评分卡实例:一步一步实现评分卡(详细长文)
老饼讲解-机器学习 https://www.bbbdata.com/ml/scorecard
https://www.bbbdata.com/ml/scorecard
目录
本文以kaggle上的借贷数据:https://www.kaggle.com/c/GiveMeSomeCredit/data 为例,讲解《建立评分卡模型的全过程》。
本文只讲解流程,完整代码见《评分卡实例:完整建模代码》
备注:1、因为详细,代码略长,可只参考自己仅需要的部分。
2、数据需要墙,如无法获取,请留邮箱
本文的流程是完整的,详细的,具体的,可以一步步跟着执行。由于文字上比较浓缩, 需要花些耐心。
特别告知:《评分卡系列》文章在本人网站作了更完善更全面的更新,由于改动过大,本文不再更新。一切以老饼的知识网站为主。
(前一) 数据说明
数据共包含10个变量与客户好坏标签:
| 变量名 | 变量描述 | 数据类型 |
|---|---|---|
| SeriousDlqin2yrs | 是否有超过90天或更长时间逾期未还的不良行为 | 二分类(0为好,1为坏) |
| RevolvingUtilizationOfUnsecuredLines | 信用卡和个人信用额度的总余额(除房地产以及分期付款债务(如汽车贷款))除以总信贷限额。 | 定量 |
| age | 借贷者的年龄 | 定量 |
| NumberOfTime30-59DaysPastDueNotWorse | 借款者逾期30至59天的次数(过去两年中没有恶化) | 定量 |
| DebtRatio | 月债务支出、赡养费、生活费除以总收入(负债比率) | 定量 |
| MonthlyIncome | 月收入 | 定量 |
| NumberOfOpenCreditLinesAndLoans | 公开贷款(如汽车和抵押的分期)和信用上线(比如信用卡)数量 | 定量 |
| NumberOfTimes90DaysLate | 90天逾期次数:借款者有90天或更高逾期的次数 | 定量 |
| NumberRealEstateLoansOrLines | 抵押和房地产数量(包括房屋净值信用额度) | 定量 |
| NumberOfTime60-89DaysPastDueNotWorse | 借款者逾期30至59天的次数(过去两年中没有恶化) | 定量 |
| NumberOfDependents | 家庭受抚养人数(不含自己) | 定量 |
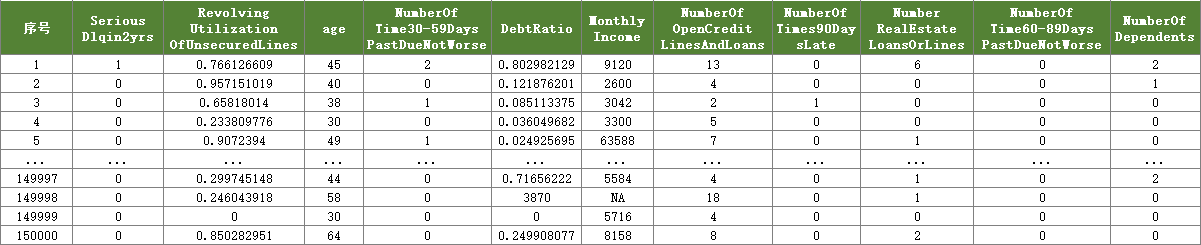
数据共15万条,如下
(前言二) 评分卡建模步骤概述
评分卡的目标模型是,依据客户数据(10个变量),预测客户是否坏客户(数据中的SeriousDlqin2yrs变量).
整个建模过程共5步:
1.变量分析与分箱:筛选与标签SeriousDlqin2yrs有相关性的变量,并把变量进行分箱,作为建模的输入特征。
2.建模
(1)数据预处理:转woe,归一化
(2)用逐步回归选出尽量少的特征(同时保持建模效果)
(3)训练逻辑回归模型
3.模型评估:检验AUC是否达标,并检查系数是否都为正。
4.将逻辑回归模型预测结果转为评分
5.确定生产上的判定为坏客户的分数阈值
一.变量分析、选择与分箱处理
(一) 使用badRate法(或iv法)分析变量
本阶段分析和挑选变量,一般使用badRate法(或iv法)分析哪些变量与客户的质量相关,作为入模变量。
完整分析流程与变量初探结果见:
这里挑选部分讲解如下:
1.badRate法分析过程简介
(1) 筛选出所有与badRate相关的变量,
(2) 精细化分箱
备注:(1)和(2)是反复进行的,一边分箱,一边确定要不要该变量。
2.例子
(1) 先粗略分箱,试探变量的badRate,如RevolvingUtilizationOfUnsecuredLines变量
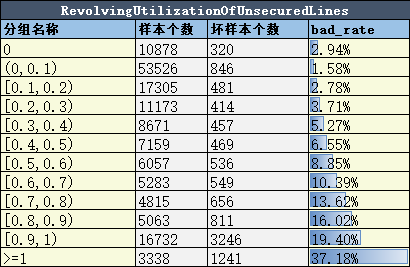
(2)如果变量的badRate有一定的趋势,就进一步对变量仔细分箱
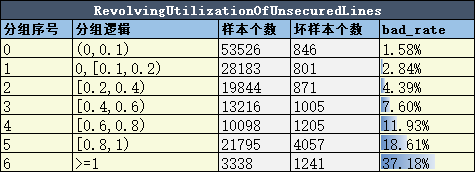
在本例中,所有变量与badRate都有明显的关系。因此以上10个变量都被选择用于建模。
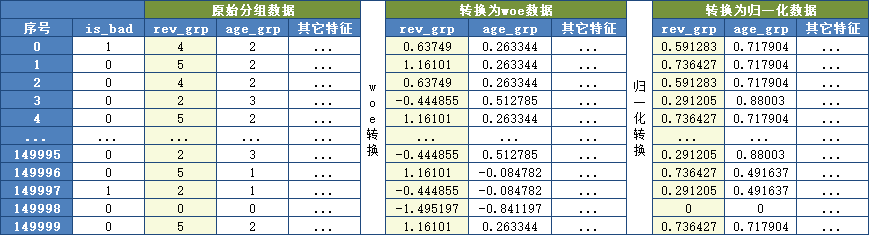
(二) 原始数据转为分箱数据
最后,将原始数据转为分箱数据,如下:
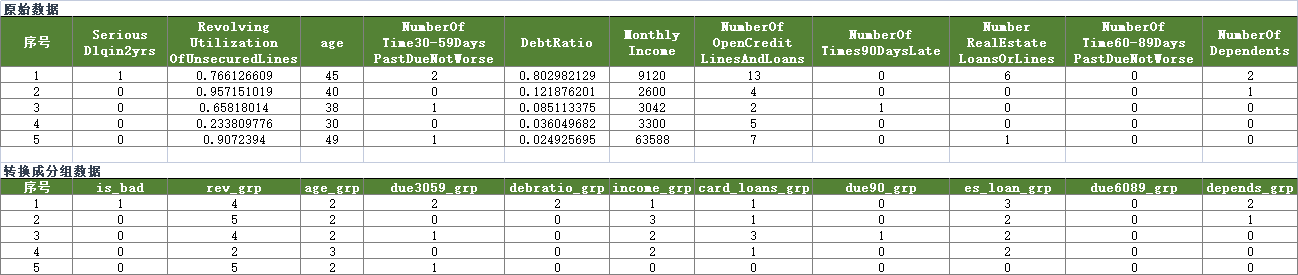
由于原变量名过长,换成新的变量名:
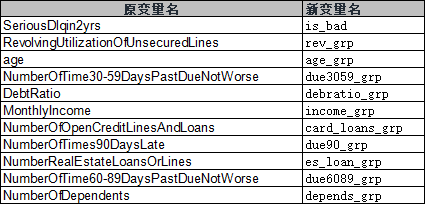
完整结果见:《评分卡实例:变量分析-变量分箱》
二.模型数据预处理
预处理时,将原数据映射成组号,如果直接把组号作为特征变量值,不够理想,组号是等距的,而badrate是不等距的。一般需先将组号转为WOE
WOE的意义与推导可见:《评分卡-WOE的意义与推导》
(一) 转WOE
(1) 计算每个特征每个分组的WOE(特征WOE映射表):
即将变量X第i组的输入转为
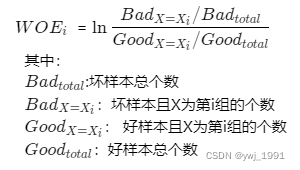
(2) 将分组转换为WOE
(3) 举例说明
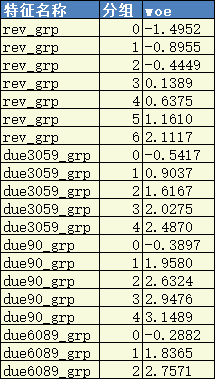
特征 rev_grp 计算得到的每组对应的WOE:

将rev_grp的分组数据转换成分组对应的woe数据:
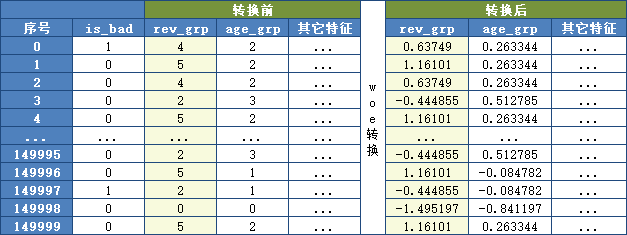
备注:有些人在分箱时,只作分箱,而不按badRate大小重新调整分组,即badRate不随序号增加而增加,这时,作 WOE转换可解决此问题。
(二) 归一化
为了让模型求解更优秀,逻辑回归需要将数据归一化。
(1) 归一化公式
归一化直接使用如下公式对数据缩放到[0,1]即可:
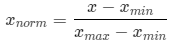
(2) 举例说明
特征rev_grp 归一化前的最大值为:2.11168472653793,最小值为:-1.49519682401574,则对rev_grp统一作归一化如下:
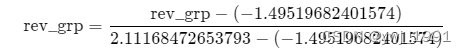
(三) 总结
总的来说,由分组数据-->woe数据-->归一化数据,如下:
三.模型变量筛选与建立逻辑回归模型
(一)逐步回归选择尽量少的变量建模
逻辑回归过拟合原因主要来源于变量多重共线性,为避免模型过拟合,我们通过逐步回归,在保障模型效果的同时,选择尽量少的变量参与模型。
逐步回归流程:
1.历遍所有变量,将单个变量与目标建模,把模型结果最好的变量作为第一轮选择变量。
2.在第一轮选择变量的基础上,添加第二个变量,历遍剩余变量,添加哪个变量能令模型结果最好,就将其作为第二轮选择变量。
3.在第二轮的基础上,添加第三个变量......
......
直到变量不再对模型效果果带来明显贡献时,就不再添加变量。
则选出的变量,就是变量池中,最具代表的变量。这样既保障了模型的效果,又尽量减少变量的个数。
代码结果:
===========逐回步归过程===============
本轮最佳AUC: 0.7797686643130279 ,本轮最佳变量: rev_grp
本轮最佳AUC: 0.819165147896963 ,本轮最佳变量: due3059_grp
本轮最佳AUC: 0.8410814099324723 ,本轮最佳变量: due90_grp
本轮最佳AUC: 0.8485557426525118 ,本轮最佳变量: due6089_grp
本轮最佳AUC: 0.8523064156957751 ,本轮最佳变量: debratio_grp ,效果不明显,不再添加变量
最终选用变量 4 个: Index(['rev_grp', 'due3059_grp', 'due90_grp', 'due6089_grp'], dtype='object')可以看到,在加入第5个变量,deratio_grp时,AUC增长并不明显,则可以停止添加变量。只使用前4轮挑出的变量:rev_grp,due3059_grp,due90_grp,due6089_grp
(二)用选出的变量建立逻辑回归
将选出的变量,放到逻辑回归模型中建模,即得到最终的模型。
逻辑回归模型训练较为简单,可调参数也较少,在这一步直接调用模型进行训练即可。
备注:训练时, sklearn默认加入L2正则项,训练时可先将penalty选项设为'none'(即不加入正则项),如果最后训练系数不满意,再改回'l2'训练。
训练完成,即可得到各个特征的权重w和阈值b:
=========模型参数==========
模型系数(对应原始数据): [0.68737659 0.50670396 0.52947426 0.3666265 ]
模型阈值(对应原始数据): -2.5927673435722016四.模型评估
(一) 用AUC评估
模型的效果评估一般是使用AUC。
PASS:为什么使用AUC,而不是准确率?因为模型预测的是概率,判断最终是好坏,还需要引入阈值(大于阈值,判为坏,小于阈值,判断为好),阈值不同,准确率也不同。而AUC则是所有阈值的准确率的综合评估。
计算模型的AUC,AUC值的意义如下:
AUC>0.63:模型对y有区分度(不可投产)。
AUC>0.68:有效益(不可投产)
AUC>0.73:模型才算优秀(可投产)。
(二) 检验系数是否为正数
除了评估AUC,还需要检验模型是否符合业务逻辑。
由于经过WOE转换,所有特征与badRate都是正相关,因此,系数应都为正数。
如果为负数,需要检验模型哪里出了问题。
五.模型输出(转评分)
(一) 模型输出与应用(概率预测)
上面模型得到的是概率的预测,如果生产上要应用概率模型,则如下输出
1.模型输出
共由三部分组成:
(1) 模型变量:
(2)WOE对应表:由于建模用的是WOE值,需要把分组转换成WOE。
(3)系数w,b
如下:
(1) 模型变量(model_feture):rev_grp,due3059_grp,due90_grp,due6089_grp
(2) WOE对应表:
(3)模型系数:

2.模型应用
预测时:
1.先通过客户特征数据,判断客户各个特征属于哪一组。
2.通过分组,查询WOE表,获得特征的WOE值。
3.根据模型公式,即可计算属于坏客户的概率。
(二) 模型输出与应用(转为客户评分)
评分卡,实际输出的是评分。因此一般是以评分模型作为输出,需要把模型转换成分数输出。
即:
![]()
整理后可得:
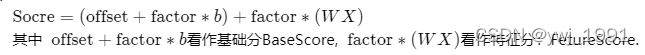
备注:评分卡不使用概率转换分数,而是用线性部分转换成分数,这样做的好处是,每一个特征x的分数和就是总分,而如果用概率转分,则单个特征增加s分,总分并不增加s分。
1.将概率模型转换为评分模型
(1) 设置 init_socre,init_odds,delta_score,delta_rate
一般设为:
init_socre = 600
init_odds = 50
delta_score = 20
delta_rate = 2
意思是,
当 odds(坏账概率:不坏账概率) = 50:1时,分数为600.
odds每降低2倍(例如从50:1降为25:1),分数提高20分。
(2) 计算模型的基础分和每个特征每个分组的评分。
先用公式计算offset和factor。
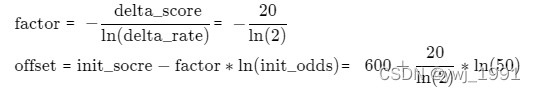
计算基础分与特征得分:

公式的推导可阅读:《评分卡-分数转换与推导》
2.最终评分模型输出
(1) 模型变量:模型使用的变量。
(2) 基础分
(3) 特征评分表:每个特征每个分组对应的评分。
如下:
(1) 模型变量(model_feture):rev_grp,due3059_grp,due90_grp,due6089_grp
(2) 基础分(BaseScore):692.8771237954945
(3) 特征评分表:
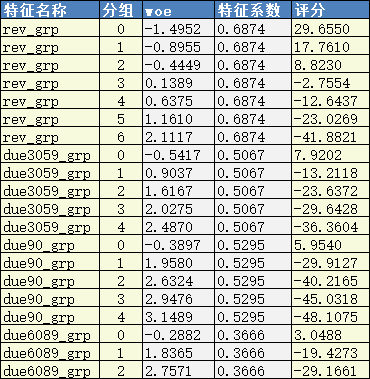
备注:(1)生产上往往将所有分数都取整。
(2)实际交付生产时还需要把特征分组逻辑一起交付
3.模型应用
模型应用时,即对客户评分,如下使用:
(1)先通过客户特征数据,判断客户各个特征属于哪一组。
(2)通过特征所在分组,查询特征评分表,获取各个特征的评分。
(3)计算总分:总分=各特征评分+基础分。
六、模型阈值表与投产阈值
模型投产时,需要确定一个评分阈值,将低于评分阈值的客户拒绝。
(一) 模型阈值效果表
为了结合业务,确定阈值,一般统计阈值效果表。阈值表展示用不同评分阈值,模型在业务带来的效果。
阈值效果表的统计字段如下:
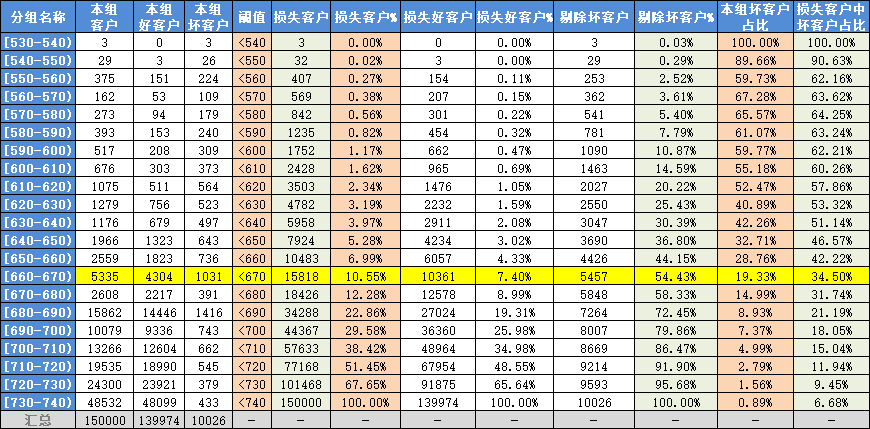
(二) 通过阈值表确定阈值
以评分分组在 [660-670) 为例:
(1) 先查看《本组坏客户占比》确定阈值上限
该字段说明[660-670)分的客户有5335个,其中坏客户1031个,占比19.33%。说明该组大概切掉5个客户,会有一个是坏的,
先在这一列找到效益均衡点,例如,放款4个好客户的收益,才能抵掉一个坏客户的损失,说明19.33%这一分数是均衡点,阈值不能比670更大,否则损失大于收益。
(2) 再看《损失的客户%》确定阈值。
如阈值取<670,则损失 10.55%客户(15818个),如果损失客户过多,业务上不能接受,则阈值取更小。
(3) 最后评估综合信息.
损失的客户%:10.55%(15818个)
损失客户中坏客户占比:34.5%
剔除坏客户%:54.43%
即使用<670作为阈值,则会损失10.55%的左右,这部分客户里有34.5%是坏客户。使用模型后,坏客户能减少54.43%
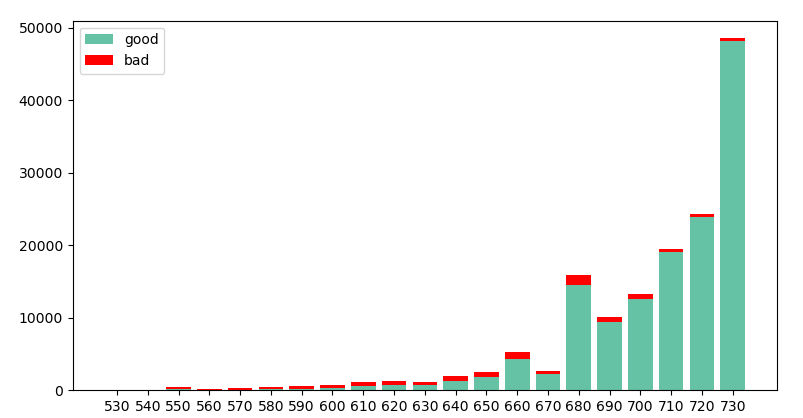
(三) 分数分布图
最后的最后,画出分数布,进一步了解模型。
(实际生产中,分数分布图一般为正态分布)
相关文章