Apache Paimon 介绍
从 Flink Table Store 演进而来
Flink table store
架构如下图: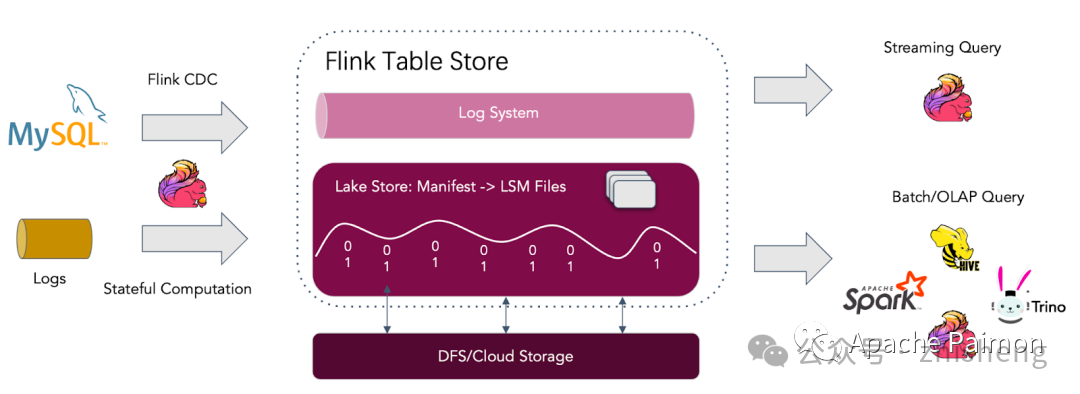
(和今天 Paimon 的架构相比,Log System 不再被推荐使用,Lake Store 的能力大幅强于 Log System,除了延时)
2021 年 9 月,发布了 0.2 版本,陆续有在生产使用。
Flink Table Store 是一个数据湖存储,用于实时流式 Changelog 写入 (比如来自 Flink CDC 的数据) 和高性能查询。它创新性的结合湖存储和 LSM 结构,深度对接 Flink,提供实时更新的系统设计,支撑大吞吐量的更新数据摄取,同时提供良好的查询性能。
0.3 形成了一个 Streaming Lakehouse 的基本雏形,我们可以比较自信的说出,0.3 可以推荐生产可用了。
基于 Flink Table Store 不仅可以支持数据实时入湖,而且支持 Partial Update 等功能,帮助用户更灵活的在延迟和成本之间做均衡。
Apache Paimon
在发布了三个版本后,虽然 Flink Table Store 具备了一定的成熟度,但作为 Flink 社区的一个子项目,在生态发展(比如 Spark 用户选择和使用)方面存在比较明显的局限性。为了让 Flink Table Store 能够有更大的发展空间和生态体系, Flink PMC 经过讨论决定将其捐赠 ASF 进行独立孵化。
2023 年 3 月 12 日,Flink Table Store 项目顺利通过投票,正式进入 Apache 软件基金会 (ASF) 的孵化器,改名为 Apache Paimon (incubating)。
进入孵化器后,Paimon 得到了众多的关注,包括 阿里云、字节跳动、Bilibili、汽车之家、蚂蚁 等多家公司参与到 Apache Paimon 的贡献,也得到了广大用户的使用。
Paimon 和 Flink 集成也在继续,Paimon 集成了 Flink CDC,提出了全自动的 数据 + Schema 的同步,整库同步,带来更高性能的入湖、更低的入湖成本、更方便的入湖体验。
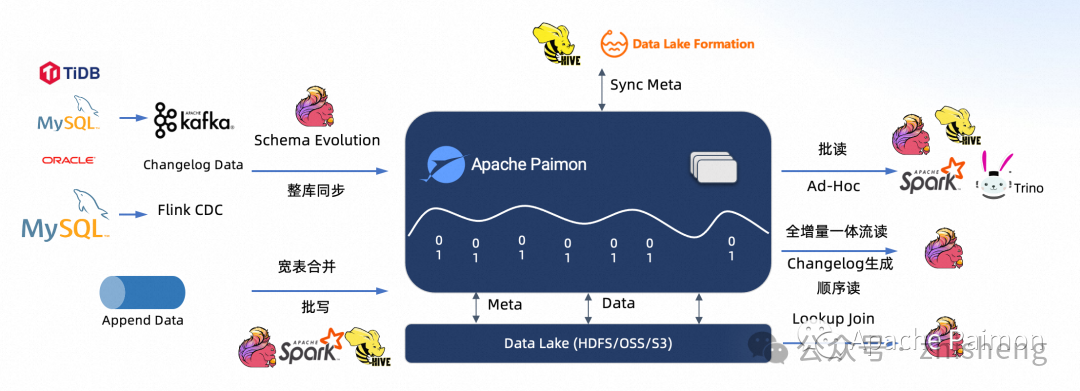
解决问题:
1、Paimon 实时 CDC 入湖
2、Paimon 实时宽表与流读
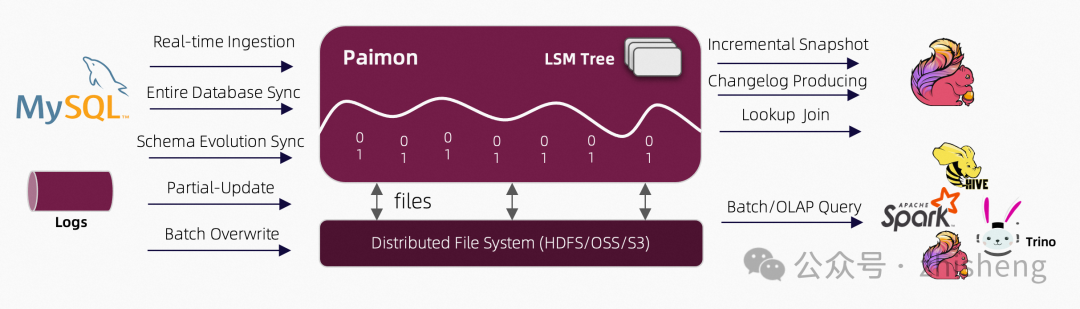
Apache Paimon 架构:
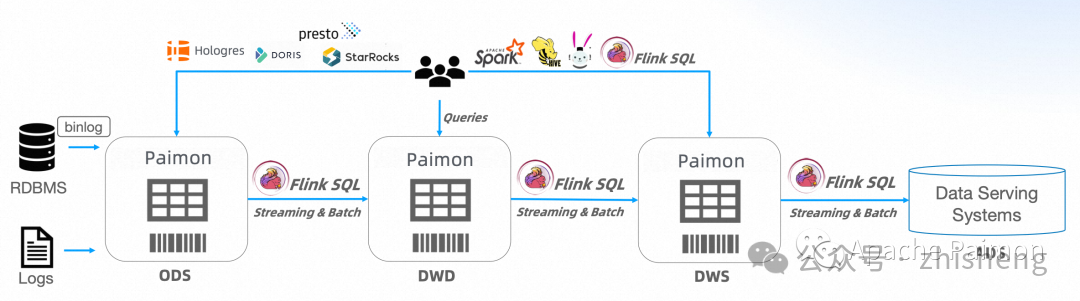
Streaming Lakehouse 架构:
1、数据全链路实时流动,同时沉淀所有数据,提供 AD-HOC 查询
2、通用的离线数据实时化,流批融合的一套数仓
参考资料: