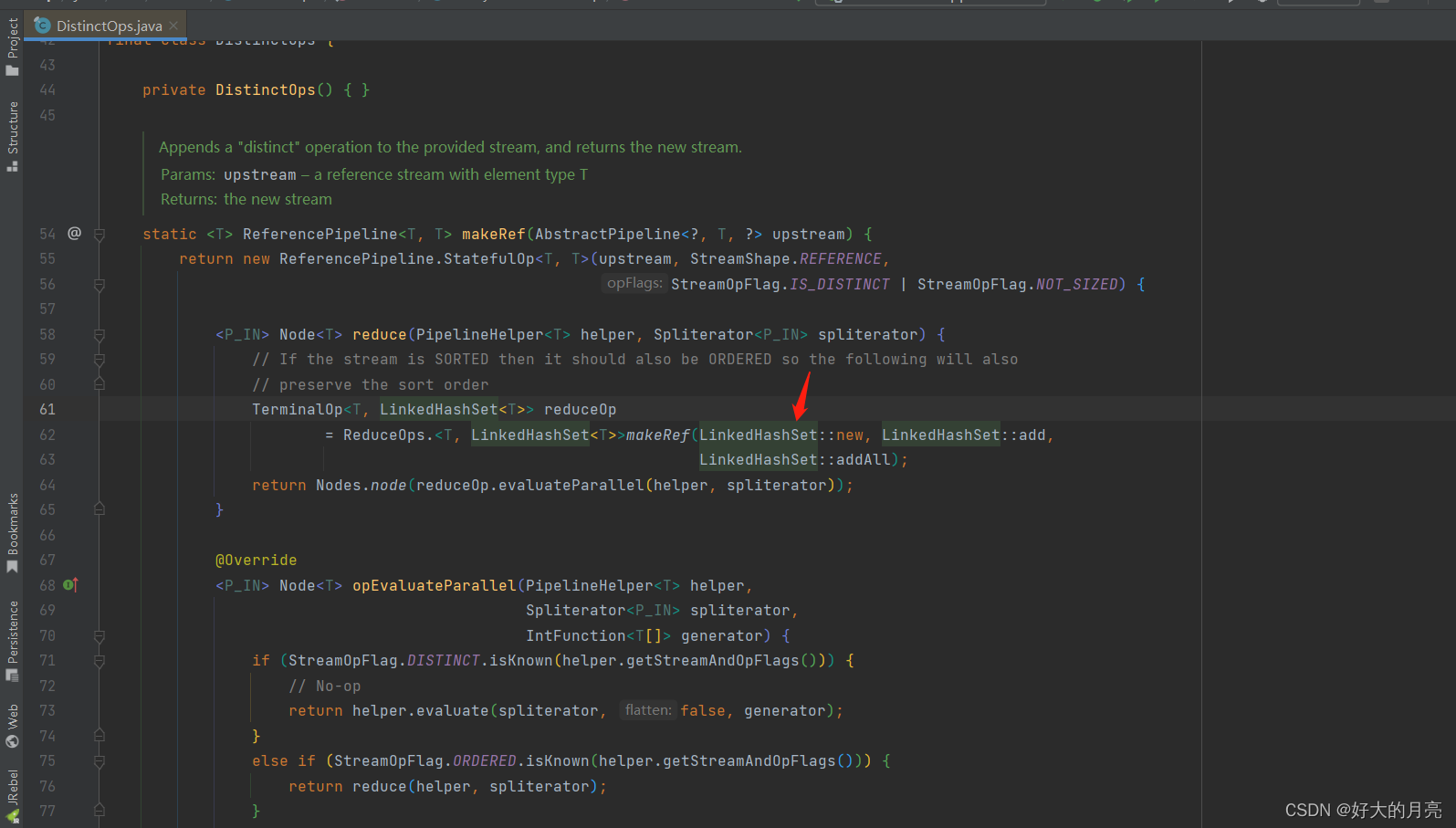
limit直接获取前几条记录
流支持limit(n)方法,该方法会返回一个不超过给定长度的流
获取前5条
list.stream()
.filter(u->u.getSex().equals("M"))
.limit(5).forEach(u->System.out.println(u.getName()));
skip跳过元素
流还支持skip(n)方法,返回一个扔掉了前n个元素的流
如果流中元素不足n个,则返回一个空流。
list.stream()
.filter(u->u.getSex().equals("M"))
//传入自定义比较排个序
.sorted(Comparator.comparing(TestObject::getName))
.skip(1)
.forEach(u->System.out.println(u.getName()));
map将集合中的元素通过一个闭包转成其他类型
流支持map方法,它会接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素
list.stream()
.map(TestObject::getName)
.collect(Collectors.toList())
.forEach(System.out::println);
anyMatch检查集合中是否至少有一个元素满足条件
anyMatch返回boolean类型true/false
if(list.stream().anyMatch(u->u.getName().equals("Ron"))){
System.out.println("Ron已经到了");
}
allMatch检查集合中的所有元素是否都满足条件
allMatch返回boolean类型true/false
if(list.stream().allMatch(u->u.getAge()>=10)){
System.out.println("很棒,都大于10岁");
}else{
System.out.println("原来都还没发育");
}
noneMatch检查集合中的元素是否都不满足条件,和allMatch相反
if(list.stream().noneMatch(u->u.getAge()<10)){
System.out.println("很棒,都大于10岁");
}else{
System.out.println("原来都还没发育");
}
findAny返回任意一个元素
list.stream()
.filter(u->u.getName().equals("Ron"))
.findAny()
.ifPresent(u->System.out.println(u.getName()));
findFirst返回第一个元素
list.stream()
.filter(u->u.isLeader())
.findFirst()
.ifPresent(u->System.out.println(u.getName()));
按照条件将一个集合分成两个集合
List<Integer> integers = [ 1,2,3,4,5,6,7,8,9]
//现在需要把集合按奇偶数分割为两个列表。这种情况下,我们可以使用Collectors.partitioningBy来分割:
Map<Boolean, List<Integer>> map =
integers.stream().collect(Collectors.partitioningBy(x -> x%2 == 0));
//partitioningBy会根据值是否为true,把集合分割为两个列表,一个true列表,一个false列表。
map和flatmap
在stream中一般map用的比较多,不过还有一个名字很像的flatmap。用法也很简单,就是将嵌套集合打平。
直接上demo吧
stream group by 后对每组list count
Map<String, Long> employeesByCity =
employees
.stream()
.collect(
Collectors.groupingBy(
Employee::getCity,
Collectors.counting()
)
);
stream group by 后取list的元素中的某个值计算平均值
@Test
public void groupingByAverageTest() {
Map<String, Double> employeesByCity =
employees
.stream()
.collect(
Collectors.groupingBy(
Employee::getCity,
Collectors.averagingInt(Employee::getSales)
)
);
}
stream group by 后取list的元素中的某个值计算总值
@Test
public void groupingBySumTest() {
Map<String, Long> employeesByCity =
employees
.stream()
.collect(
Collectors.groupingBy(
Employee::getCity,
Collectors.summingLong(Employee::getSales)
)
);
}
stream group by 后取list的元素中的某个值替换List
/**
* 使用java8 stream groupingBy操作,按城市分组list,将List转化为name的List
*/
@Test
public void groupingByCityMapList(){
Map<String, List<String>> namesByCity =
employees
.stream()
.collect(
Collectors.groupingBy(
Employee::getCity,
Collectors.mapping(Employee::getName, Collectors.toList())
)
);
}
/**
* 使用java8 stream groupingBy操作,按城市分组list,将List转化为name的Set
*/
@Test
public void groupingByCityMapListToSet(){
Map<String, Set<String>> namesByCity =
employees
.stream()
.collect(
Collectors.groupingBy(
Employee::getCity,
Collectors.mapping(Employee::getName, Collectors.toSet())
)
);
}
stream 使用对象 group by
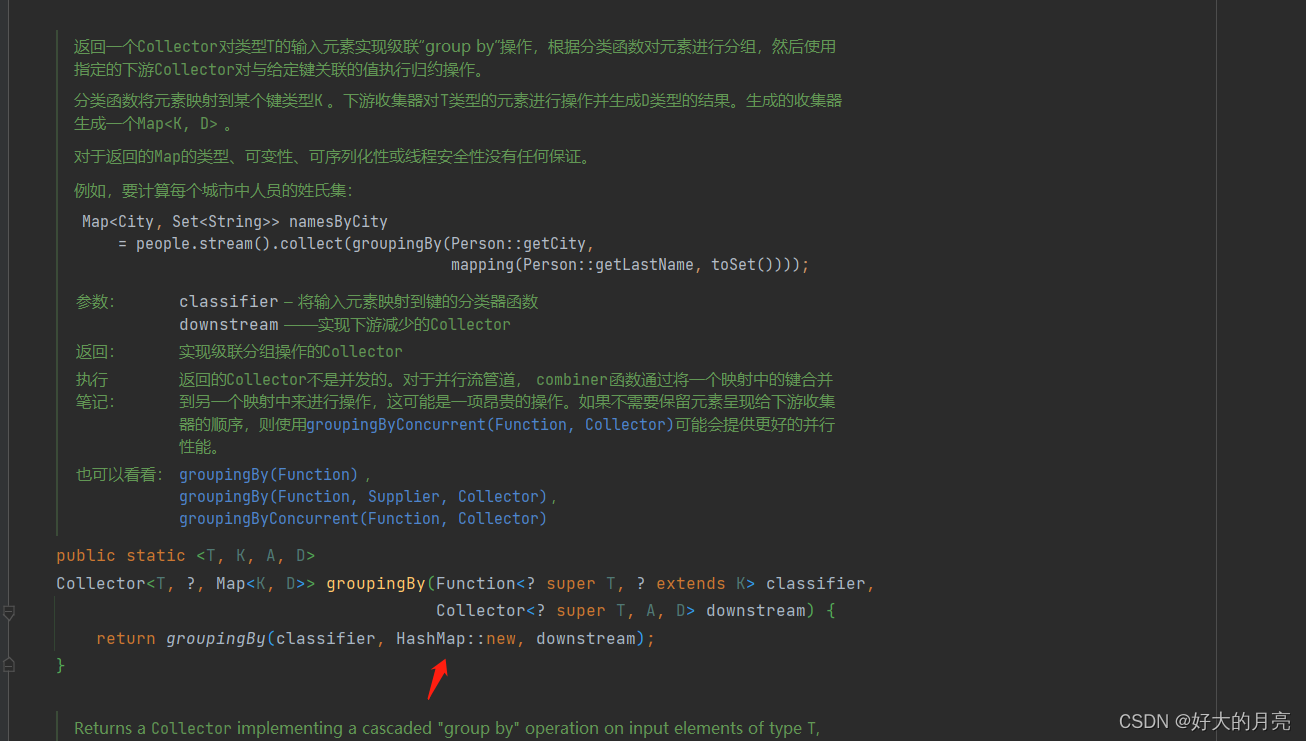
group by中可以看到使用了hashMap,hashMap在寻找key的时候,会先比较hashCode再比较equals
使用对象对分组条件时,我都会重写对象的hashCode和equals方法
/**
* 使用java8 stream groupingBy操作,通过Object对象的成员分组List
*/
@Test
public void groupingByObjectTest(){
List<BlogPost> blogPostList = Lists.newArrayList();
blogPostList.add(new BlogPost("post1", "zhuoli", 1, 30));
blogPostList.add(new BlogPost("post2", "zhuoli", 1, 40));
blogPostList.add(new BlogPost("post3", "zhuoli", 2, 15));
blogPostList.add(new BlogPost("post4", "zhuoli", 3, 33));
blogPostList.add(new BlogPost("post5", "Alice", 1, 99));
blogPostList.add(new BlogPost("post6", "Michael", 3, 65));
Map<Tuple, List<BlogPost>> postsPerTypeAndAuthor = blogPostList
.stream()
.collect(
Collectors.groupingBy(post -> new Tuple(post.getAuthor(), post.getType()))
);
}