卷积神经网络:LeNet网络手写数字识别代码实践
LeNet-5详解及代码实现
LeNet是在1998年LeCuu等人提出来的,用于解决手写数字识别的视觉任务,被认为是卷积神经网络的开创性工作,是卷积神经网络的祖师爷,是深度学习领域的里程碑,自那时起,CNN的最基本的架构就定下来了:卷积层、池化层、全连接层。论文地址:Gradient-Based Learning Applied to Document Recognition
LeNet模型
LeNet5网络包含了深度学习的基本模块:卷积层,池化层,全连接层。
LeNet5共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征,然后每个FeatureMap有多个神经元。
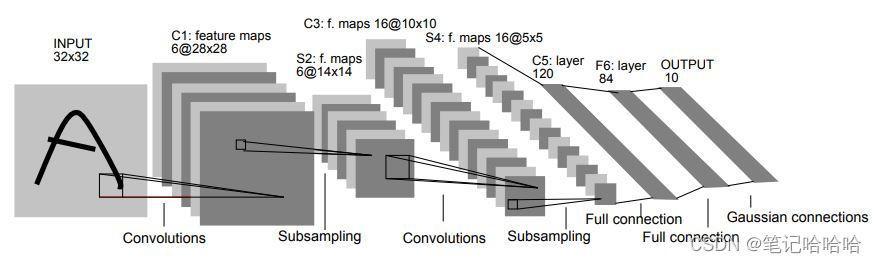
论文中用的数据集输入大小为单通道,32×32大小的图片。
本次实践采用MNIST 数据集,可在 http://yann.lecun.com/exdb/mnist/ 获取,也可以通过pytorch代码。MNIST数据集输入大小为单通道,28×28大小的图片。因此实践中的LeNet,特征图大小与论文不一致,如下表所示。
| 操作 | 论文的输出尺寸 | 实践的输出尺寸 |
|---|---|---|
| input | 1, 32, 32 | 1, 28, 28) |
| conv1 | 6, 28, 28 | 6, 24, 24) |
| pool1 | 6, 14, 14 | 6, 12, 12) |
| con | 16, 10, 10 | 16, 8, 8) |
| pool2 | 16, 5, 5 | 16, 4, 4 |
| fc1 | 120 | 120 |
| fc2 | 84 | 84 |
| fc3 | 10 | 10 |
Lenet的pytorch实现
实践加载的库
# 加载库
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torchsummary import summary
from PIL import Image
搭建LeNet-5网络
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# 卷积神经网络 # n.Sequential():一个序列容器,用于搭建神经网络的模块
# 调用forward()方法进行前向传播时,for循环按照顺序遍历nn.Sequential()中存储的网络模块
self.features = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1),
nn.Sigmoid(), # sigmoid()是论文中的激活函数,由于十几年后的计算机运算速度的加快,出现了更深的网络,
# sigmoid()激活函数引发了梯度消失和梯度爆炸,以及不同激活函数的优缺点与适用场景,出现了ReLu(),Leaky ReLU(),Tanh()等等激活函数
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2)
)
# 分类器
self.classifier = nn.Sequential(
nn.Linear(in_features=16 * 4 * 4, out_features=120),
nn.Linear(in_features=120, out_features=84),
nn.Linear(in_features=84, out_features=10)
)
def forward(self, x):
x = self.features(x)
# x = x.view(-1, 16 * 5 * 5)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
展示网络
mol = LeNet5().cuda() # 没安装cuda报错,删除.cuda() 也错? 是因为torchsummary.summary()的默认参数device='cuda',删除后要改为device='cpu'
print(mol) # 打印网络
summary(mol, input_size=(1, 28, 28)) # 默认参数device='cuda'。 device='cpu'
LeNet5(
(features): Sequential(
(0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(1): Sigmoid()
(2): AvgPool2d(kernel_size=2, stride=2, padding=0)
(3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(4): Sigmoid()
(5): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(classifier): Sequential(
(0): Linear(in_features=256, out_features=120, bias=True)
(1): Linear(in_features=120, out_features=84, bias=True)
(2): Linear(in_features=84, out_features=10, bias=True)
)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 24, 24] 156
Sigmoid-2 [-1, 6, 24, 24] 0
AvgPool2d-3 [-1, 6, 12, 12] 0
Conv2d-4 [-1, 16, 8, 8] 2,416
Sigmoid-5 [-1, 16, 8, 8] 0
AvgPool2d-6 [-1, 16, 4, 4] 0
Linear-7 [-1, 120] 30,840
Linear-8 [-1, 84] 10,164
Linear-9 [-1, 10] 850
================================================================
Total params: 44,426
Trainable params: 44,426
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.08
Params size (MB): 0.17
Estimated Total Size (MB): 0.25
----------------------------------------------------------------
加载数据集
使用pytorch进行学习时,可以使用pytorch的处理图像视频的torchvision工具集直接下载MNIST的训练和测试图片,torchvision包含了一些常用的数据集、模型和转换函数等等,比如图片分类、语义切分、目标识别、实例分割、关键点检测、视频分类等工具。train=True就是训练集,train=False不是训练集,即是测试集。若没下载设 download=True
# 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor())
训练网络
# 定义模型、损失函数和优化器
model = LeNet5()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# optimizer = optim.SGD(model.parameters(),lr=0.001,momentum=0.9) # 其他优化器
# 训练模型
loss_, accuracy_ = [], []
for epoch in range(10):
model.train()
print('Epoch:[{}/{}]'.format(epoch + 1, 10))
total_loss = 0
for i, data in enumerate(train_loader):
images, labels = data # 一个batch的数据
optimizer.zero_grad() # 梯度清零,初始化
outputs = model(images) # 前向传播
loss = loss_function(outputs, labels) # 计算误差
loss.backward() # 反向传播
optimizer.step() # 权重更新
total_loss += loss.item() # 损失累加
if (i + 1) % 100 == 0: # 每100次迭代查看一次结果
print('Iteration:[{}/{}], Loss: {:.4f}'.format(i + 1, len(train_loader), loss.item()))
loss_.append(total_loss)
# 测试模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Test Accuracy: {:.2f}%'.format(100 * correct / total))
accuracy_.append(100 * correct / total)
torch.save(model.state_dict(), 'model.pth') # 仅保存权重参数
# 打印损失值 精度变化曲线
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2)
ax1.plot(range(len(loss_)), loss_)
ax1.set_xlabel('epoch')
ax1.set_ylabel('total loss')
ax2.plot(range(len(accuracy_)), accuracy_)
ax2.set_xlabel('epoch')
ax2.set_ylabel('accuracy(%)')
plt.show()
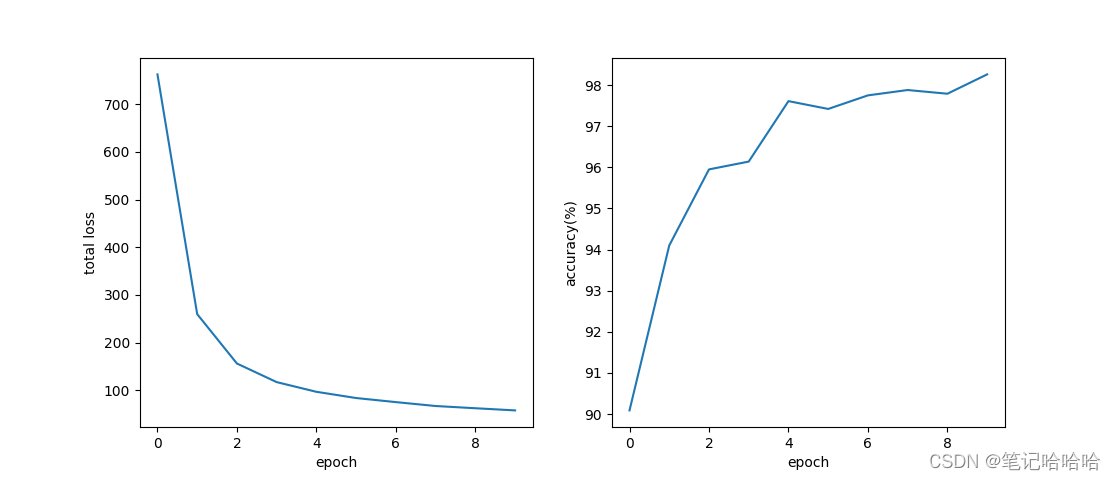
10次epoch训练结果如下
Test Accuracy: 98.26%
自己手写的数字处理


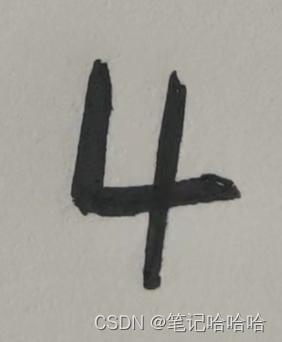
为什么”4“那么粗,因为前两个测试均错误,让我怀疑难道是写的太细了?后来加了个transforms.Normalize(0.5, 0.5)做数据归一化,细的数字才识别成功。我用微信拍照上传电脑,如上图,虽然裁剪了到图像依旧很大,几百×几百的像素,且是彩图,要依次做以下处理
# 测试自己的手写数字
five = Image.open('7.jpg')
img_gray = five.convert('L')
transform = transforms.Compose([ # 容器 会按照顺序依次处理
transforms.Resize((28, 28)), # 手机拍的尺寸太大,无法放进网络,要缩放到28×28
transforms.ToTensor(), # 会把数据压缩,归一化到(0,1)
transforms.RandomInvert(p=1), # 训练集是黑底,白字,需要反相,把自己写的也变成黑底白数字,概率设为p=1
transforms.Normalize(0.5, 0.5) # 数据已经是(0,1),使用公式"(x-mean=0.5)/(std=0.5)",将每个元素分布到(-1,1)
])
img = transform(img_gray) # 数据处理,此时图片为[C, H, W]
img = torch.unsqueeze(img, dim=0) # 在0位置展开一个维度为批次(batch)N,[N, C, H, W]
# 看一看结果
plt.subplot(121)
plt.imshow(img_gray, cmap='gray')
plt.xlabel('before')
plt.subplot(122)
plt.imshow(img.numpy()[0, 0, :, :], cmap='gray') # imshow()只能显示二维的,此时img是四维的
plt.xlabel('after')
plt.show()



测试自己手写的数字
没有设置随机种子,训练的结果,网络参数各不一样
model = LeNet5()
weight = torch.load('model.pth') # 加载保存的参数
model.load_state_dict(weight) # 给网络模型按照文件weight,设置权重参数
with torch.no_grad():
outputs = model(img)
re = outputs.data
print(re) # 输出结果
print(torch.max(outputs.data, 1))
_, predict = torch.max(outputs.data, 1) # 找到最大值的位置,即是识别结果
print(predict)
print('识别结果:', predict.item())
最终结果
7 输出
tensor([[-14.5138, 14.1604, 10.1955, -4.1804, 4.6772, -1.3008, -16.3280,
16.3169, -17.2751, 0.0612]])
torch.return_types.max(
values=tensor([16.3169]),
indices=tensor([7]))
tensor([7])
识别结果: 7
tensor([7]) 是7 识别正确
5 输出
tensor([[ -8.7777, 4.6533, 11.0276, -2.3891, -1.6845, 2.8539, -11.4988,
10.2582, -11.5190, 0.3073]])
torch.return_types.max(
values=tensor([11.0276]),
indices=tensor([2]))
tensor([2])
识别结果: 2
tensor([2]) 是2 识别错误
4 输出
tensor([[-10.5092, 0.3667, 2.4670, -8.9335, 23.4923, -8.2030, -0.8113,
8.0965, -12.7255, 2.3728]])
torch.return_types.max(
values=tensor([23.4923]),
indices=tensor([4]))
tensor([4])
识别结果: 4
tensor([4]) 是4 识别正确
完整代码
# 加载库
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torchsummary import summary
from PIL import Image
# 定义LeNet-5模型
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# 卷积神经网络 # n.Sequential():一个序列容器,用于搭建神经网络的模块
# 调用forward()方法进行前向传播时,for循环按照顺序遍历nn.Sequential()中存储的网络模块
self.features = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1),
nn.Sigmoid(), # sigmoid()是论文中的激活函数,由于十几年后的计算机运算速度的加快,出现了更深的网络,
# sigmoid()激活函数引发了梯度消失和梯度爆炸,以及不同激活函数的优缺点与适用场景,出现了ReLu(),Leaky ReLU(),Tanh()等等激活函数
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2)
)
# 分类器
self.classifier = nn.Sequential(
nn.Linear(in_features=16 * 4 * 4, out_features=120),
nn.Linear(in_features=120, out_features=84),
nn.Linear(in_features=84, out_features=10)
)
def forward(self, x):
x = self.features(x)
# x = x.view(-1, 16 * 5 * 5)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
mol = LeNet5().cuda() # 没安装cuda报错,删除.cuda() 也错? 是因为torchsummary.summary()的默认参数device='cuda',删除后要改为device='cpu'
print(mol) # 打印网络
summary(mol, input_size=(1, 28, 28)) # 默认参数device='cuda'。 device='cpu'
# 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor())
# 定义数据加载器
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
# 定义模型、损失函数和优化器
model = LeNet5()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# optimizer = optim.SGD(model.parameters(),lr=0.001,momentum=0.9) # 其他优化器
# 训练模型
loss_, accuracy_ = [], []
for epoch in range(10):
model.train()
print('Epoch:[{}/{}]'.format(epoch + 1, 10))
total_loss = 0
for i, data in enumerate(train_loader):
images, labels = data # 一个batch的数据
optimizer.zero_grad() # 梯度清零,初始化
outputs = model(images) # 前向传播
loss = loss_function(outputs, labels) # 计算误差
loss.backward() # 反向传播
optimizer.step() # 权重更新
total_loss += loss.item() # 损失累加
if (i + 1) % 100 == 0: # 每100次迭代查看一次结果
print('Iteration:[{}/{}], Loss: {:.4f}'.format(i + 1, len(train_loader), loss.item()))
loss_.append(total_loss)
# 测试模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Test Accuracy: {:.2f}%'.format(100 * correct / total))
accuracy_.append(100 * correct / total)
torch.save(model.state_dict(), 'model.pth') # 仅保存权重参数
# 打印损失值 精度变化曲线
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2)
ax1.plot(range(len(loss_)), loss_)
ax1.set_xlabel('epoch')
ax1.set_ylabel('total loss')
ax2.plot(range(len(accuracy_)), accuracy_)
ax2.set_xlabel('epoch')
ax2.set_ylabel('accuracy(%)')
plt.show()
model = LeNet5()
weight = torch.load('model.pth') # 加载保存的参数
model.load_state_dict(weight) # 给网络模型按照文件weight,设置权重参数
# 测试自己的手写数字
five = Image.open('4.jpg')
img_gray = five.convert('L')
transform = transforms.Compose([ # 容器 会按照顺序依次处理
transforms.Resize((28, 28)), # 手机拍的尺寸太大,无法放进网络,要缩放到28×28
transforms.ToTensor(), # 会把数据压缩,归一化到(0,1)
transforms.RandomInvert(p=1), # 训练集是黑底,白字,需要反相,把自己写的也变成黑底白数字,概率设为p=1
transforms.Normalize(0.5, 0.5) # 数据已经是(0,1),使用公式"(x-mean=0.5)/(std=0.5)",将每个元素分布到(-1,1)
])
img = transform(img_gray) # 数据处理,此时图片为[C, H, W]
img = torch.unsqueeze(img, dim=0) # 在0位置展开一个维度为批次(batch)N,[N, C, H, W]
plt.subplot(121)
plt.imshow(img_gray, cmap='gray')
plt.xlabel('before')
plt.subplot(122)
plt.imshow(img.numpy()[0, 0, :, :], cmap='gray') # imshow()只能显示二维的,此时img是四维的
plt.xlabel('after')
plt.show()
with torch.no_grad():
outputs = model(img)
re = outputs.data
print(re) # 输出结果
print(torch.max(outputs.data, 1))
_, predict = torch.max(outputs.data, 1) # 找到最大值的位置,即是识别结果
print(predict)
print('识别结果:', predict.item())