java使用Tess4J实现OCR图片文字识别
介绍
Tess4J 是 Tesseract OCR 的 java api 实现库,你可以通过 java 调用来轻松的实现图片识别并提取文字,也就是 OCR 图片提取文字技术。
Tess4J 支持识别的的图片格式:
- TIFF、JPEG、GIF、PNG 和 BMP 图像格式
- 多页 TIFF 图像
- PDF文档格式
一、maven如下
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.7.0</version>
</dependency>
<!-- 解决输出的时候 slf4j 报错 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.8.0-beta4</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.8.0-beta4</version>
</dependency>
二、下载语言模型
如果因为网络问题,你访问不了 github 或语言模型下载缓慢失败,可以直接看第2步百度云下载。
1.下载语言模型
tesseract 支持一百多种语言识别,你可以从 Traineddata 语言模型说明下载页面 选择自己想要识别的.traineddata 格式的语言模型文件下载。
(1)特殊的模型
-
如果你想识别图片里的各种方向的文字可以下载 osd.traineddata 模型
-
如果你想识别图片里的各种数学公式、方程可以下载 equ.traineddata 模型
(2)语言模型
tesseract 在 GitHub 上的有三个独立的语言模型存储库 tessdata、tessdata-best、tessdata-fast 他们分别都存储了语言模型,他们的区别是:
| 如何训练得到的 | 速度 | 识别准确性 | 是否支持旧版 | 是否支持再训练 | |
|---|---|---|---|---|---|
| tessdata | 传统+LSTM(并整合tessdata-best) | 比 tessdata-best 更快 | 比 tessdata-best 准确度稍低 | 支持 | 不支持 |
| tessdata-best | 仅 LSTM(基于langdata) | 最慢 | 最准确 | 不支持 | 支持 |
| tessdata-fast | 比 tessdata-best 更小的 LSTM网络整合 | 最快的 | 最不准确 | 不支持 | 不支持 |
我测试识别一张多文字图片的时候,tessdata-best 效果最好但花了快10秒,tessdata 花了3秒但效果稍微差一点。你可以根据自己的需要去选择下载语言模型文件,我这里选择的是 tessdata-best 库里下载 chi_sim.traineddata (简体中文)、eng.traineddata (英文模型)。
因为网络问题,如果你访问不了 github 或下载缓慢,可以从我的百度云下载 tessdata 和 tessdata-best,里面包含了所有的语言模型文件,(如果你只需要中英文的模型可以看我第 2 步):
百度云下载: tessdata-4.1.0.zip 约 635 MB (链接:https://pan.baidu.com/s/1e2UKTpMqnfhpCoq6NquIAQ
提取码:jc9p)
百度云下载: tessdata_best-4.1.0.zip 约1.29 GB (链接:https://pan.baidu.com/s/1dcHpukvaH6Rtma_drfqD9g
提取码:w3gh)
(3)项目的 resources 文件夹下新建 tessdata 文件夹,然后把上面下载的 .traineddata 格式的语言模型文件复制到 tessdata 下。
2.百度云下载
如果因为网络问题,你访问不了 github 或下载缓慢失败,可以从百度云下载我的 tessdata.zip ,里面包含了中英文语言模型 ,解压后把 tessdata 文件夹复制到你的 resources 文件夹下即可:
百度云下载: tessdata.zip 约27MB (链接:https://pan.baidu.com/s/1nXHJ_e4kzOGHbFwh95ijEg
提取码:k1qu)
三、测试
1.测试代码
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
import java.awt.*;
public class MainServer {
public static void main(String[] args) throws TesseractException {
long start = System.currentTimeMillis();
System.out.println("开始OCR文字识图,请稍后...");
//加载要识别的图片
File image = new File("F:\\image\\test1.jpg");
//设置配置文件夹微视、识别语言、识别模式
Tesseract tesseract = new Tesseract();
tesseract.setDatapath("src/main/resources/tessdata");
//设置识别语言为中文简体,(如果要设置为英文可改为"eng")
tesseract.setLanguage("chi_sim");
//使用 OSD 进行自动页面分割以进行图像处理
tesseract.setPageSegMode(1);
//设置引擎模式是神经网络LSTM引擎
tesseract.setOcrEngineMode(1);
//开始识别整张图片中的文字
String result = tesseract.doOCR(image);
long time = System.currentTimeMillis()-start;
System.out.println("识别结束,耗时:"+time+" 毫秒,识别结果如下:");
System.out.println();
System.out.println(result);
}
}
上面示例中是识别整张图片中的文字,如果你只想识别图片中特定部分的文字,可以像下面这样选定长宽范围识别:
String result = tesseract.doOCR(image, new Rectangle(300, 200));
2.测试图片

3.效果
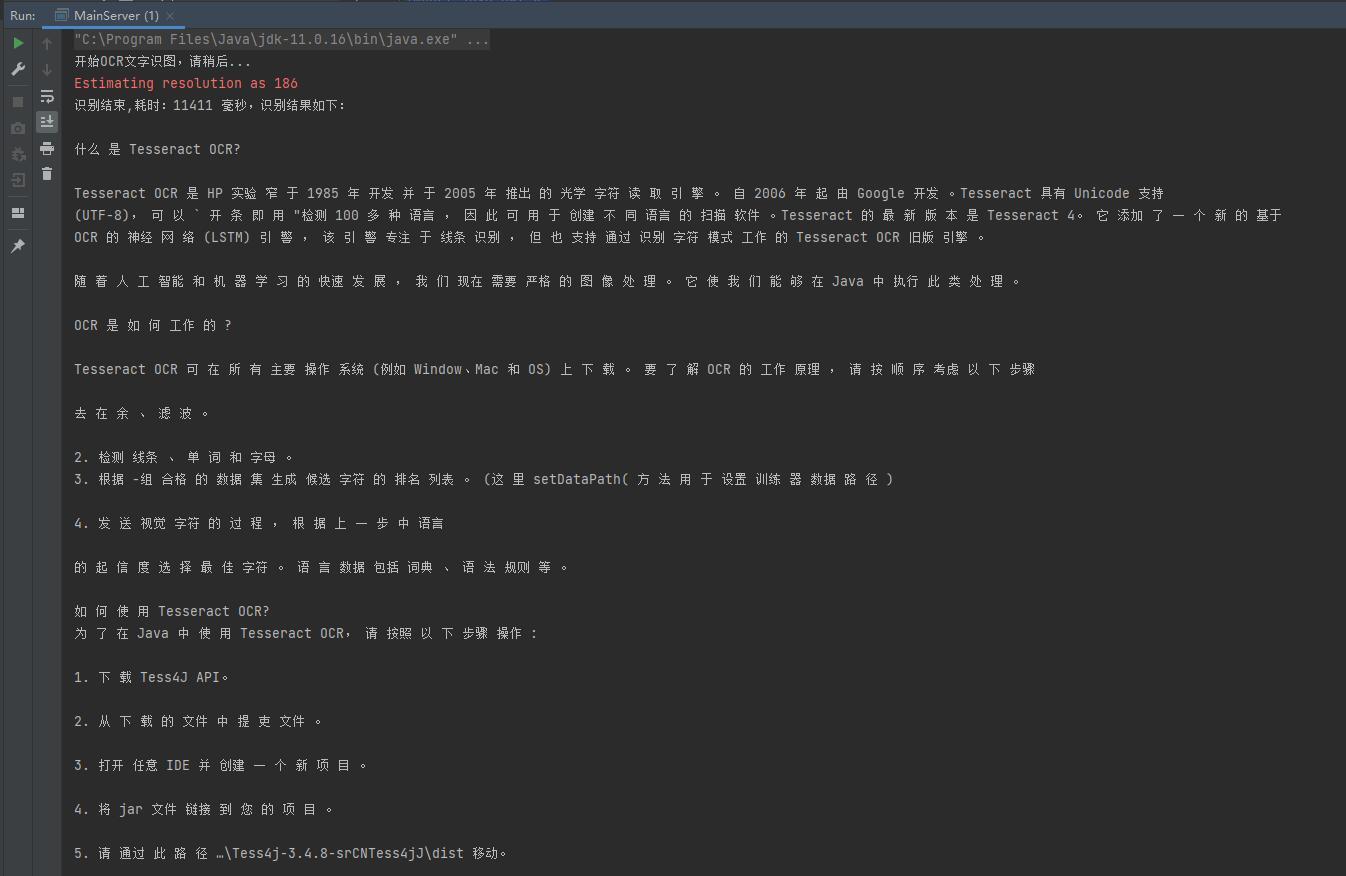
参考: