代理ip的使用方法——Python爬虫
本文内容:代理ip使用原理,如何在自己的爬虫里设置代理ip,如何知道代理ip有没有生效,没生效的话是哪里出了问题,个人使用的代理ip(付费)。
目录
代理ip原理
输入网址后发生了什么呢?
代理ip做了什么呢?
为什么要用代理呢?
爬虫代码中使用代理ip
代理ip的获取
检验代理ip是否生效
未生效问题排查
1.请求协议不匹配
2.代理失效
代理ip原理
输入网址后发生了什么呢?
- 浏览器获取域名
- 浏览器渲染结果
- 四次挥手释放TCP连接
- 服务器将查询结果返回给浏览器
- 浏览器通过HTTP协议向服务器发送数据请求
- 通过DNS协议获取域名对应服务器的ip地址
- 浏览器和对应的服务器通过三次握手建立TCP连接
其中涉及到了:
应用层:HTTP和DNS
传输层:TCP UDP
网络层:IP ICMP ARP
代理ip做了什么呢?
简单一点来说,使用代理ip就是:
原本你的访问目标网站
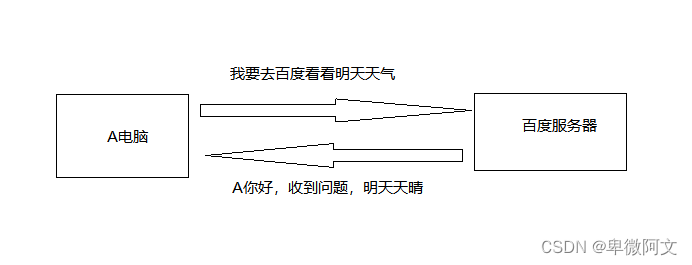
使用代理ip后你的访问目标网站
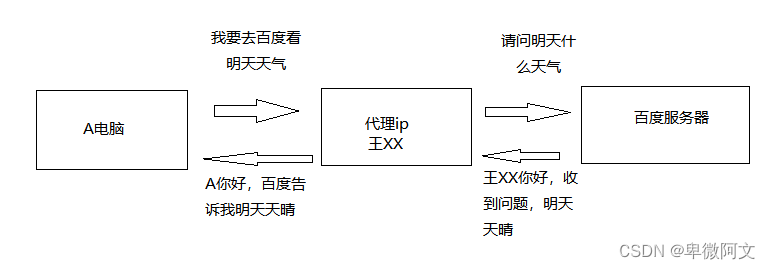
为什么要用代理ip呢?
我们在爬取数据的时候,如果使用自己的真实ip去访问目标网站,会有很大的风险被网站记录。而怎么才能避免我们的真实ip被网站记录呢,那就需要使用代理ip来给我们套上一层伪装,来让目标网站检测不到我们的真实ip地址。除了这种情况,有的网站限制了一些地区的ip地址,如果不使用代理的话,我们就无法正常访问目标网站了,所以我们很多时候需要使用代理ip:
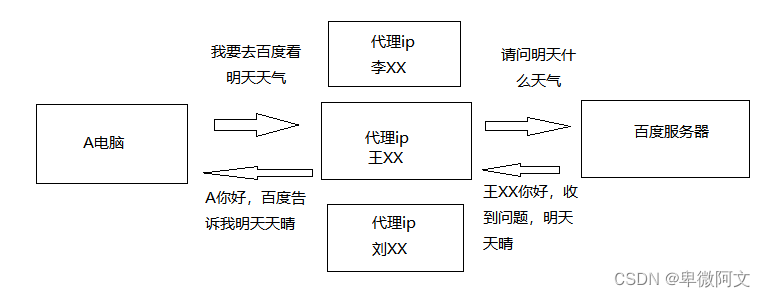
爬虫代码中使用代理ip
就像是请求时伪装头一样,伪装ip,注意是 { }
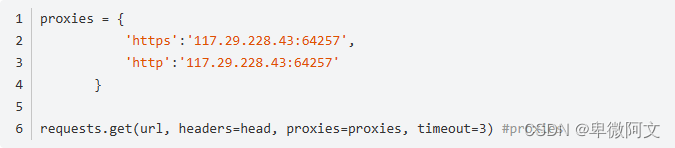
代理ip的获取
像我们刚刚的proxies存储的代理,是可以直接作为参数传进requests里面使用的。那现在我们就来做这个proxies。
首先打开一个代理IP提供商,我这里选择的是站大爷,我们一般使用api获取,也就是接口直接获取我们需要的ip,由供应商返回提供给我们的ip信息:
可以根据自己需要的情况设置:
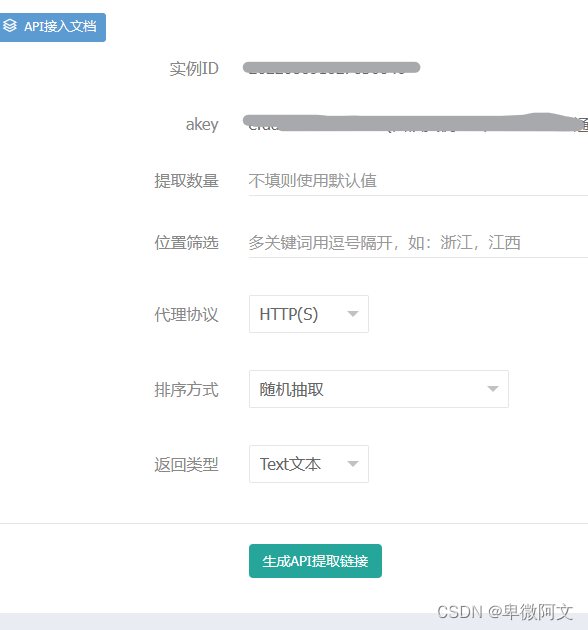
这里从URL点击进去使用生成的API接口链接来做演示,会生成一个url链接,我们requests直接去请求这个链接,就可以获得这个代理IP的详细信息。
# 拿到供应商给我们的代理IP
URL = "https://www.zdaye.net/?utm-source=csdnhao&utm-keyword=%3Fcsdnhao"
# 这里参数控制了数量 格式 和ip协议等等 这也算是它的一个优势吧,多的话可以提取几百,而且可以指定城市从固定地点提取ip,更符合爬虫模拟人类的行为特征。
url = "http://api.proxy.zdaye.io/getProxyIp?num=1&return_type=txt&lb=1&sb=0&flow=1®ions=&protocol=http"
# 输出ip
res = requests.get(url)
print(res.text)
# 这个ip就可以放在我们实际要请求的网页requests中了检验代理ip是否生效
我们访问一个网站,这个网站会返回我们的ip地址:
print(requests.get('http://httpbin.org/ip', proxies=proxies, timeout=3).text)
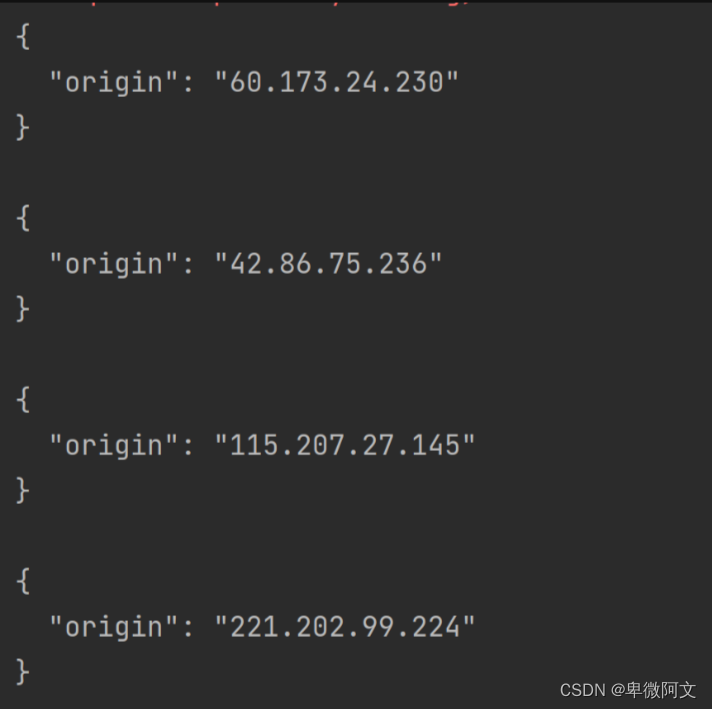
重点来了,我使用代理IP进行访问,如果返回来不是我们自己的IP,说明代理ip可用,可以伪装,也可以帮我们带回想要的信息。
我们看一下刚才我使用了四个不同的代理ip,结果是全部生效了,
未生效问题排查
如果你返回的还是本机地址,99%试一下两种情况之一:
1.请求协议不匹配
简单一点来说那就是,你请求的是http格式,那就要使用http的协议,是https格式,就要使用https的协议。

如果我请求是http ,但只有https,就会使用本机ip。
继续重点,我们获取的代理是两种都支持的,但是要自己像我这样设置,就像去买了条鱼准备放生。却又不把鱼丢河里去,你不让它去水里,它当然游不起来,这属于我们自己的问题。
2.代理失效
当我们使用的是免费代理或者一些廉价的普匿代理,那失效就是必然的了。使用代理还是建议选择一些优质的,名气大一点的代理。