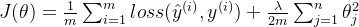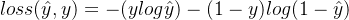【机器学习】正则化
正则化是防止模型过拟合的方法,它通过对模型的权重进行约束来控制模型的复杂度。
正则化在损失函数中引入模型复杂度指标,利用给W加权值,弱化了数据的噪声,一般不正则化b。
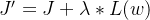
- loss(y^,y):模型中所有参数的损失函数,如交叉熵
- Regularizer:用超参数Regularizer给出w在总loss中的比例,即正则化的权重。
- w:需要正则化的参数
正则化分为L1正则化和L2正则化:
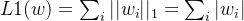
L1正则化大概率会使很多参数变为0,因此该方法可通过稀疏参数,即减少参数的数量,降低复杂度。
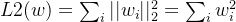
L2正则化会使参数很接近但不为零,因此该方法可通过减小参数值的大小降低复杂度。
来源推导
对于模型权重系数 w 求解是通过最小化目标函数实现的,即求解:
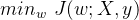
使用
假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,并且让代价函数最优化的程序来选择这些惩罚的程度。记:
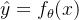
对线性回归:
![J(\theta)=\frac{1}{2m} \left[\sum\limits^m_{i=1}(\hat y^{(i)}-y^{(i)})^2 + \lambda\sum\limits_{j=1}^{n}\theta_{j}^{2}\right]](https://images2.imgbox.com/77/16/CFJrdnFj_o.png)
对逻辑回归: