YoLo V1详解
YoLo系列都是在V1的基础上进行改进的,所以学好YoLo V1至关重要
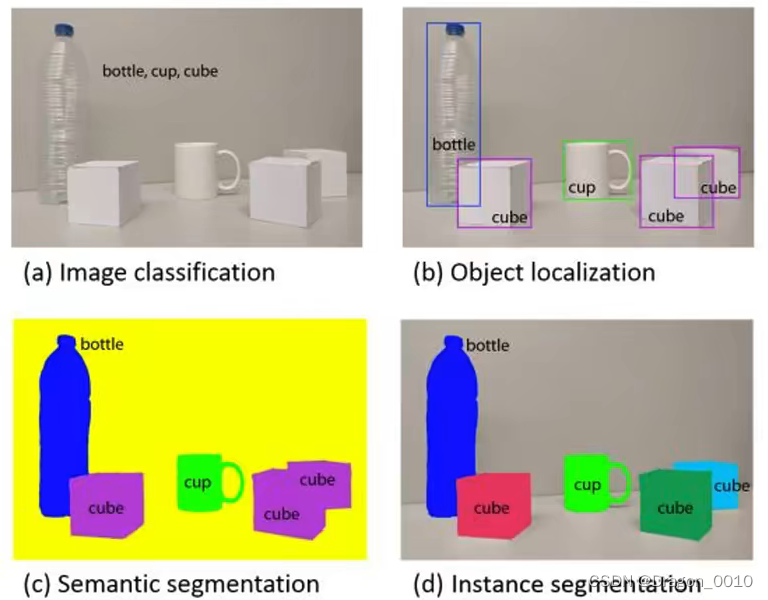
图像分类、目标检测、图像分割(将目标以抠图的形式标记出来)
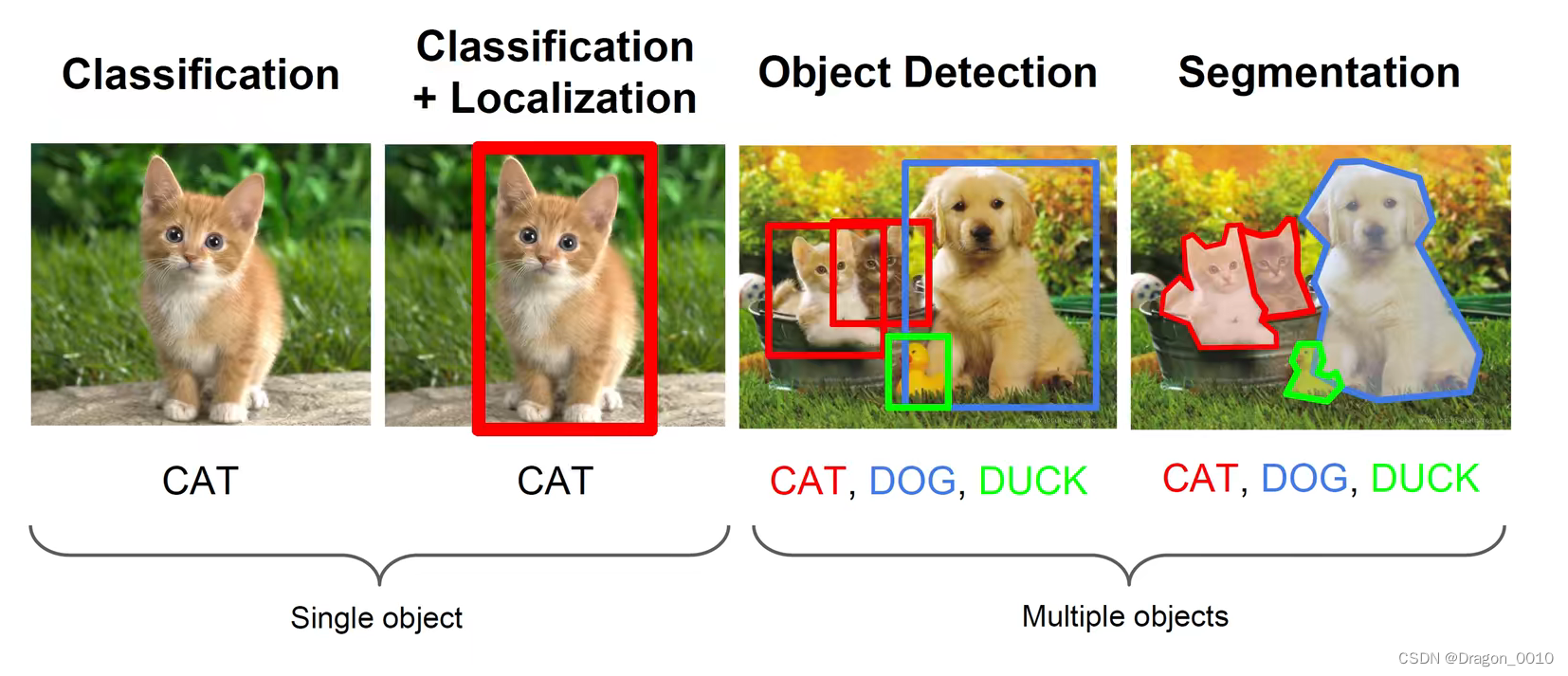
图像分割又分为Semantic Segmentation(语义分割)和Instance Segmentation(实例分割)

语义分割就是对每一个像素分类,不管这个像素是属于哪几个物体的,只管它是属于什么类别的
实例分割就是把同一个类别的不同实例给它区分出来
论文思想:
1.将一幅图像分成7*7个网格,如果某个目标的中心(GTBOX的中心)落在这个网格,则这个网格就负责预测这个目标
2.每个网格要预测2个bounding BOX,每个bounding box除了要预测位置之外(x,y,w,h)还要附带预测一个confidence(置信度,预测目标与真实目标的交并比乘以0或1,网格中有目标就乘以1,没有目标就乘以0),每个网格还要预测C(voc取20)个类别的分数
预测阶段(前向推断)
预测就是在模型已经训练完成之后,输入未知图片来对模型进行测试。
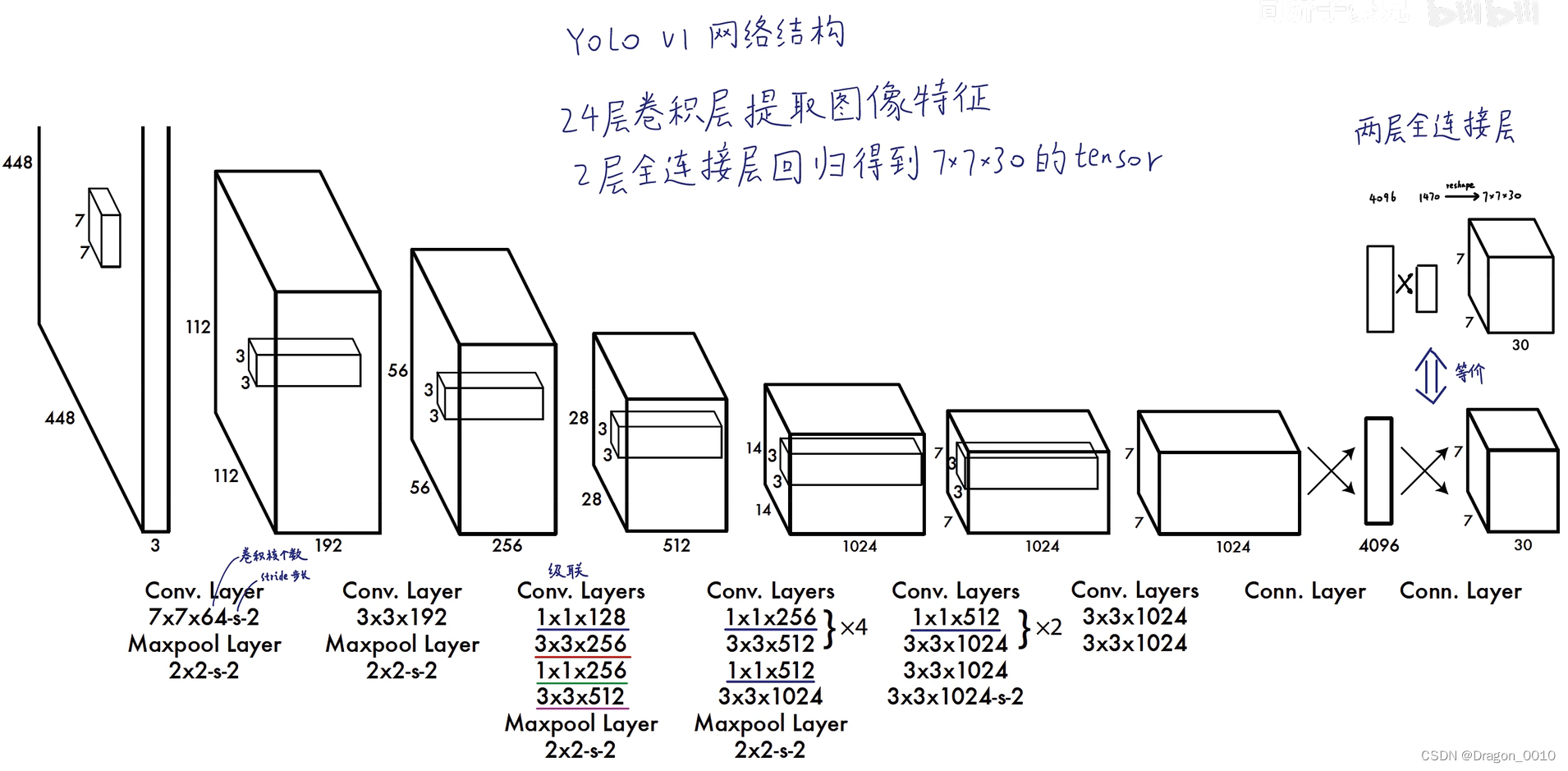
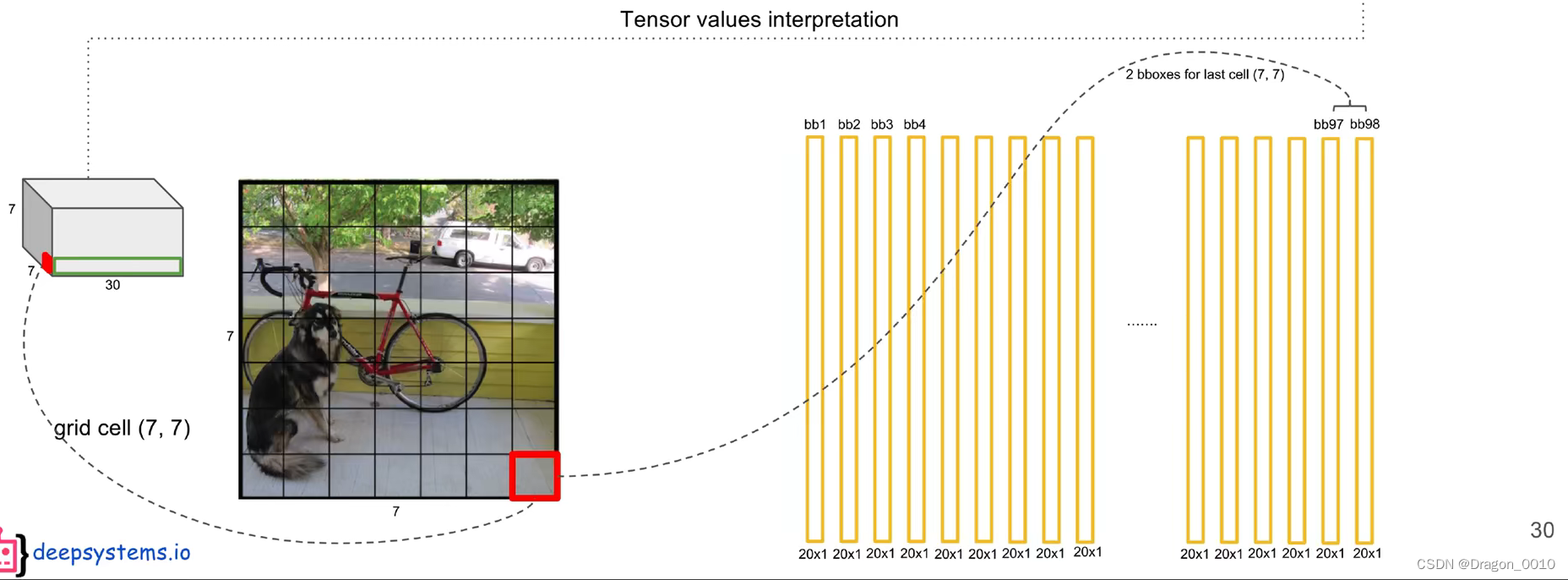
yolo v1输入的是448*448*3的图像,输出的是7*7*30的张量,这个张量里面包含置信度,坐标,只需要对这个张量的信息进行解读。
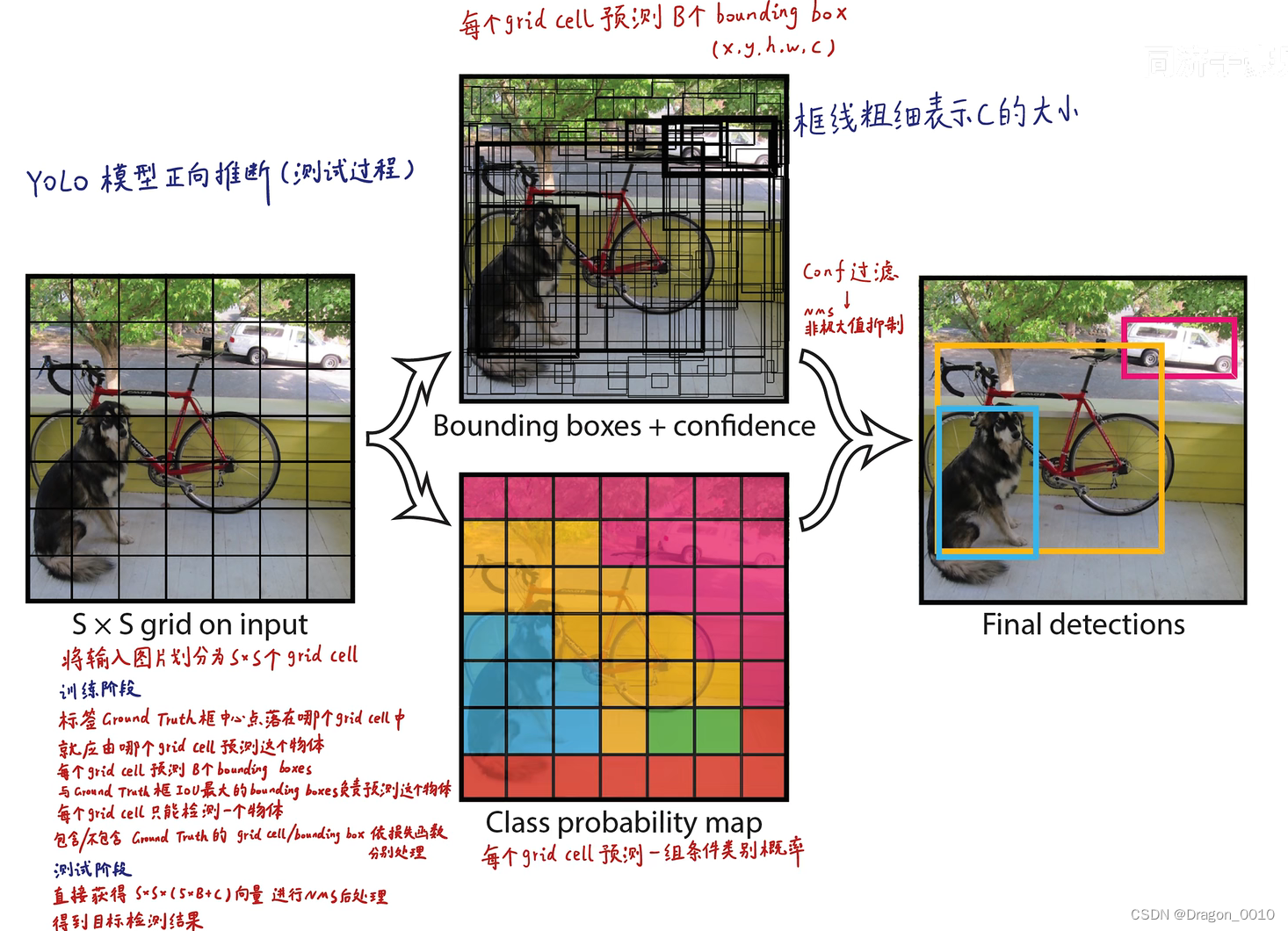
首先将图片分为7*7的网格,每一个网格都有2个预测框,这两个预测框的中心点都落在网格里面。预测框就包含x,y,w,h(框中心点的坐标x,y以及框的宽高w,h),有这4个坐标就可以确定框的位置。以及包含它是不是一个物体的置信度(置信度用来判断边界框内的物体是正样本还是负样本,大于置信度阈值的判定为正样本,小于置信度阈值的判定为负样本即背景。),图中的置信度就以框线的粗细来表示。粗线表示置信度比较高,细线就表示置信度比较低。

每一个网格还能生成每一个类别的条件概率,将每一个预测框的置信度乘以类别的条件概率就能够获得每一个预测框的各类别的概率。

结合这两个信息就可以获得最终的结果。这些信息来源与7*7*30的张量中获取的。
完整的过程:

7*7*30中的30是怎么来的呢?
每个网格包含2个预测框,每个预测框有5个参数(x,y,w,h,confidence value置信度)
2个框就是10个参数
Pascal VOC里面包含20个类别

5*2+20=30
yolo v1对小目标或者密集目标预测性能较差
预测阶段 后处理(置信度过滤,非极大值抑制)
对于yolo而言,后处理就是将纷繁复杂的预测出来的98(49*2)个预测框进行筛选、过滤,把重复的预测框只保留一个,最终获得目标检测的结果(NMS)。
NMS:
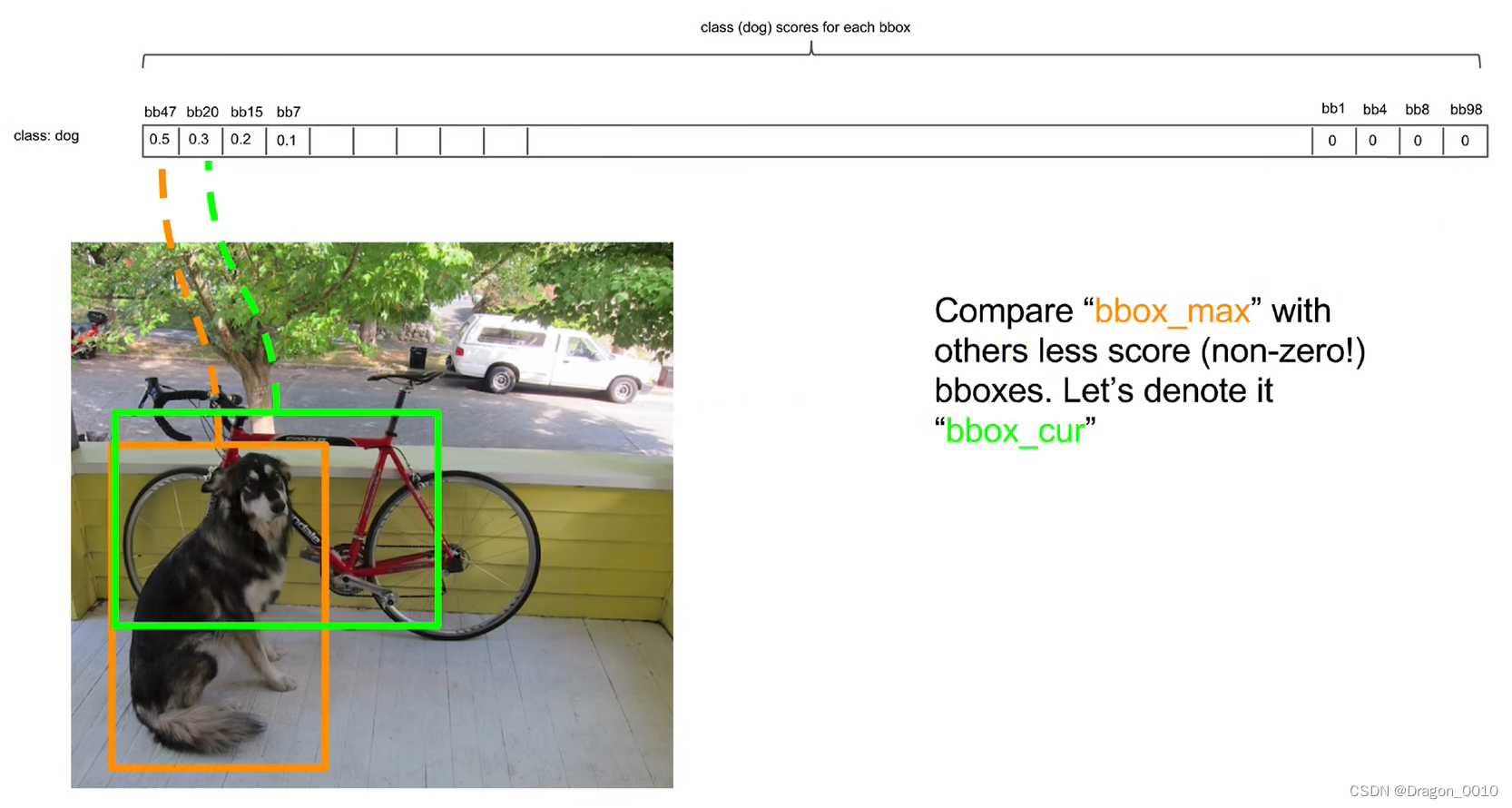
先把最高的拿出来,然后再将每一个都跟最高的作比较。
先将第一个和第二个作比较,如果他俩的lou大于某个阈值,那我们就认为他俩是重复识别了同一个物体,那我们就把低概率的给过滤掉。如果lou阈值设置的很低,那么框与框之间就不会有交集,如果阈值设置的很高,那么同一个物体就会有很多预测框。
最后只留下一个概率最高的检测框
训练阶段(反向传播)
深度学习或者监督学习(监督学习(supervised learning)擅长在“给定输入特征”的情况下预测标签。 每个“特征-标签”对都称为一个样本(example)。 有时,即使标签是未知的,样本也可以指代输入特征。 我们的目标是生成一个模型,能够将任何输入特征映射到标签,即预测。)
是通过梯度下降和反向传播方法跌打的去微调神经元中的权重。来使得损失函数最小化的过程。目标检测是一个典型的监督学习问题。就是说,在训练集上,肯定已经人工标注出来了一个绿框(Ground Truth),而我们的算法就是让这个预测结果尽量去拟合这个绿框。
而这个绿框的中心点落在哪个网格里面,就应该由哪个网格预测出的Bounding Box去负责拟合这个绿框。每个网格有2个Bounding Box,应该由这2个Bounding Box中的一个(与Ground Truth交并比比较大的)去拟合这个绿框。并且这个网格输出的类别也应该是Ground Truth的类别。
YoLo V1损失函数
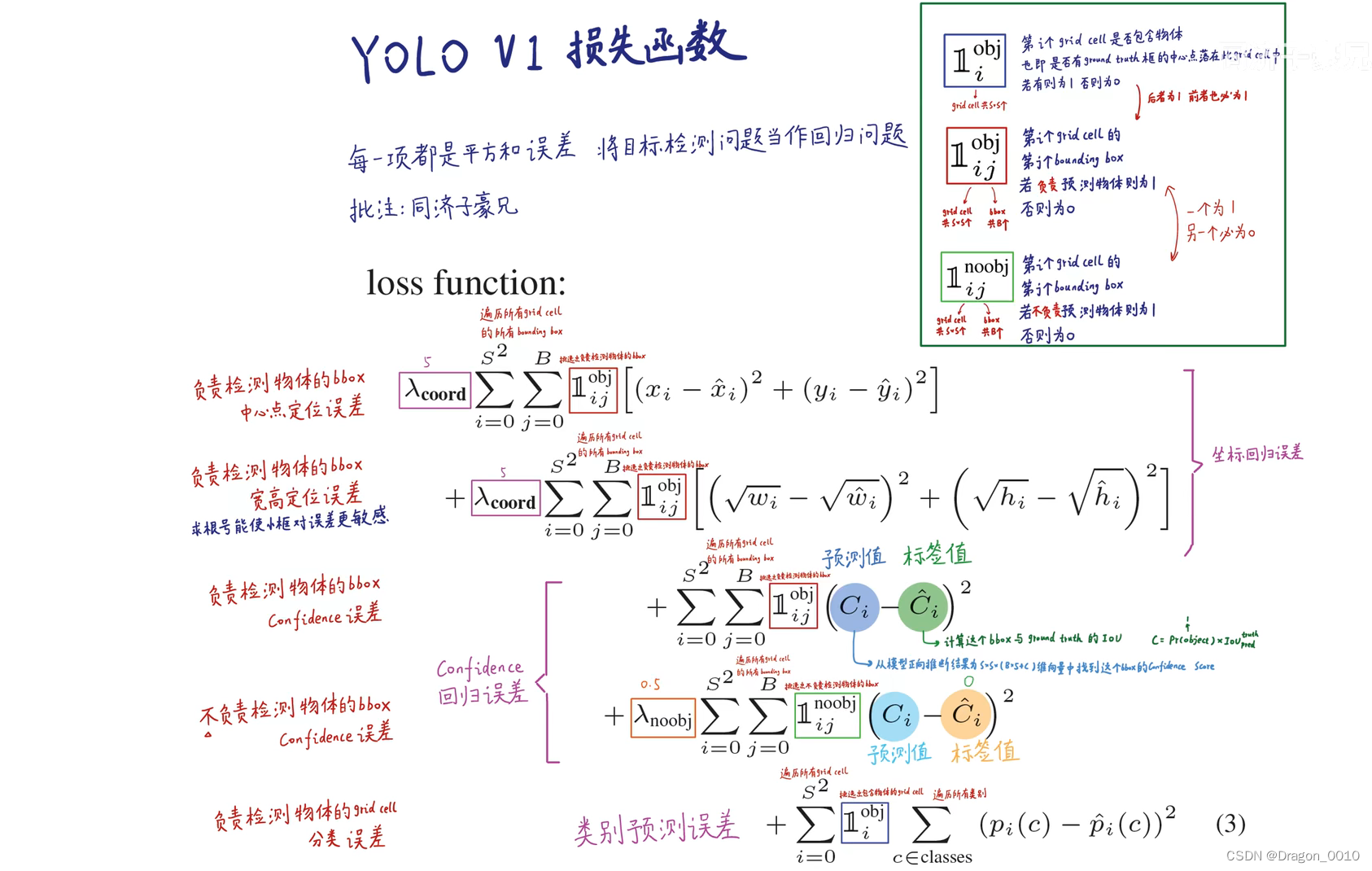
这个损失函数包含5项:
第1项是负责检测物体的Bounding Box的中心点定位误差。BBox要和GT从x,y,w,h上都要尽可能的一致。
回归问题就是要预测出一个连续的值,把这个值与标注值进行比较,越接近越好。
yolo是把目标检测问题当作回归问题解决的。
第2项是负责检测物体的BBox的宽高定位误差。加根号是使得小框对误差更敏感。同样的偏差,小框造成的损失函数会更大,大框造成的损失函数会更小。这样对大框更加的公平。
第3项是负责检测物体的BBox的Confidence(置信度)误差
第4项是不负责检测物体的BBox的Confidence(置信度)误差。一种是不负责检测物体的BBox,一种是检测物体但是被淘汰的BBox。他们的置信度越接近于0越好
第5项时负责检测物体的网格的分类误差。