Python爬虫——新手使用代理ip详细教程
Python代理IP爬虫是一种可以让爬虫拥有更多网络访问权限的技术。代理IP的作用是可以为爬虫提供多个IP地址,从而加快其爬取数据的速度,同时也可以避免因为访问频率过高而被网站封禁的问题。本文将介绍如何使用Python实现代理IP的爬取和使用。
一、代理IP的获取
首先我们需要找到一个可用的代理IP源。这里我们以站大爷代理ip为例,站大爷代理提供了收费代理和普通免费的代理IP,使用起来非常方便。
站大爷代理ip的API接口地址:https://www.zdaye.com/free/inha/1/
通过请求上面的API接口,我们可以获取到一页代理IP信息,包括IP地址和端口号。我们可以通过requests库的get方法获取到API返回的信息,示例代码如下:
import requests
url = 'https://www.zdaye.com/free/inha/1/'
response = requests.get(url)
print(response.text)
上面代码执行后,我们可以看到获取到的代理IP信息。但是我们需要对返回值进行解析,只提取出有用的IP地址和端口。
import requests
from bs4 import BeautifulSoup
url = 'https://www.zdaye.com/free/inha/1/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
proxies = []
for tr in soup.find_all('tr')[1:]:
tds = tr.find_all('td')
proxy = tds[0].text + ':' + tds[1].text
proxies.append(proxy)
print(proxies)
上面代码中,我们使用BeautifulSoup库对返回的HTML文本进行解析,获取到所有的<tr>标签,然后通过循环遍历每一个<tr>标签,提取出其中的IP地址和端口信息,并将其保存到一个列表中。
二、代理IP的验证
获取到代理IP后,我们需要进行测试,判断这些代理IP是否可用。这里我们通过requests库的get方法进行测试,如果返回200则说明该代理IP可用。我们使用代理IP的方法是通过向requests.get方法传入proxies参数来实现,示例代码如下:
import requests
url = 'http://www.baidu.com'
proxies = {
'http': 'http://222.74.237.246:808',
'https': 'https://222.74.237.246:808',
}
try:
response = requests.get(url, proxies=proxies, timeout=10)
if response.status_code == 200:
print('代理IP可用:', proxies)
except:
print('代理IP不可用:', proxies)
在上面的代码中,我们向http://www.baidu.com发送请求,并使用了一个代理IP进行访问。如果返回HTTP状态码为200,则说明代理IP可用,否则说明不可用。
如果我们需要验证每一个代理IP,那么就需要对上面的代码进行循环遍历,例如:
import requests
from bs4 import BeautifulSoup
url = 'https://www.zdaye.com/free/inha/1/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
proxies = []
for tr in soup.find_all('tr')[1:]:
tds = tr.find_all('td')
proxy = tds[0].text + ':' + tds[1].text
proxies.append(proxy)
for proxy in proxies:
proxies_dict = {
'http': 'http://' + proxy,
'https': 'https://' + proxy,
}
try:
response = requests.get(url, proxies=proxies_dict, timeout=10)
if response.status_code == 200:
print('代理IP可用:', proxies_dict)
except:
print('代理IP不可用:', proxies_dict)
上面的循环代码中,我们先遍历了所有的代理IP,然后对每一个代理IP进行验证。如果该代理IP可用,则打印出来,否则输出不可用信息。
三、代理IP的测试
获取到可用的代理IP后,我们需要对其进行进一步的测试,确保其真正可用,然后再进行爬取。我们可以使用百度、360搜索等常用搜索引擎进行测试。在这里我们以百度为例,测试代理IP是否真正可用。
import requests
url = 'http://www.baidu.com'
proxies = {
'http': 'http://222.74.237.246:808',
'https': 'https://222.74.237.246:808',
}
try:
response = requests.get(url, proxies=proxies, timeout=10)
if response.status_code == 200:
if '百度一下' in response.text:
print('代理IP可用:', proxies)
else:
print('代理IP不可用:', proxies)
else:
print('代理IP不可用:', proxies)
except:
print('代理IP不可用:', proxies)
上面代码中,我们向百度发送了一个请求,并通过判断返回的HTML页面中是否含有‘百度一下’这个关键字来验证代理IP是否真正可用。
四、代理IP的使用
当我们获取到了可用的代理IP后,我们就可以使用它们来进行爬取了。在使用代理IP进行爬取时,我们需要将其作为proxies参数传入requests.get方法中,示例代码如下:
import requests
url = 'http://www.baidu.com'
proxies = {
'http': 'http://222.74.201.49:9999',
'https': 'https://222.74.201.49:9999',
}
response = requests.get(url, proxies=proxies)
print(response.text)
上面代码中,我们使用了一个代理IP进行访问百度网站,并将其作为proxies参数传入requests.get方法中。如果该代理IP可用,则请求将会使用该代理IP进行访问。
五、完整代码
下面是一份完整的代码,包括代理IP的获取、验证、测试和使用,大家可以参考一下:
import requests
from bs4 import BeautifulSoup
# 1. 获取代理IP列表
def get_proxy_list():
# 构造请求头,模拟浏览器请求
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"
}
# 请求代理IP网页
url = "http://www.zdaye.com/"
response = requests.get(url, headers=headers)
# 解析网页获取代理IP列表
soup = BeautifulSoup(response.text, "html.parser")
proxy_list = []
table = soup.find("table", {"id": "ip_list"})
for tr in table.find_all("tr"):
td_list = tr.find_all("td")
if len(td_list) > 0:
ip = td_list[1].text.strip()
port = td_list[2].text.strip()
type = td_list[5].text.strip()
proxy_list.append({
"ip": ip,
"port": port,
"type": type
})
return proxy_list
# 2. 验证代理IP可用性
def verify_proxy(proxy):
# 构造请求头,模拟浏览器请求
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"
}
# 请求目标网页并判断响应码
url = "http://www.baidu.com"
try:
response = requests.get(url, headers=headers, proxies=proxy, timeout=5)
if response.status_code == 200:
return True
else:
return False
except:
return False
# 3. 测试代理IP列表可用性
def test_proxy_list(proxy_list):
valid_proxy_list = []
for proxy in proxy_list:
if verify_proxy(proxy):
valid_proxy_list.append(proxy)
return valid_proxy_list
# 4. 使用代理IP发送请求
def send_request(url, headers, proxy):
# 发送请求并返回响应结果
response = requests.get(url, headers=headers, proxies=proxy)
return response.text
# 程序入口
if __name__ == "__main__":
# 获取代理IP列表
proxy_list = get_proxy_list()
# 验证代理IP可用性
valid_proxy_list = test_proxy_list(proxy_list)
# 输出可用代理IP
print("有效代理IP列表:")
for proxy in valid_proxy_list:
print(proxy)
# 使用代理IP发送请求
url = "http://www.baidu.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"
}
proxy = {
"http": "http://" + valid_proxy_list[0]["ip"] + ":" + valid_proxy_list[0]["port"],
"https": "https://" + valid_proxy_list[0]["ip"] + ":" + valid_proxy_list[0]["port"]
}
response = send_request(url, headers, proxy)
print(response)
在上面的代码中,我们首先通过爬取西刺代理网站获取代理IP列表。然后,我们对每一个代理IP进行验证,判断其是否可用,并将可用的代理IP存入一个列表中。最后,我们选择一个可用的代理IP,并使用该代理IP发送请求。
六、总结
本文介绍了代理IP的基本概念、免费代理IP获取方法、Python使用代理IP的方法及示例代码,以及代理IP使用的注意事项。希望能够对爬虫的使用者有所帮助。
题外话
当下这个大数据时代不掌握一门编程语言怎么跟的上脚本呢?当下最火的编程语言Python前景一片光明!如果你也想跟上时代提升自己那么请看一下.
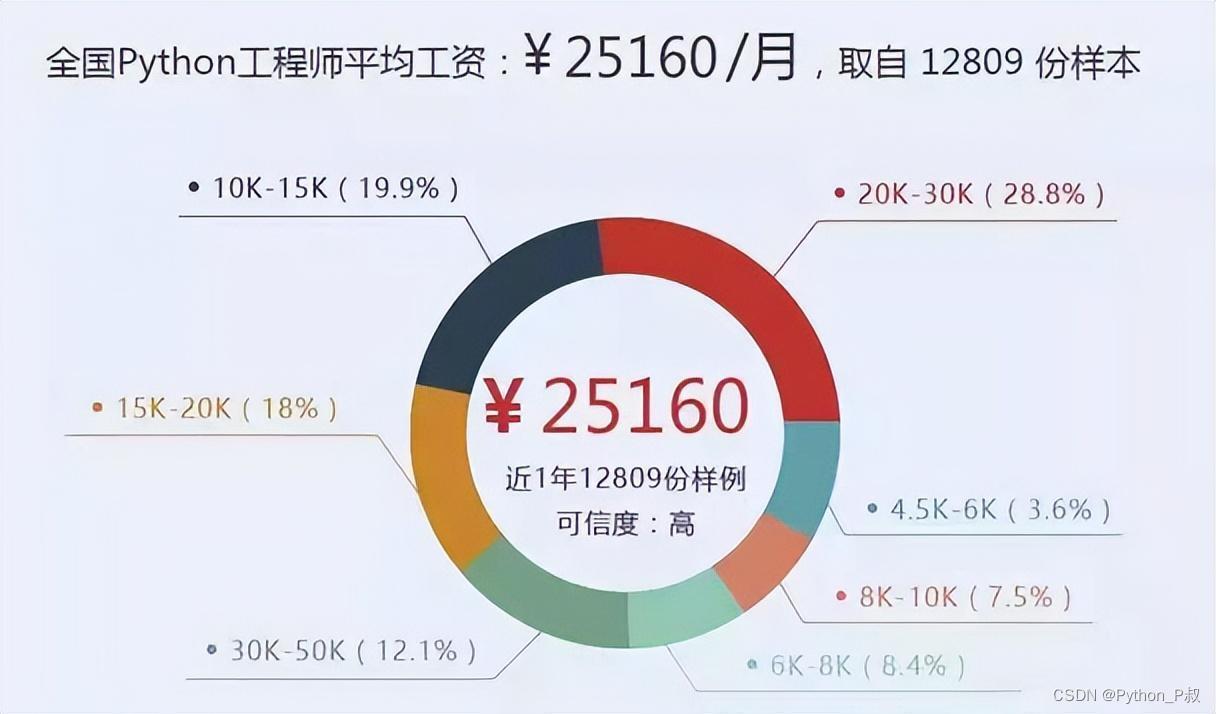
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
一、Python所有方向的学习路线
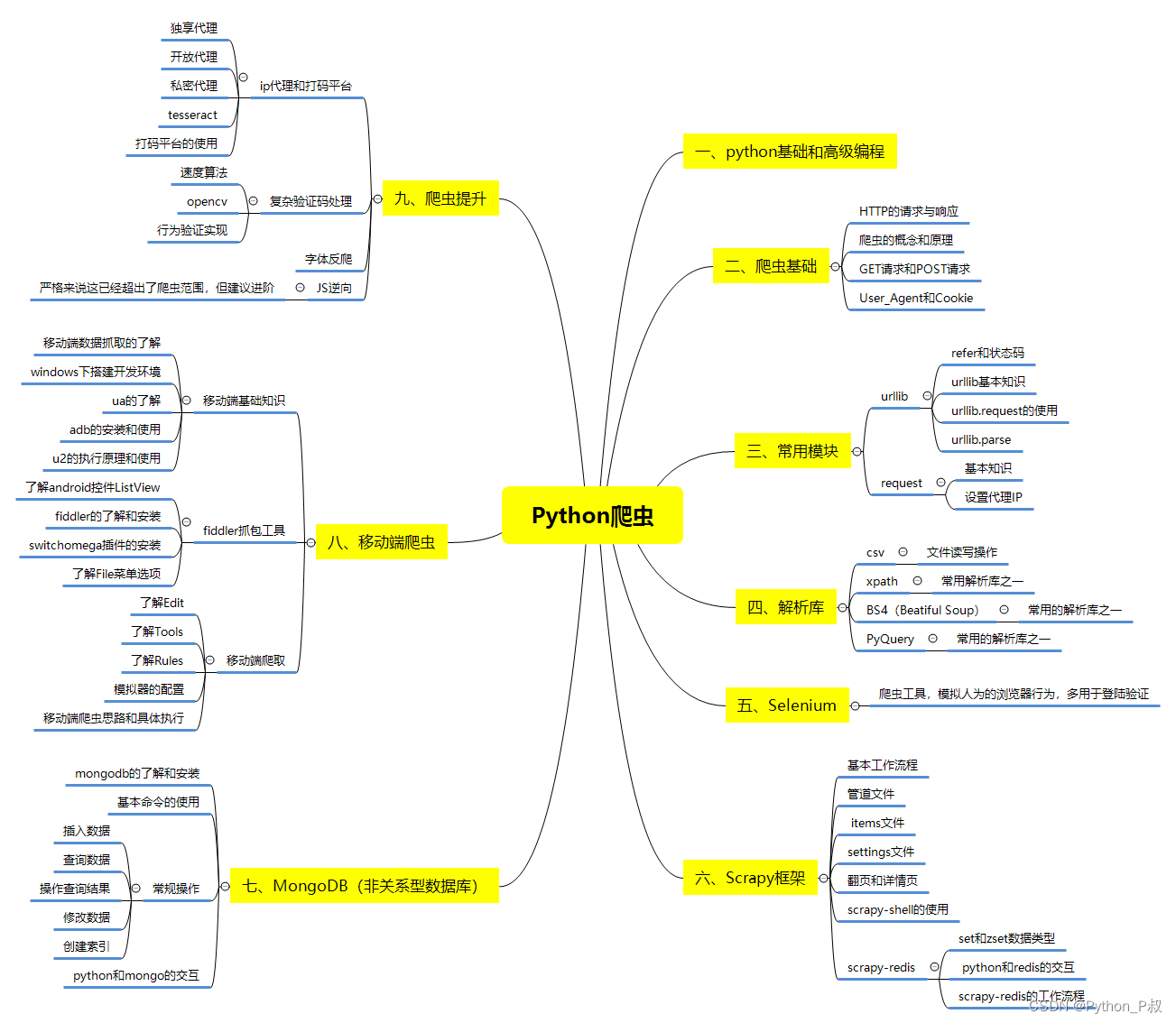
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典
简历模板
👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
若有侵权,请联系删除