java定时调度任务
java常用定时调度任务方式:
1. Timer
2.scheduleThreadPool
3.spring task
4.quartz
5.xxl-job
6. date.calendar.localdatetime
1.Timer
使用方式:
public class Test {
public static void main(String[] args) {
Timer time=new Timer();
TimerTask task=new TimerTask() {
@Override
public void run() {
System.out.println("start!!!!!");
}
};
//延迟一秒执行
time.schedule(task,1000);
//立刻执行
// time.schedule(task,System.currentTimeMillis());
// //延迟一秒执行,每一秒重复执行
// time.schedule(task,1000,1000);
//立刻执行
// time.schedule(task,System.currentTimeMillis(),1000);
// time.scheduleAtFixedRate(task,1000,1000);
// time.scheduleAtFixedRate(task,System.currentTimeMillis(),1000);
}
}class timer 由一个queue和 timerthread组成,time里面包含内部类threadreaper用于当time对象没有应用或者队列为空时的退出;而time的声明方式只要是名称+是否是守护进程
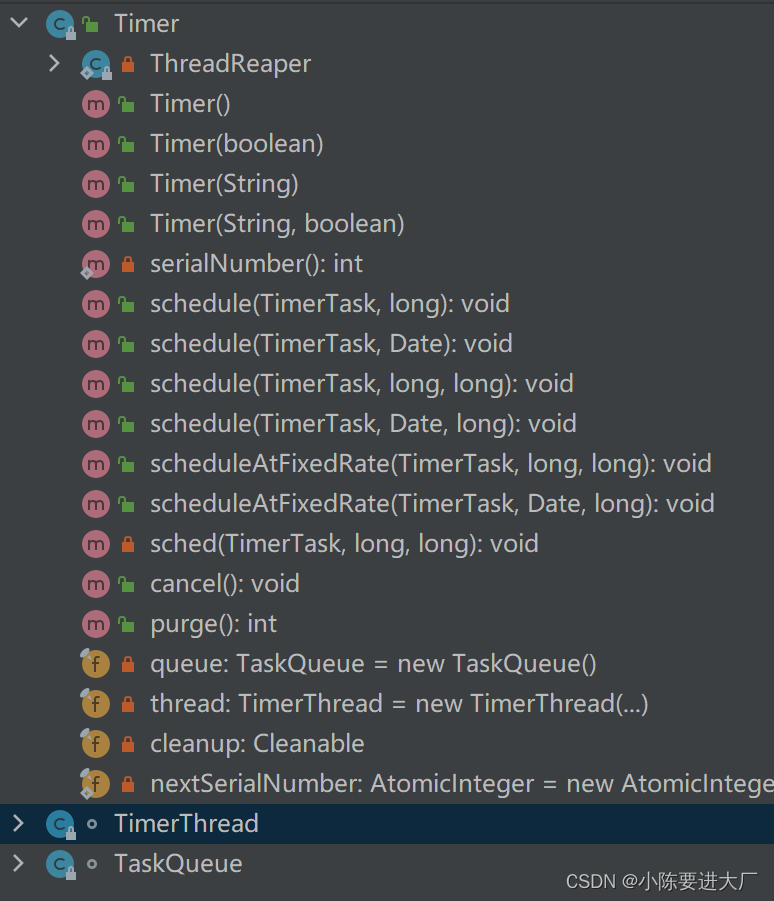
守护线程与非守护线程:
jvm中规定但不存在非守护进程时jvm就会退出;
也就是有非守护线程时,程序不会退出;而守护线程会随主程序一起退出;
thread.setDeamon(true)设置为守护;默认非守护
Taskqueue:
初始128大小的数组,扩容每次扩建2倍
本质是一个最小堆,按照执行时间排序,重排序从根往下(任务重复执行),插入从下往上(插入新任务);
private void fixDown(int k) {
int j;
while ((j = k << 1) <= size && j > 0) {
if (j < size &&
queue[j].nextExecutionTime > queue[j+1].nextExecutionTime)
j++; // j indexes smallest kid
if (queue[k].nextExecutionTime <= queue[j].nextExecutionTime)
break;
TimerTask tmp = queue[j]; queue[j] = queue[k]; queue[k] = tmp;
k = j;
}
}
private void fixUp(int k) {
while (k > 1) {
int j = k >> 1;
if (queue[j].nextExecutionTime <= queue[k].nextExecutionTime)
break;
TimerTask tmp = queue[j]; queue[j] = queue[k]; queue[k] = tmp;
k = j;
}
}Timerthread
mainloop方法重复执行,通过period区分schedule和scheduleAtFixedRate

period <0,schedule 上一个任务执行完的时间+period
period >0,scheduleAtFixedRate 固定的任务时间+period
优缺点:
优点:简单,容易使用;线程安全;
缺点:
1. 单线程运行,串行化,效率低;
2. 只要有一个任务异常全任务退出;
3. 上一个任务的执行情况影响下一个任务的运行时间;
4. 时间的设置极端情况下只能决定任务的先后顺序,并不能够保证到点执行;
5. 使用system.currentTimeMills()获取时间安排任务,不支持按照年月日执行,只适合执行近期定时任务;
2.scheduleThreadPool
线程池加延迟队列
延迟队列和time的差不多;
优缺点:
优点:基于多线程的定时任务,多任务之间互相不干扰,支持周期性的执行任务,并且带有延迟功能;
缺点:不支持一些复杂的规则设置;
3.SpringTask
cron表达式:
秒、分、时、日、月、周、年
【*】:每的意思。在不同的字段上,就代表每秒,每分,每小时等。
【-】:指定值的范围。比如[1-10],在秒字段里就是每分钟的第1到10秒,在分就是每小时的第1到10分钟,以此类推。
【,】:指定某几个值。比如[2,4,5],在秒字段里就是每分钟的第2,第4,第5秒,以此类推。
【/】:指定值的起始和增加幅度。比如[3/5],在秒字段就是每分钟的第3秒开始,每隔5秒生效一次,也就是第3秒、8秒、13秒,以此类推。
【?】:仅用于【日】和【周】字段。因为在指定某日和周几的时候,这两个值实际上是冲突的,所以需要用【?】标识不生效的字段。比如【0 1 * * * ?】就代表每年每月每日每小时的1分0秒触发任务。这里的周就没有效果了。
0 0 * * * ?每小时一次
0 /5 * * * ?每五分钟一次
0 0 5 ? * 1 每个星期一早上5点
1.基于注解的静态单线程
@Component
@EnableScheduling
public class Test {
@Scheduled(cron = "0 0 5 ? * 1")
public int Schedule1(){
return 1;
}
@Scheduled(cron = "0 5 * ? * *")
public int Schedule2(){
return 1;
}
@Scheduled(fixedRate = 1000)
public int Schedule3(){
return 1;
}
@Scheduled(fixedDelay = 1000)
public int Schedule4(){
return 1;
}
}2.基于接口的动态方法,从数据库动态获取
@Component
@EnableScheduling
class ScheduleConfig implements SchedulingConfigurer{
@Autowired
JdbcTemplate jdbcTemplate;
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
taskRegistrar.addTriggerTask(
new Runnable() {
@Override
public void run() {
System.out.println("qqqqq");
}
},(triggerContext) ->{
String sql="select cron from scheduled where cron_id=?";
int id=1;
String cron=jdbcTemplate.queryForObject(sql,new BeanPropertyRowMapper<>(String.class),id);
return new CronTrigger(cron).nextExecution(triggerContext);
}
);
}
}本质上注解默认使用了系统配置的多线程池;
3.基于注解的多线程定时任务 使用@enableasync和@async注解;
@Component
@EnableScheduling
@EnableAsync
class ScheduleConfig implements SchedulingConfigurer{
@Autowired
JdbcTemplate jdbcTemplate;
@Async
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
taskRegistrar.addTriggerTask(
new Runnable() {
@Override
public void run() {
System.out.println("qqqqq");
}
},(triggerContext) ->{
String sql="select cron from scheduled where cron_id=?";
int id=1;
String cron=jdbcTemplate.queryForObject(sql,new BeanPropertyRowMapper<>(String.class),id);
return new CronTrigger(cron).nextExecution(triggerContext);
}
);
}
}优缺点:
优点:开启定时任务非常方便,支持复杂的cron表达式,单任务完后执行下一个任务;
缺点:默认单线程,不支持集群部署,不能做数据存储型定时任务;
4.quartz
任务名,任务分组,调用目标,执行表达式、计划策略等
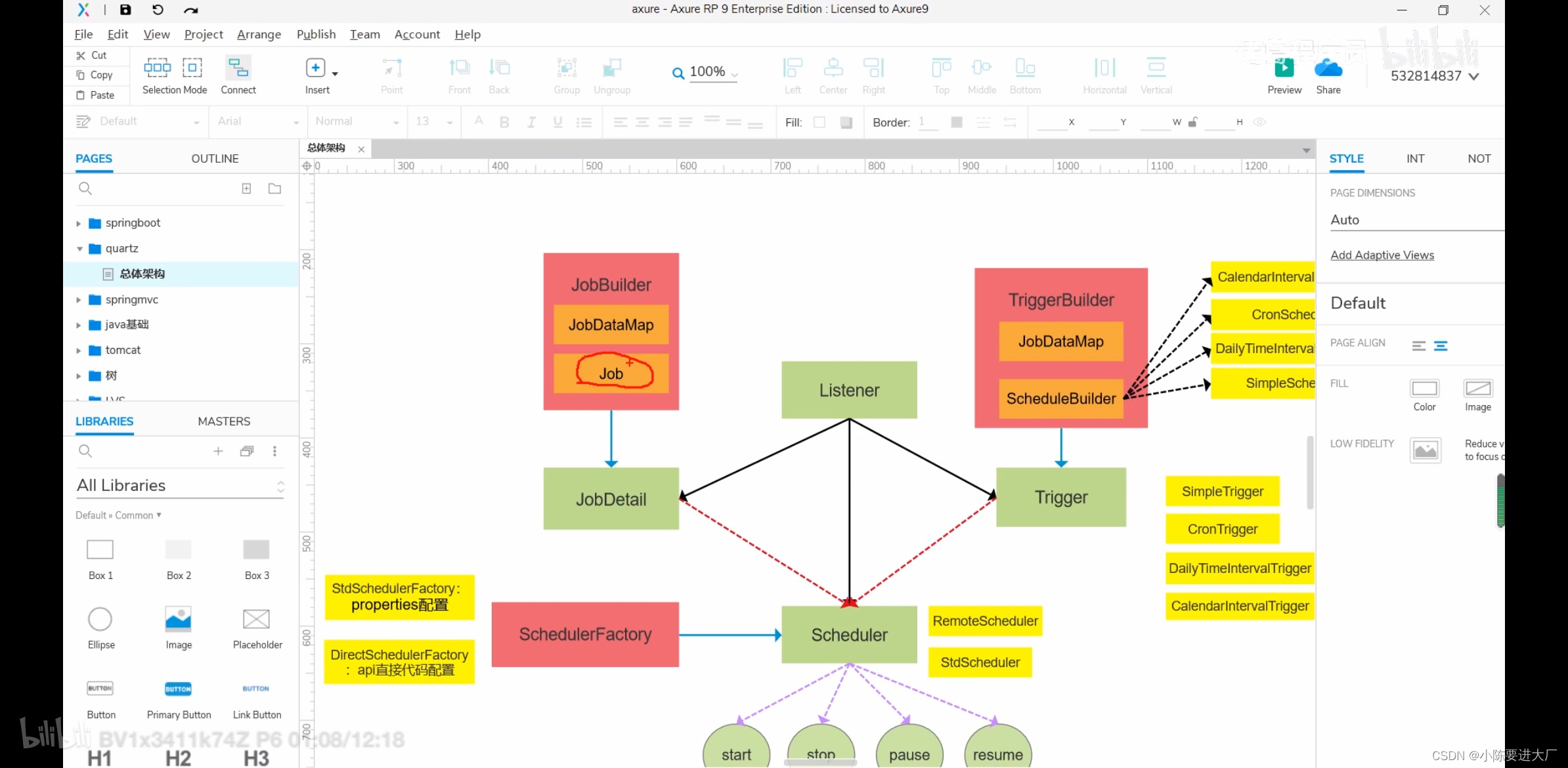
job->jobtail 一个任务,多个任务属性
trigger:触发器 crontrigger
schedule:调度器
通过builder创建job\trigger
schedule通过property创建
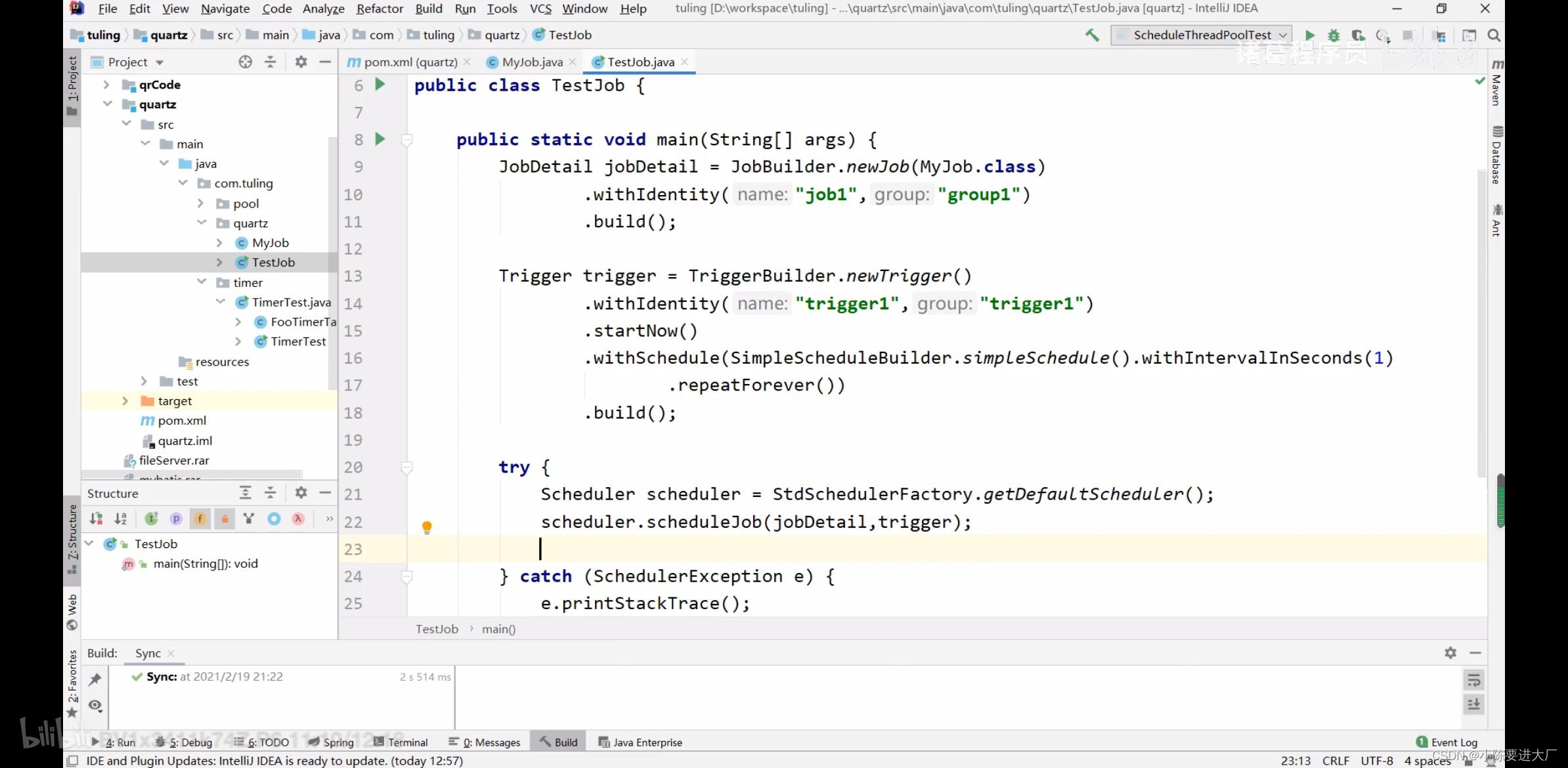
每一次执行任务使用的是新的jobdetail,并发执行,相互之间并不干扰;
要想串型,使用@DisallowConcurrentExecution在job类上;
每一次执行任务使用的是新的jobdatamap,并发执行,相互之间并不干扰;
要想使用同一个map,@PersistJobDateAfterExecution在job类上;
spingboot整合quartz
1. 监听器
实现applicatoinListerner重写onApplicationEvent生成schdele,并注入trigger和jobdetail
2. schedule
@configture配置
scheduleFactory生成,设置quartproperties,设置线程池,通过工厂模式返回schedule对象;
每个节点跑一个job定义,而不是一个job跑在不同节点上;
锁机制
目前quartz实现分布式任务调度用的是库表行级锁机制,其原理是利用qrtz_locks表保证某个节点只能有一个任务线程获得该行级锁,如果有其他节点想执行同样的任务需要等之前线程释放锁,否则处于等待状态。
也就是说,quartz的分布式集群原理是利用数据库锁来保证操作的顺序性,但是这里有个致命的问题:如果程序中有大量的短周期任务(比如订单处理、库存处理等)需要频繁处理,就会存在各节点的线程抢占数据库锁,从而导致大量线程处于等待状态, 其任务调度的性能将大大受限于业务。
quartz默认使用的有建立的表结构,存储在数据库里,集群工作时,使用表锁实现及合作;
优点:支持多线程,可以做数据存储型任务,维护性高,支持参数传递;
缺点:需要整合spring,不能直接调用业务层service
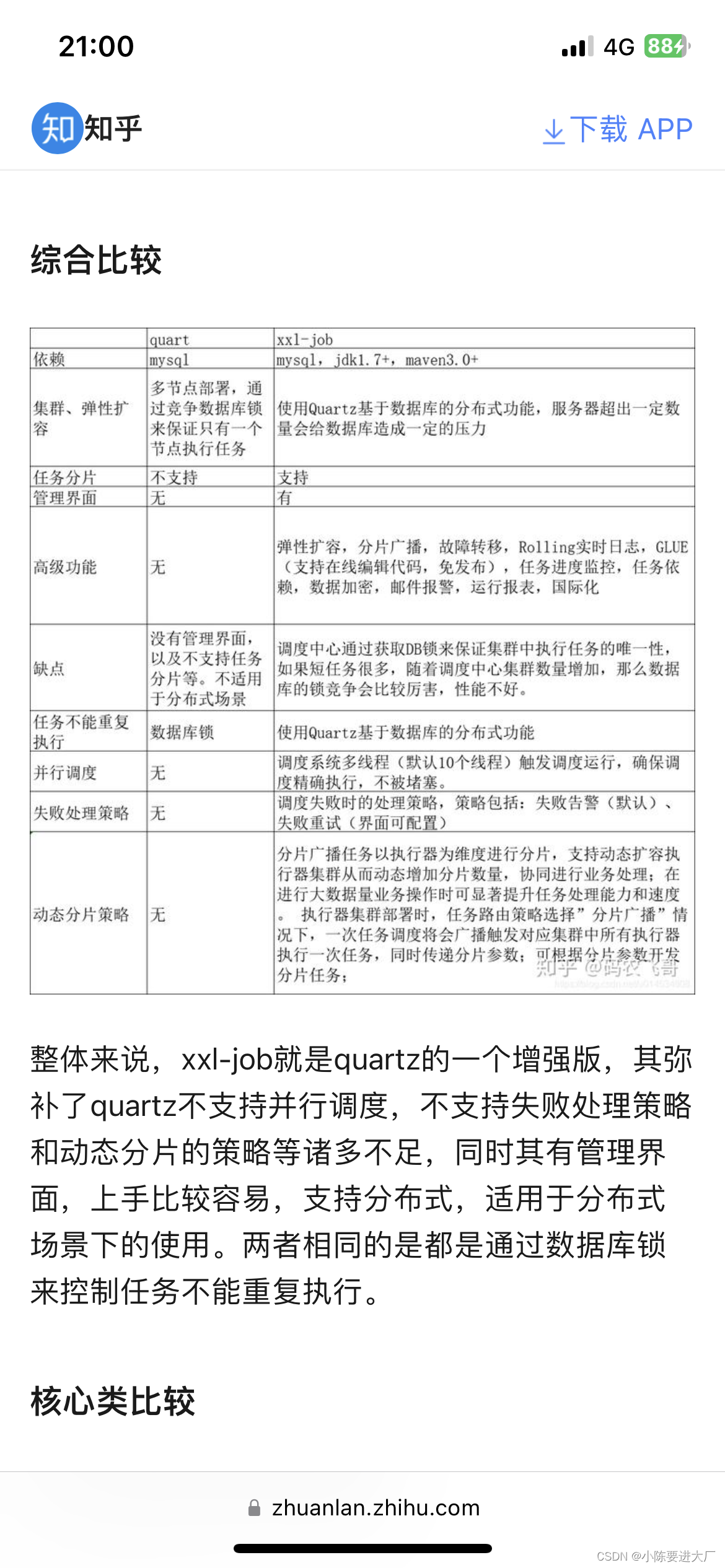
5.xxl-job
6.常见的时间表达方式
System.out.println(System.currentTimeMillis());
//1680676759909
long second = System.currentTimeMillis()/1000;
long minute = second /60;
long hour = minute /60;
System.out.println("h:"+(hour%24+8)+"--m:"+minute%60+"--s:"+second%60);
//h:14--m:39--s:19
Date d=new Date();
LocalDateTime t2=LocalDateTime.now(ZoneId.systemDefault());
System.out.println(t2.toString());
//2023-04-05T14:39:19.068845
LocalDateTime t = d.toInstant().atZone(ZoneId.systemDefault()).toLocalDateTime();
System.out.println(t.getYear()+"-"+t.getMonth().getValue()+"-"+t.getDayOfMonth()+
"-"+t.getHour()+"-"+t.getMinute()+"-"+t.getSecond());
//2023-4-5-14-39-19
Calendar c=Calendar.getInstance();
long temp=c.getTimeInMillis();
System.out.println(c.getTime());
System.out.println(c.getTimeInMillis());
c.set(2023,3,5,14,58,30);
System.out.println(c.getTime());
System.out.println(c.getTimeInMillis());
System.out.println(c.getTimeInMillis()-temp);
//Wed Apr 05 15:01:43 CST 2023
//1680678103637
//Wed Apr 05 14:58:30 CST 2023
//1680677910637
//-193000相比于date和calendar,
localdatetime不仅线程安全,而且表达方便,更常使用;