COUNT(expr) [over_clause]
Returns a count of the number of non-NULL values of expr in the rows retrieved by a SELECT statement. The result is a BIGINT value.
If there are no matching rows, COUNT() returns 0. COUNT(NULL) returns 0.
统计返回非NULL行的行数,返回结果是一个BIGINT类型。
如果没有匹配行, COUNT() 返回 0. COUNT(NULL) 返回 0.
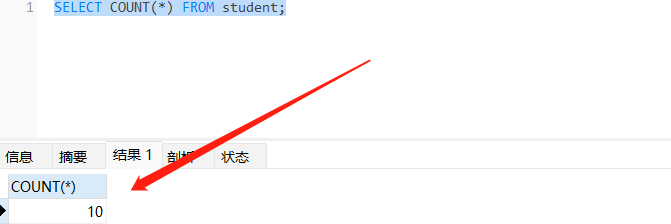
COUNT(*) is somewhat different in that it returns a count of the number of rows retrieved, whether or not they contain NULL values.
For transactional storage engines such as InnoDB, storing an exact row count is problematic. Multiple transactions may be occurring at the same time, each of which may affect the count.
InnoDB does not keep an internal count of rows in a table because concurrent transactions might “see” different numbers of rows at the same time. Consequently, SELECT COUNT(*) statements only count rows visible to the current transacti
COUNT(*)有些不同,因为它返回检索到的行数的计数,无论它们是否包含NULL值。
对于InnoDB这样的事务性存储引擎,存储精确的行数是有问题的。多个事务可能同时发生,每个事务都可能影响计数。
InnoDB不保留表的内部行数,因为并发事务可能同时看到不同的行数。因此,SELECT COUNT(*)语句只对当前事务可见的行进行计数。
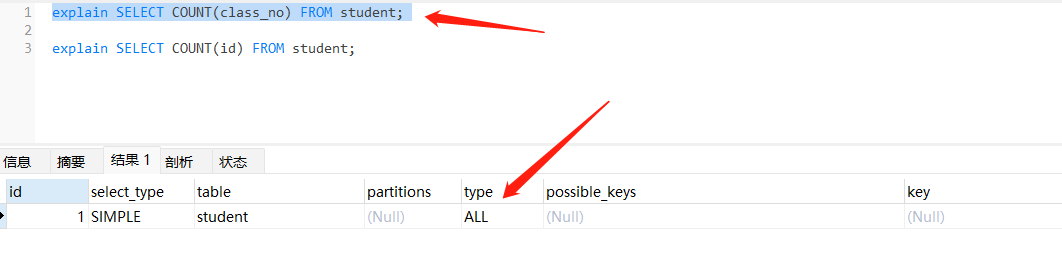
// 没有索引 进行全表扫描
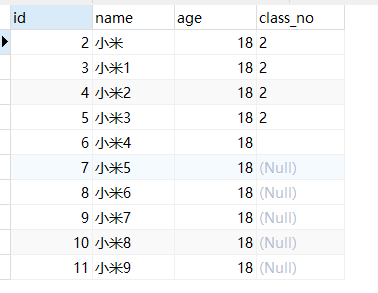
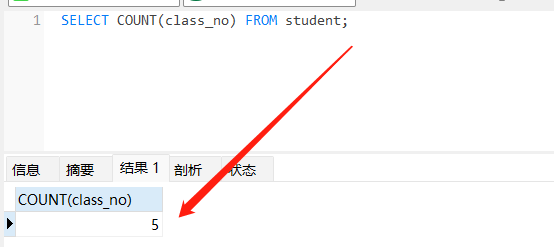
explain SELECT COUNT(class_no) FROM student;
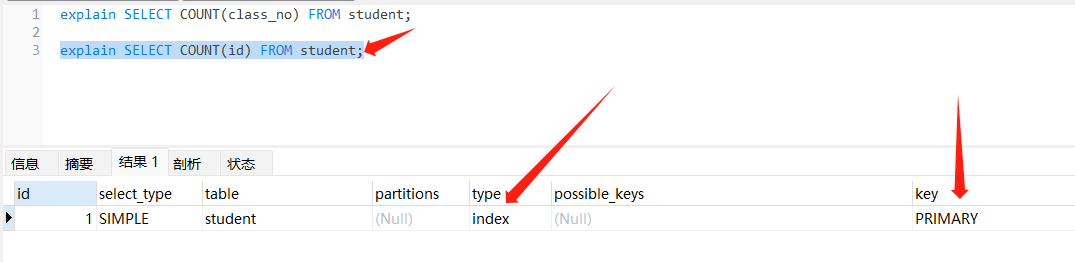
// 有索引 使用索引进行计数
explain SELECT COUNT(id) FROM student;
count(*)、count(1)、count(2)…count(n)
先看一下官网说明:
InnoDB processes SELECT COUNT(*) statements by traversing the smallest available secondary index unless an index or optimizer hint directs the optimizer to use a different index.
If a secondary index is not present, InnoDB processes SELECT COUNT(*) statements by scanning the clustered index.
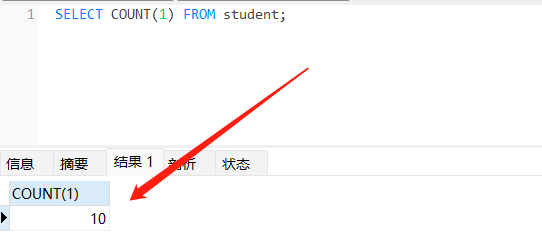
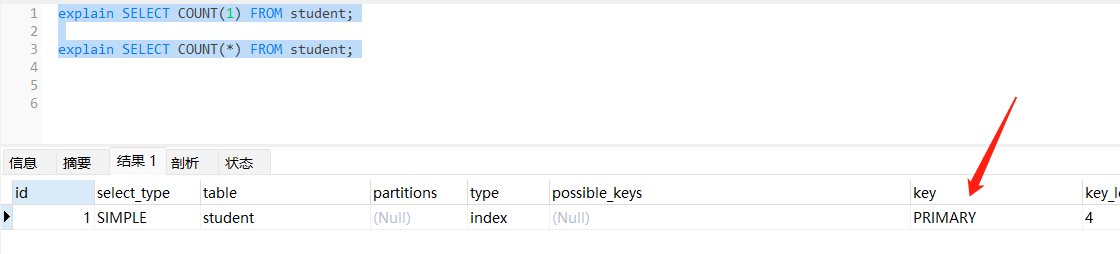
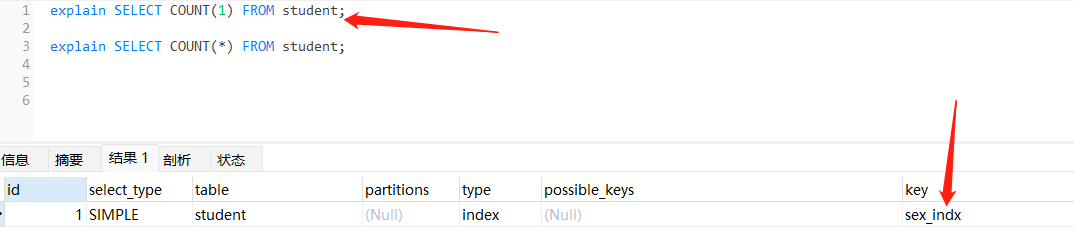
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
大致的意思是说,优先遍历最小的可用二级索引来进行计数,除非查询优化器提示使用不同索引。如果二级索引不存在,则扫描聚簇索引处理。
InnoDB 使用相同的方式处理 count(*)、count(1)、count(2)...count(n)
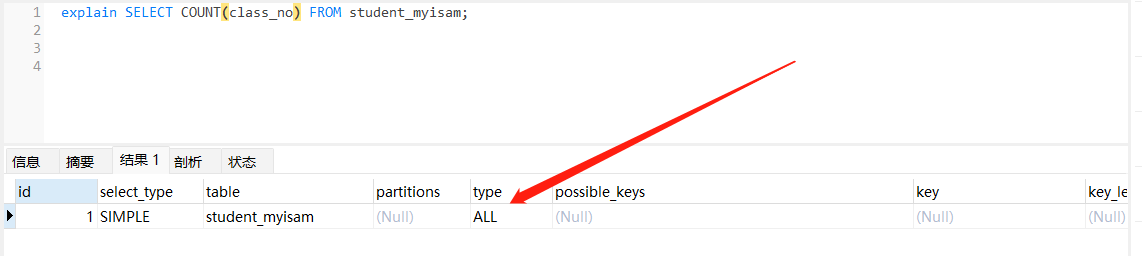
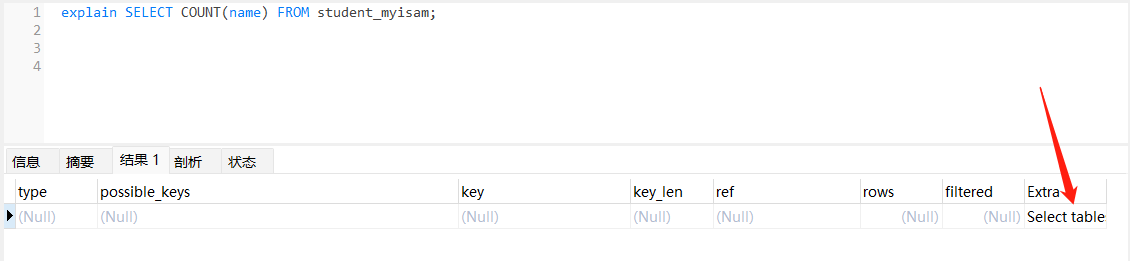
// 无索引且未命中特殊优化规则 使用全表扫描explainSELECTCOUNT(class_no)FROM student_myisam;// 命中特殊规则 name 不为 NULLexplainSELECTCOUNT(name)FROM student_myisam;
count(*)、count(1)、count(2)…count(n)
直接查询表统计信息获取。
MyISAM 中的特殊优化
For MyISAM tables, COUNT(*) is optimized to return very quickly if the SELECT retrieves from one table,
no other columns are retrieved, and there is no WHERE clause. For example:
mysql> SELECT COUNT(*) FROM student;
This optimization only applies to MyISAM tables, because an exact row count is stored for this storage engine and can be accessed very quickly.
COUNT(1) is only subject to the same optimization if the first column is defined as NOT NULL.
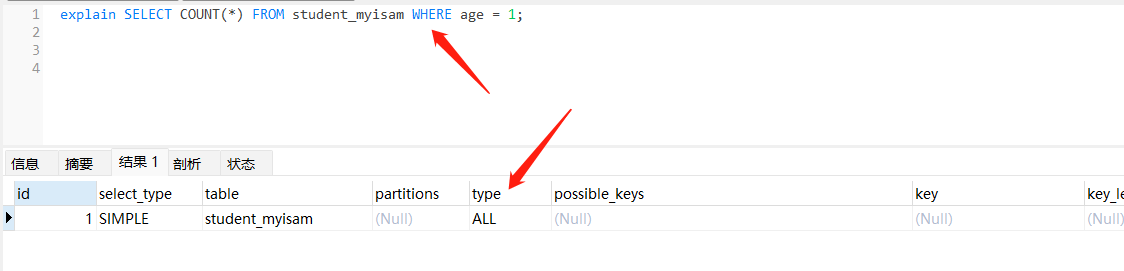
大致的意思是说,对于使用 MyISAM 存储引擎的表,如果一个COUNT(*) COUNT(n) 没有其它查询条件,或COUNT(field) 对应的列不为 NULL,则会很快返回计数结果。
其实这是因为 MyISAM 表的统计信息中有表的实际行数统计信息。不同于InnoDB中的字段只是一个估计值。
总结
上文中讨论了一些 count 函数的一些表现,并没有涉及 where 条件的使用,因为一旦引入 where 条件就会引入多个字段和多个字段的索引进行成本分析: