看书标记【R语言数据分析项目精解:理论、方法、实战 7】
看书标记——R语言
【R语言数据分析项目精解:理论、方法、实战】
Chapter 7 构建用户画像
7.1项目背景、目标和方案
7.1.1项目背景
大部分服务性企业从以产品为中心的理念转变成了以用户为中心的理念。产品的设计从企业想让用户用什么产品变成了企业为用户的需求设计产品,所以应尽量多地收集用户信息并分析用户特征。首先需要搞清用户画像系统的整个全貌和构建方法,并且制定用户画像系统的标准。
7.1.2项目目标
(1)梳理用户画像理论,了解用户画像指标制作流程。
(2)针对公司业务情况,创建用户画像系统指标大类。
(3)制定用户画像指标规范。
7.2项目技术理论简介
7.2.1用户画像的基本概念
用户画像就是用户信息的标签化过程,这些标签的集合反映了一个用户的整体全貌。
7.2.2用户画像应用领域
市场营销:市场营销人员可以根据用户画像标签挑选合适的用户进行有针对性的营销,可以有效提高活动效果、降低成本,也称数据库营销。
业务产品设计、功能界面设计:找出主要用户,得到用户画像系统的任务。
智能化推荐:最常用的就是协同过滤算法,分为两类:根据用户属性(找与用户相似的用户喜欢的东西,需要事先对用户打标签)、根据产品属性。
监控运营环境:监控某几个类别用户的行为,可以及早发现运营情况的局部变化。
用户统计数据:有助于发现被整体数据所掩盖的数据问题。
7.2.3用户画像分类
静态信息标签:确定后不会变动的标签。
动态信息标签:会随着时间的推移及用户行为的不同而发生变化的标签。
or
确定性指标:数值准确、含义清晰的指标。
非确定性指标:预测型的标签,其数值是统计推断的结果而非真实发生的,如潜在高价值用户、使用偏好等。
7.2.4用户画像构建
1.数据源
(1)用户基本信息:用户注册信息表、收件人信息、通过活动收集、模型预测。
(2)用户行为数据:通过埋点的方式记录用户的浏览记录得到。
(3)用户订单数据:高利润用户、忠诚度用户、价格敏感用户、产品偏好等。
(4)用户投诉信息:游客一般不会有反馈,用户信息也包括反馈信息。
2.用户画像构建粒度
用户id的唯一标识:Cookie、uid、E-mail、微信、QQ、微博、手机号、身份证。
3.用户画像构建抽象方法
将数据聚集到适当的粒度、将数据旋转到相应时间序列、对已有值进行适当的变换、各种方式创造派生变量(虚拟变量)。
4.用户画像标签创建流程
1、由业务方提出需求,共同探讨标签内容,确定标签使用的业务场景,指定标签含义。
2、确定标签用途后,由标签含义收集或寻找相应的基础数据,之后整合到统一的数据平台。
3、对数据统一处理,用统计方法对明细数据进行适当的汇总。
4、离散型数据(直接用于用户画像标签)、连续数据(离散化处理),五级分和十级分等。
业务方的一个需求可以创建出至少一个用户画像,需注意,在创建用户画像标签时必须注明应用场景和使用方法,有时不同场景的指标数据会有差异,所以需要附上指标说明书。
5.用户画像标签构建难点
1、打通不同数据源,链接来自不同数据源的用户数据。
2、用户画像的时效性,针对动态标签,可以建立一套自动化更新流程,一旦源头更新,下游指标数据可以自动更改。对于预测型数据,可以建立一套机制来提醒分析人员定期或者不定期对标签数据进行修改,保证数据的时效性。
3、将连续型指标合理地离散化。
7.2.5用户画像标签的数值处理方法
1.数值归一化
min-max标准化(把数据归一到0~1)、log函数标准化(较适用于偏态数据)、atan函数标准化(如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上。)、Z-score函数标准化(最常用)。
2.连续型数值的离散化方法
1、等距划分:将取值范围均匀的划分成n分,每份间距相等。
2、等频划分:把数据均匀的划分为n份,每份的样本数量相同,常会将数据排序后划分,达到分层抽样的目的。
3、聚类分析:常用的是k-means聚类。k-means聚类的聚类类别数需要事先指定,可采用“伪F值”判断,k越大,组间距离与总方差的比例越大,F就越接近1,但增加的比例会逐步减少,增加比例的绝对量出现拐点时,k的取值可以用做最终的划分类别数。
7.3项目实践
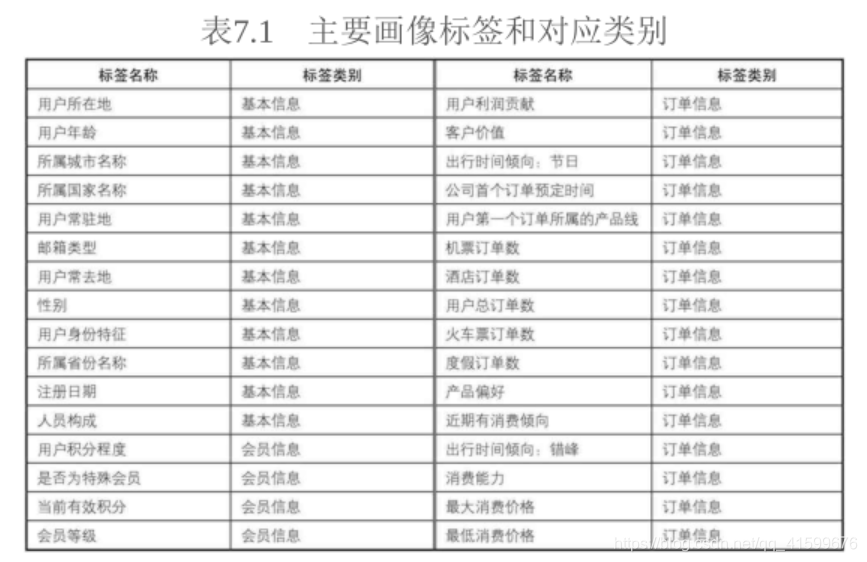
粒度(指统一用什么样的id作为用户的唯一标识)选为uid,包括4个类别的用户画像标签,基本信息、会员信息、浏览行为、订单信息
用户年龄标签有用k-means做离散化处理。
1.指标数据的描述性统计
setwd("C:\\Users\\用户路径")
age_uid<-read.csv("age.csv",header=TRUE,stringsAsFactors=FALSE)
#####################################################################
#函数功能:画出数据分布函数及QQ图
#参数说明:input.data:连续型指标数据
index_dispic<-function(input.data){
opar <- par(no.readonly=TRUE)
par(mfrow=c(2,1))
qqnorm(input.data,main="QQ图")
qqline(input.data)
hist(input.data,freq=F,main="直方图和密度估计曲线")
lines(density(input.data),col="blue")
x<-c(round(min(input.data)):round(max(input.data)))
lines(x,dnorm(x,mean(input.data),sd(input.data)),col="red")
par(opar)
}
#####################################################################
#函数功能:对连续型指标数据做描述性统计
#参数说明:x:连续型指标数据
mystats <- function(x, na.omit = FALSE) {
if (na.omit)
x <- x[!is.na(x)]
m <- round(mean(x),2)
n <- round(length(x),2)
s <- sd(x)
var<-round(var(x),2)
range<-round(range(x),2)
min<-min(x)
max<-max(x)
q_25<-quantile(x,0.25)
median<-round(median(x),2)
q_75<-quantile(x,0.75)
#计算偏度
skew <- round(sum((x - m)^3/s^3)/n,2)
#计算峰度
kurt <- round(sum((x - m)^4/s^4)/n - 3,2)
return(data.frame(n = n,mean = m,stdev = s
,var=var,min=min,q_25=q_25,median=median,q_75=q_75,max=max
, skew = skew, kurtosis = kurt))
}
index_dispic(age_uid$age)
mystats(age_uid$age)
对连续型的年龄数据做描述性统计分析,了解大致情况。
2.离散化过程
result_index<-c() #寻找聚类结果最好的分类
k_set<-c(2:8) #考察类别数为2至8
for (i in k_set)
{
result<-kmeans(age_uid$age,i)
#计算伪F值
result_index<-c(result_index,result$betweens/(result$tot.withinss+result$betweens))
}
plot(k_set,result_index,type='o') #画出类别与伪F值折线图
输出分类类别数与伪F值对照图,通过拐点判断k的大小。
i<-5 #将原始变量分成5类
result<-kmeans(age_uid$age,i)
result_cluster_per<-data.frame(clusterper=paste(round(result$size*100/length(result$cluster),2),'%',sep=''))
result_data<-data.frame(center=round(result$centers,2),cnt=result$size,result_cluster_per) #对每类数据进行描述性统计
cluster<-data.frame(value=age_uid$age,cluster=result$cluster)
cluster_result<-aggregate(value~cluster,data=cluster ,FUN=mystats) #整合所有数据
total_result<-data.frame(as.data.frame(cluster_result[[2]]),result_data)
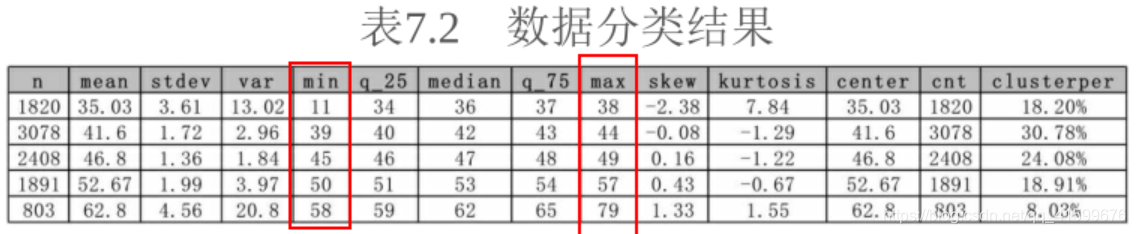
clusterper为每类别占比,k-means是无监督的离散化方法,实际应用中应该根据业务做适当的调整,具体场景还有响应变量时,可以用卡方、信息增益、Gini系数等方法进行分类。
本章节主要是对用户标签的一个数据汇总,特别是连续型数据离散化。如果要建模,适合选择逻辑回归建模,COX生存模型等可以包含离散型数据的方法。