MatConvNet配置详解,吐血整理Win10+MATLAB2019a+VS2015+cuda11.0
一、准备工作
1、matconvnet深度学习工具包,我这里用的是最新版本matconvnet-1.0-beta25, matconvnet下载地址:Home - MatConvNet
下载好的文件解压,重命名为matconvnet放在C:\Program Files\Polyspace\R2019a\toolbox文件夹下
2、vs,推荐用VS2015及以上版本,我这里用的是VS2015,matconvnet在配置时需要用到这个软件里面的c++编译器,这里注意安装的时候要自定义安装勾选C++,不然不会生成cl.exe文件,如果忘记了也没事,安装好软件以后新建一个C++工程他就会自动生成cl.exe文件
3、matlab2019a(win64)
4、在安装cuda 11.0之前要先安装上自己显卡最新的官方驱动,驱动下载链接:
NVIDIA GeForce 驱动程序 - N 卡驱动 | NVIDIA
5、cuda+cudnn安装,默认路径安装(我这里使用的是cuda11.0,因为我的电脑显卡是RTX3060ti,网上说法是3060显卡只支持11.0以上的cuda算力),cuda版本和cudnn版本要一致,cuda下载连接CUDA Toolkit 11.8 Downloads | NVIDIA Developer
cudnn下载链接:Installation Guide :: NVIDIA Deep Learning cuDNN Documentation
二、matconvnet环境配置
1、cpu版本配置
输入命令mex -setup

运行vl_compilenn 程序,
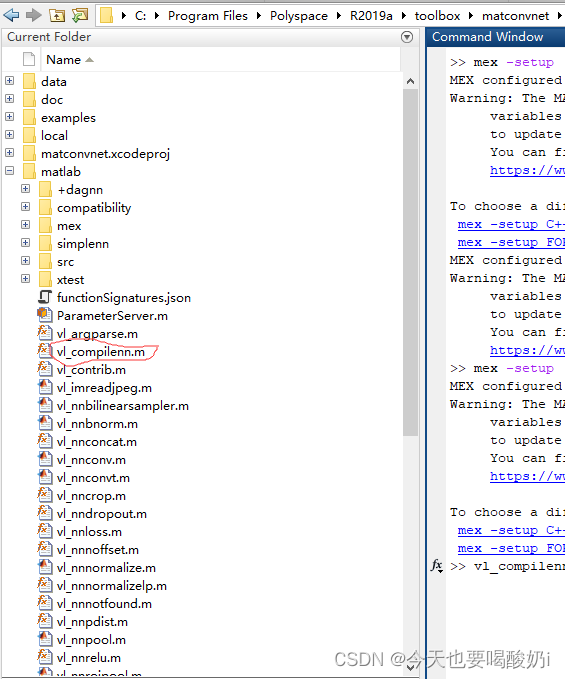
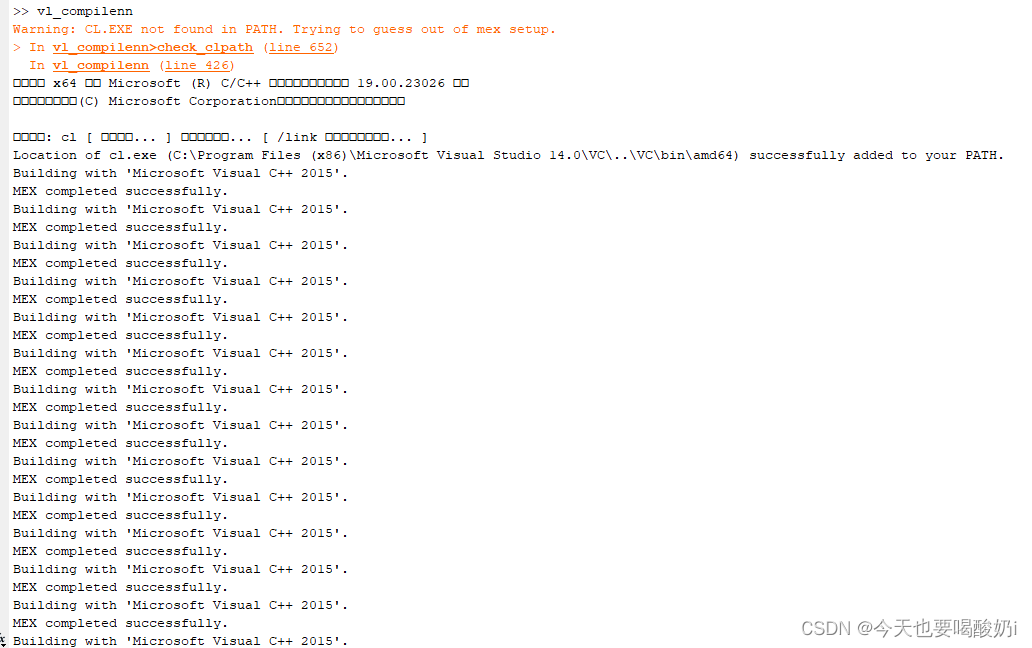
这样vl_compilenn 程序成功编译
在命令行窗口输入vl_testnn命令
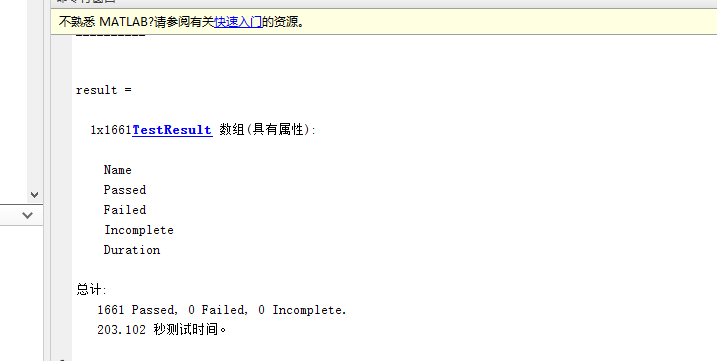
最后显示这个就成功了
2.配置GPU版本
(1)安装cuda,正常安装即可,没有特殊的要求,这里建议安装到默认路径,不要改变,防止之后填写环境变量的时候出现差错.
(2)设置环境变量:安装完毕后,在计算机上点右键,打开属性->高级系统设置->环境变量,可以看到系统中多了CUDA_PATH和CUDA_PATH_V11_0两个环境变量,接下来,还要在系统中添加以下几个环境变量:
如果是默认的CUDA安装路径,添加的路径分别是下面这样的:
CUDA_PATH
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0
CUDA_PATH_V11_0
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0
CUDA_SDK_PATH
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0
CUDA_LIB_PATH
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\lib\x64
CUDA_BIN_PATH
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\bin
CUDA_SDK_BIN_PATH
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0\bin\win64
CUDA_SDK_LIB_PATH
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v.11.0\common\lib\x64
(以上路径为可选添加)
然后,在系统变量 PATH 的末尾添加:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\lib\x64;(可选)
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\bin;(可选)
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0\common\lib\x64;(必须添加)
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0\bin\win64; (必须添加)
配置完环境变量重启一下电脑
(3)在matconvnet-1.0-beta25(建议重命名文件夹改为matconvnet)中建一个local文件夹(与example和matlab等同一”级别”),然后把下载的cudnn放进去,文件名一定要重命名成cudnn,如下图所示:
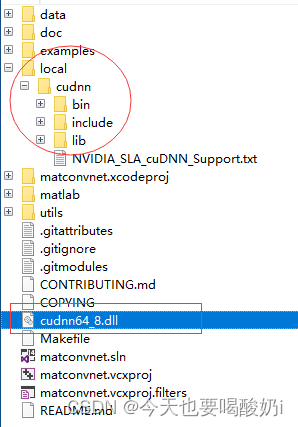
cudnn64_8.dll是cudnn文件夹下bin目录里的
把cudnn中的bin,lib/x64,include中的文件分别拷贝至
C:\Program Files\NVIDIA GPU ComputingToolkit\CUDA\v11.0中的bin,lib/x64,include三个子目录下。注意这里千万不要把cudnn的三个文件夹直接复制替换cuda中的三个文件夹,只是将cudnn对应文件夹下的文件替换cuda\V11.0下的对应文件夹下的文件
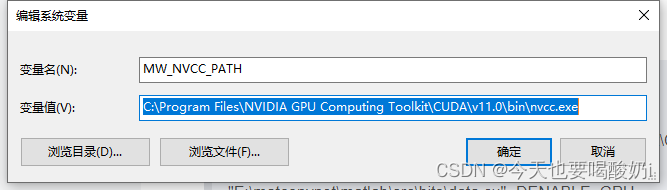
(5)将nvcc路径加入环境变量中:
MW_NVCC_PATH:C:\ProgramFiles\NVIDIA GPU Computing Toolkit\CUDA\v11.0\bin\nvcc.exe
重新编译vl_compilenn程序,输入命令vl_compilenn('enableGpu',true):
会出现如下错误:
nvcc fatal : '-DNDEBUG': expected a number
错误使用 vl_compilenn>nvcc_compile (line 615)
Command "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin\nvcc" -c -o
"E:\matconvnet\matlab\mex\.build\bits\data.obj"
"E:\matconvnet\matlab\src\bits\data.cu" -DENABLE_GPU
-DENABLE_DOUBLE -O -DNDEBUG -D_FORCE_INLINES --std=c++11 -I"D:\Softwares\MATLAB\extern\include"
-I"D:\Softwares\MATLAB\toolbox\distcomp\gpu\extern\include" -gencode=arch=compute_75,code=\"sm_75,compute_75\" --compiler-options=/MD
--compiler-bindir="D:\Softwares\VisualStudio\VC\Tools\MSVC\14.16.27023\bin\Hostx64" failed.
出错 vl_compilenn (line 487)
nvcc_compile(opts, srcs{i}, objfile, flags) ;
错误原因:
CUDA 10.1以前的版本使用非debug模式下GPU优化指令是-O,CUDA 10.1以上版本把-O指令给弃用了。
现在的指令为-O+数字,此处的数字为优化的等级。vl_compilenn默认编译是非debug模式的,所以matlab会提示我们需要一个数字。
解决方法:
1)使用debug运行vl_compilenn,这种方法会导致性能损失,不可取。
2)将优化指令-O改为-O+数字。
更改方法如下:
将vl_compilenn.m,将606行的nvcc_compile函数
function nvcc_compile(opts, src, tgt, flags)
% --------------------------------------------------------------------
if check_deps(opts, tgt, src), return ; end
nvcc_path = fullfile(opts.cudaRoot, 'bin', 'nvcc');
nvcc_cmd = sprintf('"%s" -c -o "%s" "%s" %s ', ...
nvcc_path, tgt, src, ...
strjoin(horzcat(flags.base,flags.nvcc)));
opts.verbose && fprintf('%s: NVCC CC: %s\n', mfilename, nvcc_cmd) ;
status = system(nvcc_cmd);
if status, error('Command %s failed.', nvcc_cmd); end;
改为
function nvcc_compile(opts, src, tgt, flags)
% --------------------------------------------------------------------
mybase=flags.base;
mybase(3)={'-O3'};
if check_deps(opts, tgt, src), return ; end
nvcc_path = fullfile(opts.cudaRoot, 'bin', 'nvcc');
nvcc_cmd = sprintf('"%s" -c -o "%s" "%s" %s ', ...
nvcc_path, tgt, src, ...
strjoin(horzcat(mybase,flags.nvcc)));
opts.verbose && fprintf('%s: NVCC CC: %s\n', mfilename, nvcc_cmd) ;
status = system(nvcc_cmd);
if status, error('Command %s failed.', nvcc_cmd); end;
更改为第3、4、9行。
注意对比,我们使用指令为“-O3”,即默认优化等级为3,也可以改为自己想优化的等级
再次运行vl_compilenn('enableGpu', true)
遇到如下错误:
错误使用 mex
'E:\matconvnet\matlab\mex\vl_nnconv.mexw64' 使用了 '-R2018a' 进
行编译并与 '-R2017b' 链接在一起。 有关详细信息,请参阅 MEX 文件使用了一个 API 进行编译并与另一个 API 链接在一起。
出错 vl_compilenn>mex_link (line 629)
mex(args{:}) ;
出错 vl_compilenn (line 500)
mex_link(opts, objs, flags.mex_dir, flags)
解决方法:将vl_compilenn.m中的largeArrayDims全部替换为lmwblas,一共三处。
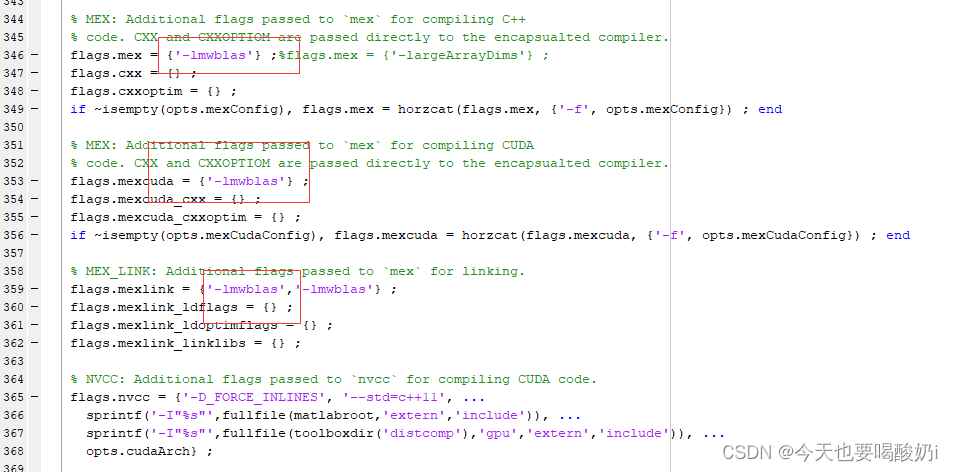
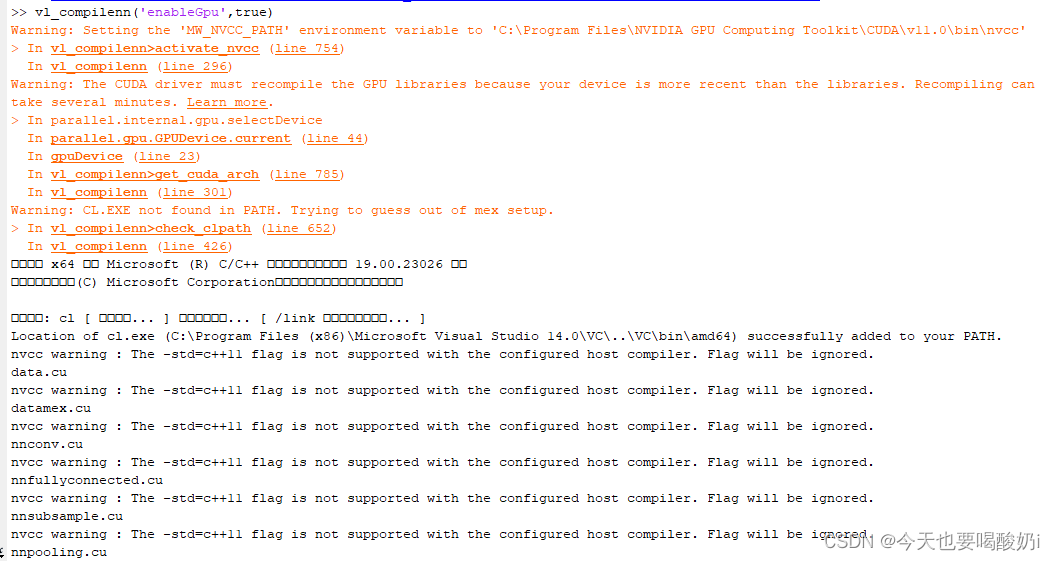
再次运行vl_compilenn('enableGpu', true)
编译成功。
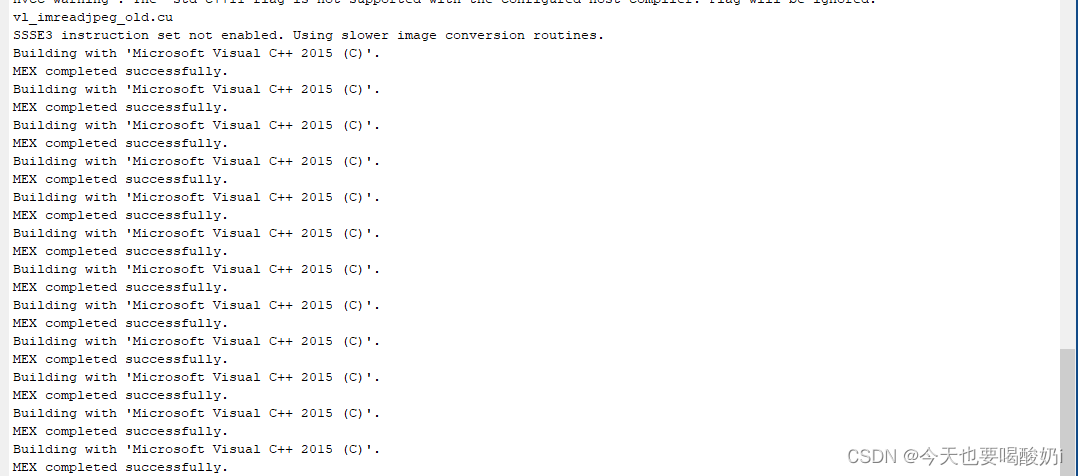
在命令行窗口输入vl_testnn('gpu', true),
这样GPU版本就成功了
参考文章
链接:https://blog.csdn.net/qq_33782064/article/details/80003520
链接:https://blog.csdn.net/qq_17783559/article/details/105474663