强化学习——基本概念+Q表格
基本概念
马尔可夫过程(MP):
一个马尔科夫过程可以由一个元组组成 〈S,P〉
- S 为(有限)的状态(state)集;
- P 为状态转移矩阵,
![Ps{s}'=P[S_{t+1}={s}'|S_{t}=s]](https://images2.imgbox.com/1e/3d/7QHQPDGq_o.png) 。所谓状态转移矩阵就是描述了一个状态到另一个状态发生的概率,所以矩阵每一行元素之和为1。
。所谓状态转移矩阵就是描述了一个状态到另一个状态发生的概率,所以矩阵每一行元素之和为1。
马尔可夫决策过程(MDP):
相对于MP,MDP加入了瞬时奖励 R(Immediate reward)、动作集合 A 和折扣因子 γ (Discount factor)。MDP由元组 〈S,A,P,R,γ〉 定义。其中
- S 为(有限)的状态(state)集;
- A 为有限的动作集;
- P 为状态转移矩阵。所谓状态转移矩阵就是描述了一个状态到另一个状态发生的概率。系统下一时刻的状态仅由当前时刻的状态决定,不依赖于以往的状态
![Ps{s}'=P[S_{t+1}={s}'|S_{t}=s,A_{t}=a]](https://images2.imgbox.com/e5/8e/SqiKJuBv_o.png)
- R 为回报函数(reward function), 系统下一时刻的奖励仅由当前时刻的状态决定,不依赖于以往的状态
![R_{s}^{a} = E\left [ R_{t}|S_{t}=s, A_{t}=a \right ]](https://images2.imgbox.com/87/db/Tw5egmXA_o.png)
- γ 为折扣因子,范围在[0,1]之间, 越大,说明agent看得越“远”。
回报
回报描述了从时间 t 起的总折扣奖励(区分奖励),用于衡量一个agent转移到一个state对于我们达到目的有“多有用”(how good)。即:
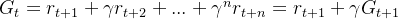
我们的最终的目标就是让回报的期望(expected return)最大。
状态值函数
值函数是在一个(一组)action下定义的,我们称之为策略(policy)。MDP中一个状态s在策略 π 下的值函数记为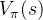 ,它代表从s开始的回报的期望。
,它代表从s开始的回报的期望。
![v_{\pi }(s)=E_{\pi }[G_{t}|S_{t}=s]](https://images2.imgbox.com/8b/ad/21YrzTdm_o.png)
动作值函数(action-value function)
从状态s开始,并执行动作a,然后遵循策略 π 所获得的回报的期望
![q_{\pi }(s,a)=E_{\pi } [G_{t}|S_{t}=s, A_{t}=a]](https://images2.imgbox.com/1b/85/LNp44hzN_o.png)
状态值函数和动作值函数的区别
这是两个概念,分别是状态价值V(s)和动作价值Q(s,a),前者是对环境中某一个状态的价值大小做的评估,后者是对在某状态下的动作的价值大小的评估。概念类似,但主要区别应该是体现在用途以及算法上吧,比如对于离散型的动作空间,可以单纯基于动作Q值去寻优(DQN算法),如果是动作空间巨大或者动作是连续型的,那么可以判断状态价值并结合策略梯度来迭代优化(AC算法)......简单来说就是不同场景下我们会选择动作值函数或者状态值函数来寻找最优策略
贝尔曼方程
状态值函数可以分解为瞬时回报加上后续状态的折扣值,即
![v_{\pi }(s)=E_{\pi }[R_{t+1}+\gamma v_{\pi }(S_{t+1})|S_{t}=s]](https://images2.imgbox.com/7d/5a/rqPjLgl9_o.png)
动作值函数也可以如此分解:
![q{_\pi}(s,a)=E_\pi[R_{t+1}+\gamma q{_\pi}(S_{t+1},A_{t+1})|S_{t}=s,A_{t}=a]](https://images2.imgbox.com/20/c0/8gG3g3Fj_o.png)
即:贝尔曼方程描述了当前状态值函数和其后续状态值函数之间的关系,即状态值函数(动作值函数)等于瞬时回报的期望加上下一状态的(折扣)状态值函数(动作值函数)的期望。
贝尔曼最优方程(Bellman Optimality Equation)
强化学习的目标是找到一个最优策略,使得回报最大。准确的说是使值函数最大,包括状态值函数和动作值函数,分别记为 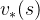 和
和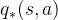 。对于任意一个MDPs,总是存在一个最优的策略
。对于任意一个MDPs,总是存在一个最优的策略 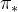 ,在使用这个策略时就能取得最优值函数,即
,在使用这个策略时就能取得最优值函数,即 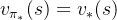 ,
, 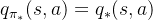
策略分类
有模型策略:环境的状态转移概率和奖励函数已知
无模型策略:在未知的环境里,任何决策的概率函数和奖励函数是未知的。
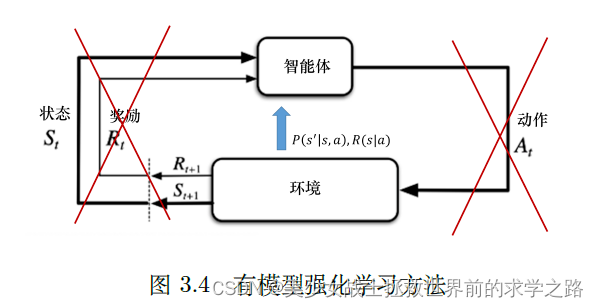
即:在状态s下采取a行动的奖励以及转移到状态S'的概率是已知的
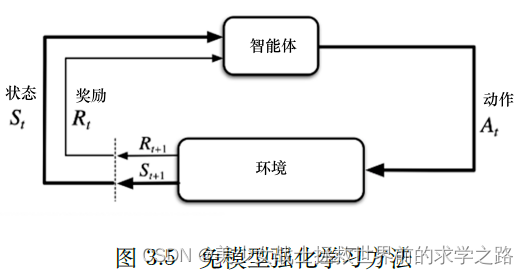
在状态s下采取a行动的奖励以及转移到状态S'的概率是无法获得的,在这种情况下,我们可以选择让主体不断与环境交互,采集大量的轨迹数据,从轨迹中获取信息来改进策略,从而获得更多的奖励。
Q表格
主体不断与环境交互的结果是,可以得到一张Q表格,它像是一本生活手册。里面的每一个Q函数(动作值函数)记录了在某个状态下选择某个动作,后续能够获得多少总奖励(回报期望)。最开始的时候表格会全部初始化为0。智能体会不断和环境交互得到不同的轨迹,当交互的次数足够多的时候,我们就可以估算出每一个状态下,每个动作的平均总奖励,进而更Q表格,表格的更新就是强化的过程。 强化是指我们可以用下一个状态的价值来更新当前状态的价值,其实就是强化学习里面自举的概念。
例子:悬崖行走问题
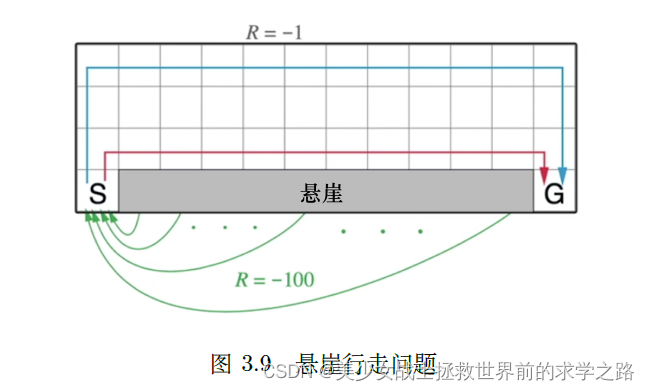
游戏规则:智能体从出发点S 出发,到达目的地G,同时避免掉进悬崖(cliff),每走一步就有−1 分的惩罚,掉进悬崖会有−100 分的惩罚。掉进悬崖游戏不会结束,智能体会回到出发点,游戏继续,直到到达目的地结束游戏。智能体需要尽快地到达目的地,为了到达目的地,智能体可以沿着例如蓝线和红线的路线行走。
在这个例子中:“每走一步就有−1 分的惩罚,掉进悬崖会有−100 分的惩罚”属于瞬时回报,那如何计算在某个状态下采用某个动作所获得的未来的总奖励(Q函数)呢?
未来的总奖励:
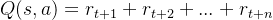
若任务是一个持续的没有尽头的任务,将采取动作a后,后续的所有奖励加起来作为当前的状态价值就很不合适,所以可以引入折扣因子,即:
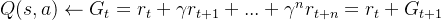
参考文献:
强化学习——马尔科夫决策过程和贝尔曼方程 - 野风的文章 - 知乎 https://zhuanlan.zhihu.com/p/34021617
《Easy RL:强化学习教程》