ChatGLM2-6B 模型本地部署及基于 P-Tuning v2 的微调
1.说明
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,还引入了更强大的性能、更强大的性能、更高效的推理、更高效的推理四大特性,本文将详细阐述如何本地部署、P-Tuning微调及在微调的效果。
2. 显卡驱动安装(仅适用于Ubuntu)
如果不确定本机的显卡驱动是否是最合适的,最好显卡驱动也重装一下
下载驱动
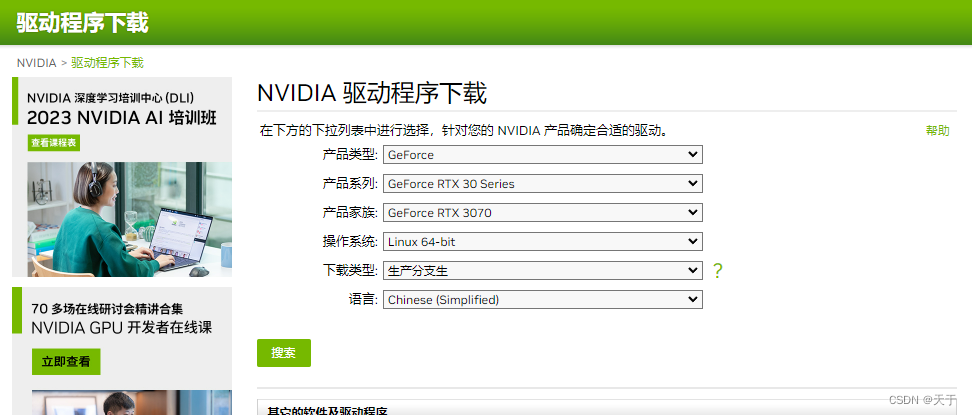
下载好对应驱动并放在某个目录下,我这里放在/usr/local

禁用nouveau
首先,编辑黑名单配置。
vim /etc/modprobe.d/blacklist.conf
在文件的最后添加下面两行。
blacklist nouveau
options nouveau modeset=0
然后,输入下面的命令更新并重启。
update-initramfs -u
reboot
重启后输入下面的命令验证是否禁用成功,成功的话这行命令不会有输出。
lsmod | grep nouveau
驱动安装
首先,使用apt卸载已有的驱动,命令如下。
apt-get purge nvidia*
进入驱动所在路径,赋予执行权限,并执行安装命令
chmod +x NVIDIA-Linux-x86_64-535.86.05.run
./NVIDIA-Linux-x86_64-535.86.05.run
注:具体文件根据下载的驱动来填写
nvidia-smi
3. CUDA安装
显卡驱动版本
nvidia-smi
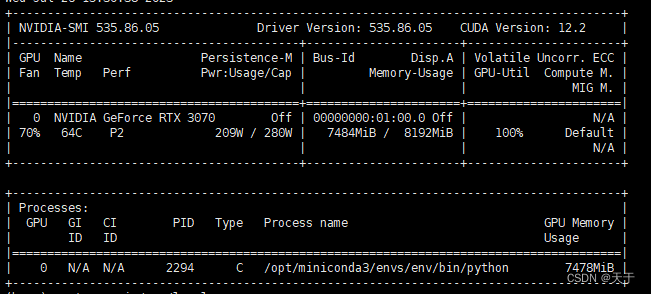
需要关注两个地方:
1.显卡驱动版本:535.86.05
2.显卡支持最高的CUDA版本:12.2
官网下载并安装对应版本CUDA
- 根据系统支持版本下载对应版本的CUDA Toolkit,作者此处选择CUDA10.2。官网链接
- 选择所需版本,通过对应命令进行下载安装(注意此处需要记住下载文件的目录,之后需要找到)
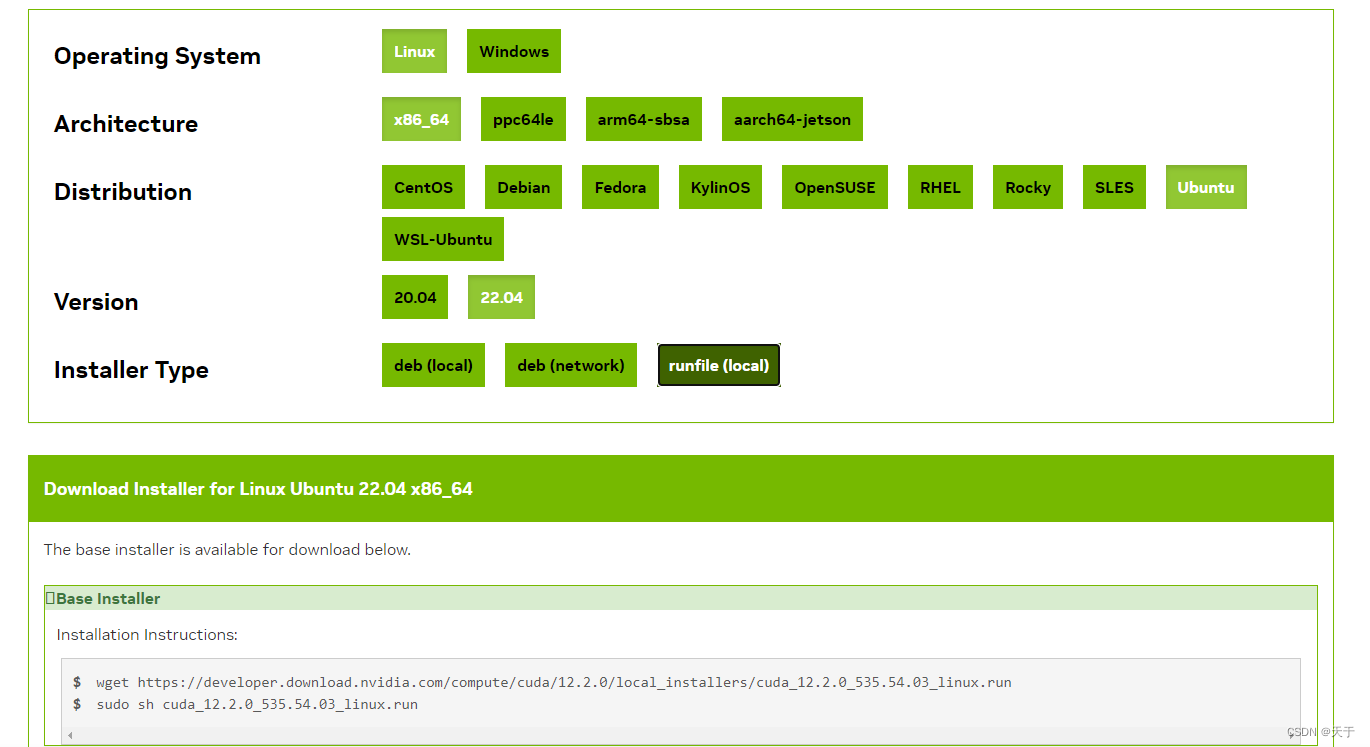
注:在输入第二条命令之后,经过短暂的等待,会出现用户安装界面,其中包括是否选择安装Nvidia显卡驱动,如果本地已有驱动,可选择不安装(将光标移至Driver,点击Enter即可),之后移至Install处,点击Enter即可进行安装。
3.配置环境变量
编辑 /etc/profile 结尾添加如下
export CUDA_HOME=/usr/local/cuda-12.2`
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
PATH="$CUDA_HOME/bin:$PATH"
使生效
sorce /etc/profile
4.测试CUDA安装是否成功
nvcc -V
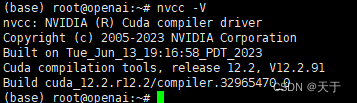
显示如上图表示成功!
4.ChatGLM2-6B安装部署
项目部署
git clone https://github.com/THUDM/ChatGLM2-6B

cd ChatGLM2-6B
安装依赖
pip install -r requirements.txt

其中transformers库版本推荐为4.30.2,torch推荐使用 2.0 以上的版本,以获得最佳的推理性能。
安装GIT LFS
测试是否安装成功:
$ git lfs install
> Git LFS initialized # 出现此消息说明安装成功
从Hugging Face Hub 下载模型
git clone https://huggingface.co/THUDM/chatglm2-6b
模型量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
# 按需在web_demo.py中修改,目前只支持 4/8 bit 量化
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).quantize(4).cuda()
其中"THUDM/chatglm2-6b"需修改为你本地部署的路径
注:如果内存只有8G,模型量化选择int4
启动web_demo.py
python web_demo.py
API部署
首先需要安装额外的依赖
pip install fastapi uvicorn
将api.py中的"THUDM/chatglm2-6b"修改为本地模型路径
tokenizer = AutoTokenizer.from_pretrained("D:\ChatGLM2-6B", trust_remote_code=True)
model = AutoModel.from_pretrained("D:\ChatGLM2-6B", trust_remote_code=True).quantize(4).cuda()
运行仓库中的 api.py
python api.py
5.基于 P-Tuning v2 的微调
软件依赖
运行微调除 ChatGLM2-6B 的依赖之外,还需要安装以下依赖
pip install rouge_chinese nltk jieba datasets
编写训练集
train.json
[
{
"content": "CVE-2021-44228是什么",
"summary": "Apache Log4j2远程代码执行漏洞"
},
{
"content": "CVE-2000-0208的详细描述",
"summary": "Apache Log4i是Apache的一个开源项目,Apache log4j2是Log4i的升级版本,用户可以控制日志信息输送的目的地为控制台、文件、GUI组件等,通过定义每一条日志信息的级别,能够更加细致地控制日志的生成过程。Log4j-2中存在JNDI注入漏洞,当程序将用户输入的数据进行日志记录时,即可触发此漏洞,成功利用此漏洞可以在目标服务器上执行任意代码。该漏洞影响 Apache Struts、Apache Solr.Apache Druid、Apache Filnk等众多组件,漏洞影响面大,危害性高,建议客户尽快自查在用软件系统是否受影响,采取措施防护此漏洞。"
},
{
"content": "CVE-2021-44228漏洞受影响的版本",
"summary": "Log4j 2.x <= 2.15.0-rc1"
},
{
"content": "CVE-2021-4428的总结",
"summary": "在2021年12月10日,在Apache软件基金会发布的版本2.15.0 Log4j的Java日志库,修复CVE-2021-44228,影响的Log4j 2.0-2.14一个远程执行代码漏洞。攻击者可以利用此漏洞通过提交自定义请求来指示受影响的系统下载并执行恶意负载。此漏洞非常严重,在 CVSS 3.1 评分量表上的评分为 10 分(满分 10 分)。"
},
{
"content": "CVE-2021-4428的安全公告",
"summary": "Apache 安全团队发布了针对影响 Apache Log4j2 的 CVE-2021-44228 的安全公告。恶意用户可以利用此漏洞以运行受影响软件的用户或服务帐户身份运行任意代码。使用 log4j 版本 2.0 到 2.14.1 的软件产品受到影响,而 log4j 1.x 不受影响。Cloudera 正在为受影响的软件提供短期解决方法,并且正在创建包含此 CVE 修复程序的新版本。"
},
{
"content": "Cloudera 如何应对CVE-2021-4428漏洞",
"summary": "我们行业和开源社区的软件和服务使用 Log4j 来处理日志消息。Cloudera 的安全和工程团队已确定此 CVE 对我们产品套件的影响,并且 Cloudera 客户已通过 Cloudera 的技术支持公告 (TSB) 和My Cloudera支持案例收到详细的更新。"
},
{
"content": "Cloudera 客户需要做什么来缓解CVE-2021-4428漏洞",
"summary": "我们鼓励客户查看我们的 TSB 中的详细信息并立即应用变通方法。同时,客户应计划升级到即将发布的 Cloudera 软件版本,其中包含针对此 CVE 的修复程序。了解此漏洞不仅限于 Cloudera 产品也很重要。此漏洞可能会影响底层基础架构软件以及客户在 Cloudera 产品之上运行的工作负载,例如 Spark 作业或 Flink 应用程序。我们建议客户评估其整个环境以使用 Log4j 并尽快对其进行修复。"
},
{
"content": "CVE-2021-4428漏洞验证(DNSLOG篇)",
"summary": "我们通过JNDI注入请求DNSLOG的恶意语句,如果在DNSLOG端能查看到访问记录,则证明远程代码执行漏洞存在我们CTFshow的靶场来做后续验证"
}
]
编写验证集
verify.json
[
{
"content": "Apache Log4j2远程代码执行漏洞是什么",
"summary": "CVE-2021-44228"
},
{
"content": "Apache Log4j2远程代码执行漏洞是CVE-2021-44228的简要介绍吗",
"summary": "是的"
},
{
"content": "Apache Log4i是Apache的一个开源项目,Apache log4j2是Log4i的升级版本,用户可以控制日志信息输送的目的地为控制台、文件、GUI组件等,通过定义每一条日志信息的级别,能够更加细致地控制日志的生成过程。Log4j-2中存在JNDI注入漏洞,当程序将用户输入的数据进行日志记录时,即可触发此漏洞,成功利用此漏洞可以在目标服务器上执行任意代码。该漏洞影响 Apache Struts、Apache Solr.Apache Druid、Apache Filnk等众多组件,漏洞影响面大,危害性高,建议客户尽快自查在用软件系统是否受影响,采取措施防护此漏洞。",
"summary": "CVE-2000-0208的详细描述"
},
{
"content": "Log4j 2.x <= 2.15.0-rc1是CVE-2021-44228漏洞受影响的版本",
"summary": "是的"
},
{
"content": "在2021年12月10日,在Apache软件基金会发布的版本2.15.0 Log4j的Java日志库,修复CVE-2021-44228,影响的Log4j 2.0-2.14一个远程执行代码漏洞。攻击者可以利用此漏洞通过提交自定义请求来指示受影响的系统下载并执行恶意负载。此漏洞非常严重,在 CVSS 3.1 评分量表上的评分为 10 分(满分 10 分)。",
"summary": "CVE-2021-4428的总结"
},
{
"content": "Apache 安全团队发布了针对影响 Apache Log4j2 的 CVE-2021-44228 的安全公告。恶意用户可以利用此漏洞以运行受影响软件的用户或服务帐户身份运行任意代码。使用 log4j 版本 2.0 到 2.14.1 的软件产品受到影响,而 log4j 1.x 不受影响。Cloudera 正在为受影响的软件提供短期解决方法,并且正在创建包含此 CVE 修复程序的新版本。",
"summary": "CVE-2021-4428的安全公告"
},
{
"content": "我们行业和开源社区的软件和服务使用 Log4j 来处理日志消息。Cloudera 的安全和工程团队已确定此 CVE 对我们产品套件的影响,并且 Cloudera 客户已通过 Cloudera 的技术支持公告 (TSB) 和My Cloudera支持案例收到详细的更新。",
"summary": "Cloudera 如何应对CVE-2021-4428漏洞"
},
{
"content": "我们鼓励客户查看我们的 TSB 中的详细信息并立即应用变通方法。同时,客户应计划升级到即将发布的 Cloudera 软件版本,其中包含针对此 CVE 的修复程序。了解此漏洞不仅限于 Cloudera 产品也很重要。此漏洞可能会影响底层基础架构软件以及客户在 Cloudera 产品之上运行的工作负载,例如 Spark 作业或 Flink 应用程序。我们建议客户评估其整个环境以使用 Log4j 并尽快对其进行修复。",
"summary": "Cloudera 客户需要做什么来缓解CVE-2021-4428漏洞"
},
{
"content": "如何验证CVE-2021-4428漏洞",
"summary": "我们通过JNDI注入请求DNSLOG的恶意语句,如果在DNSLOG端能查看到访问记录,则证明远程代码执行漏洞存在我们CTFshow的靶场来做后续验证"
}
]
训练
进入chatglm2-6b目录
编辑train_chat.sh
cd ptuning
vi train_chat.sh
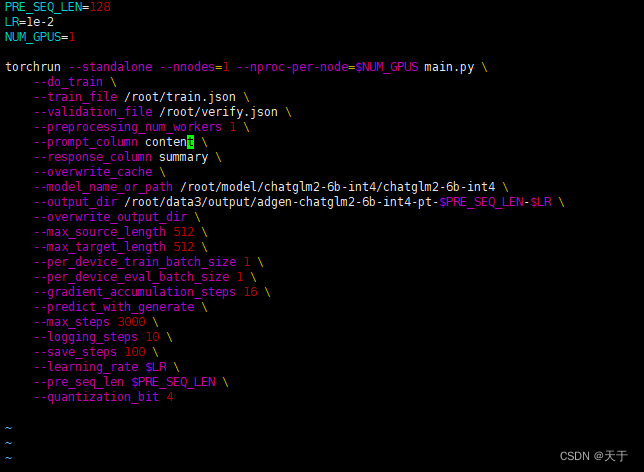
参数解释:
-
PRE_SEQ_LEN=128: 定义了一个名为PRE_SEQ_LEN的变量,并将其设置为128。这个变量的作用在后续的代码中会用到。
-
LR=2e-2: 定义了一个名为LR的变量,并将其设置为2e-2,即0.02。这个变量表示学习率,在后续的代码中会用到。
-
–train_file /root/train.json : 指定训练数据文件的路径和文件名为"/root/train.json"。
-
–validation_file /root/verify.json : 指定验证数据文件的路径和文件名为"/root/verify.json"。
-
–prompt_column content : 指定输入数据中作为提示的列名为"content"。
-
–response_column summary : 指定输入数据中作为响应的列名为"summary"。
-
–overwrite_cache : 一个命令行参数,指示在缓存存在的情况下覆盖缓存。
-
–model_name_or_path THUDM/chatglm-6b : 指定使用的模型的名称或路径为"THUDM/chatglm-6b"。
-
–output_dir output/adgen-chatglm-6b-pt- P R E S E Q L E N − PRE_SEQ_LEN- PRESEQLEN−LR : 指定输出目录的路径和名称为"output/adgen-chatglm-6b-pt- P R E S E Q L E N − PRE_SEQ_LEN- PRESEQLEN−LR"。这是训练结果和日志的保存位置。
-
–overwrite_output_dir : 一个命令行参数,指示在输出目录存在的情况下覆盖输出目录。
-
–max_source_length 512 : 指定输入序列的最大长度为512。
-
–max_target_length 512 : 指定输出序列的最大长度为512。
-
–per_device_train_batch_size 1 : 指定每个训练设备的训练批次大小为1。
-
–per_device_eval_batch_size 1 : 指定每个评估设备的评估批次大小为1。
-
–gradient_accumulation_steps 16 : 指定梯度累积的步数为16。在每个更新步骤之前,将计算并累积一定数量的梯度。
-
–predict_with_generate : 一个命令行参数,指示在生成模型的预测时使用生成模式。
-
–max_steps 3000 : 指定训练的最大步数为3000。
-
–logging_steps 10 : 指定每隔10个步骤记录一次日志。
-
–save_steps 1000 : 指定每隔1000个步骤保存一次模型。
-
–learning_rate $LR : 指定学习率为之前定义的LR变量的值。
-
–pre_seq_len $PRE_SEQ_LEN : 指定预设序列长度为之前定义的PRE_SEQ_LEN变量的值。
-
–quantization_bit 4 : 指定量化位数为4。这个参数可能是与模型相关的特定设置。
执行训练命令
sh train_chat.sh
注意:如果报错了,请检查一下本地模型中以下几个文件是否是最新的,如果不是去下载最新的替换。

训练完后,将微调模型载入
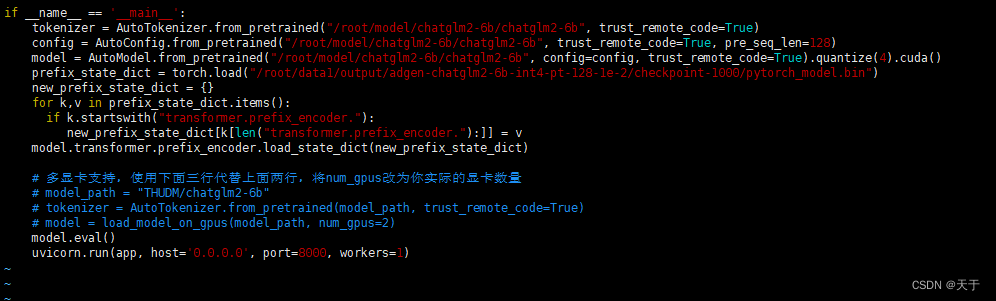
vi api.py
config = AutoConfig.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, pre_seq_len=128)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", config=config, trust_remote_code=True)
prefix_state_dict = torch.load(os.path.join(CHECKPOINT_PATH, "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
上面这一段代码加到api.py的相应位置,pre_seq_len 改成你训练时的实际值。如果你是从本地加载模型的话,需要将 THUDM/chatglm2-6b 改成本地的模型路径。
如果还是不太清楚如何修改可以参考一下我修改后的api.py
6.测试
微调前
prompt是提问,response是模型回答
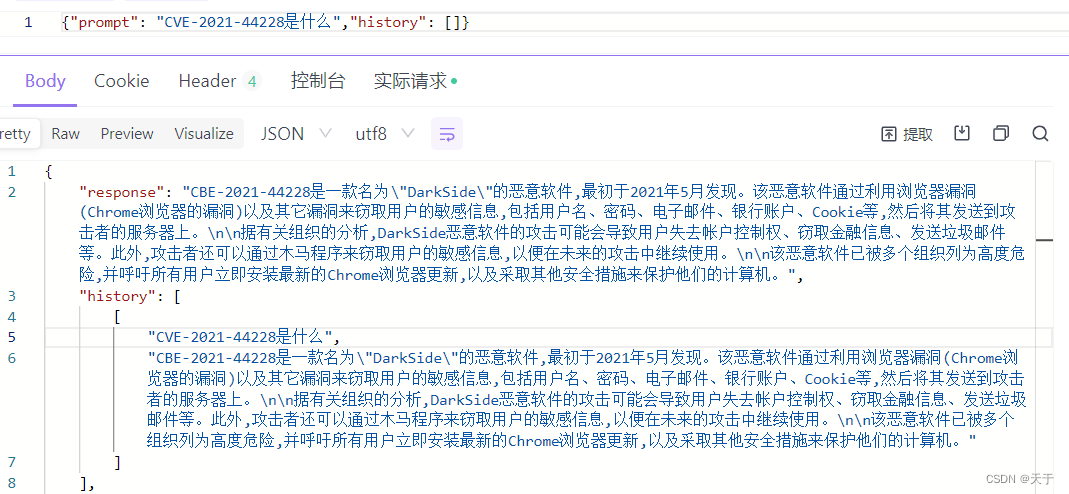
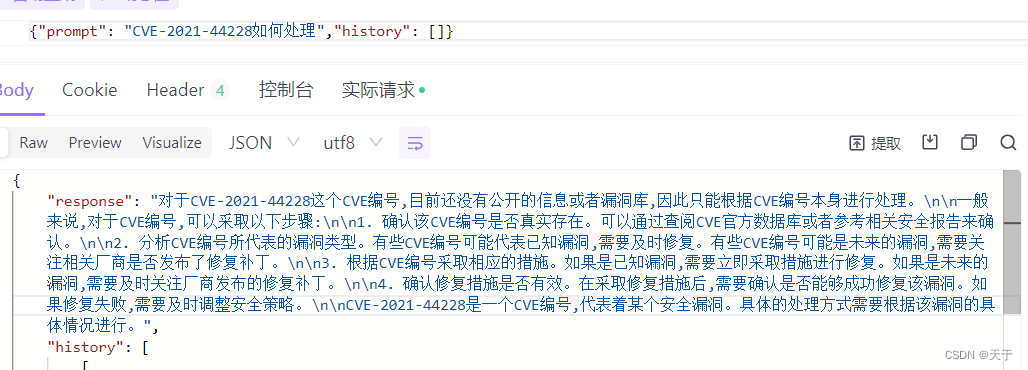
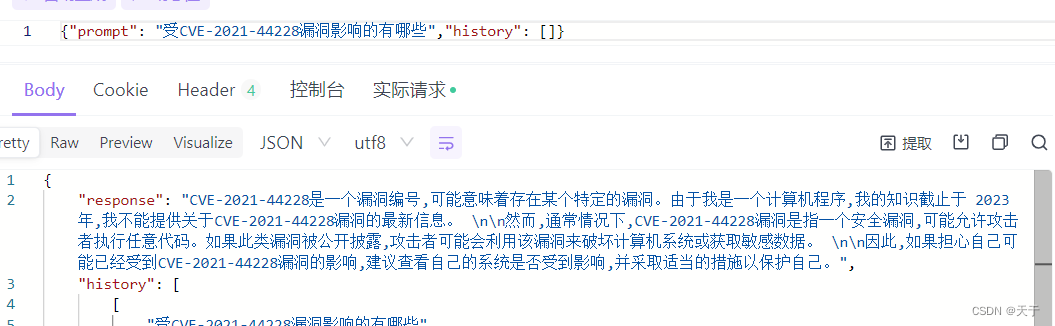
微调后
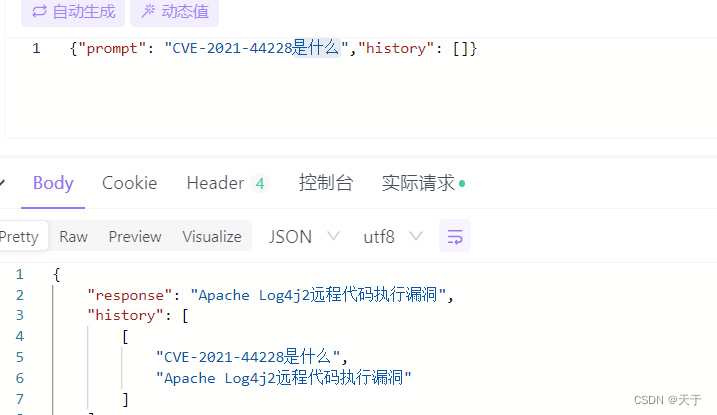
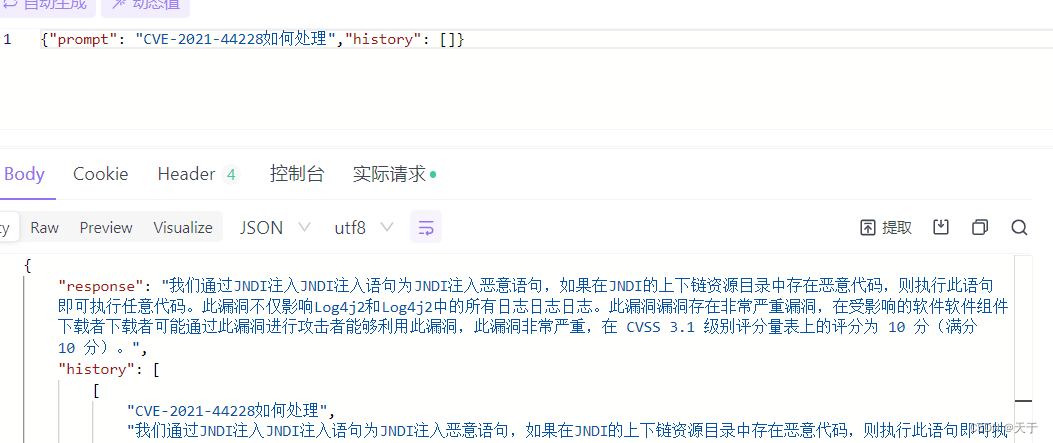
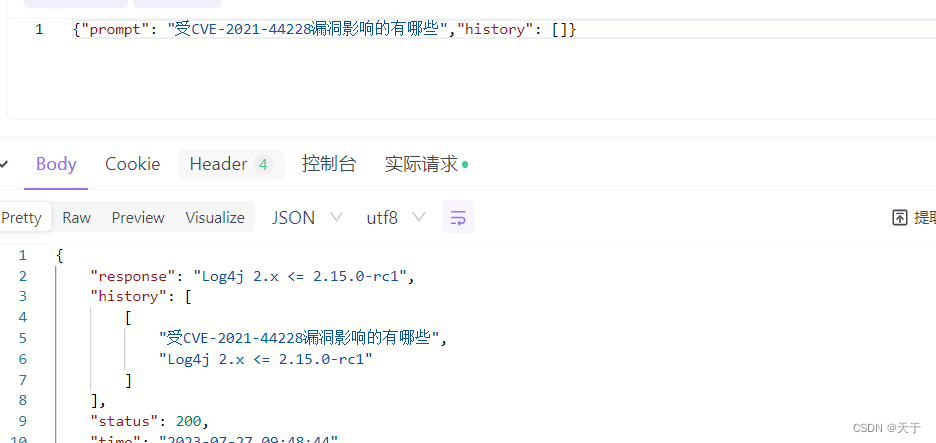
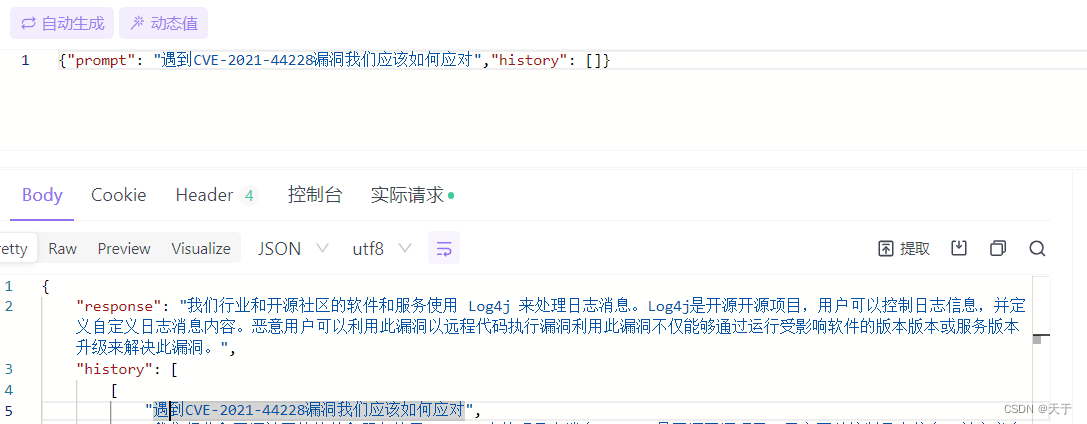
对比小结
经过测试可以看到微调后的ChatGLM2-6B模型对于CVE-2021-44228漏洞的回答会根据我们提供的语料作生成,因为给的训练集是针对CVE-2021-44228漏洞的,所以回答更加针对。而微调前是比较通用型的回答,可以适用于任何一种CVE漏洞。
7.总结
微调可以对原有模型作领域知识的训练,相关领域知识需要进行整理成语料,语料越充分相对来说模型作预测越准,还要结合调参,反复地训练,才有可能起到一定的效果。