GoogleNet v1结构和代码复现
1 大致结构
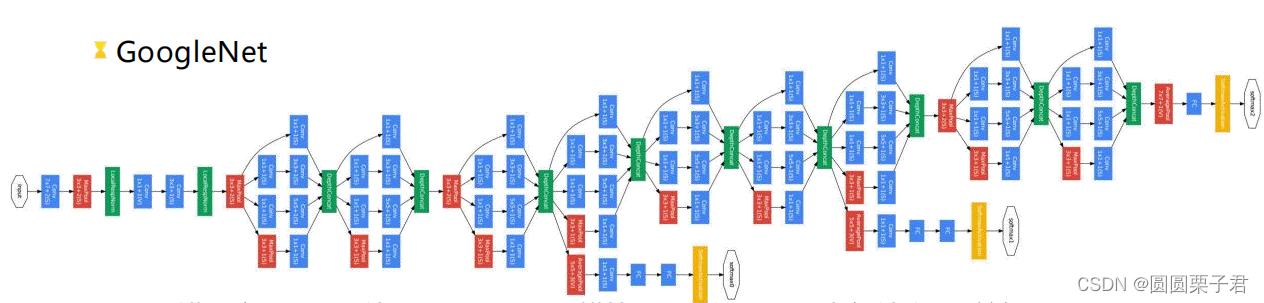
Top5错误率6.7%; 使用9个inception模块, 改变CNN原串行结构, 并行, 共22层;
使用平均池化替代FC层; 参数量仅为AlexNet的1/12; 使用softmax获取平均结果;
网络结构的更新, 性能比AlexNet要好; 2014年ILSVRC冠军。
下面是他的具体参数
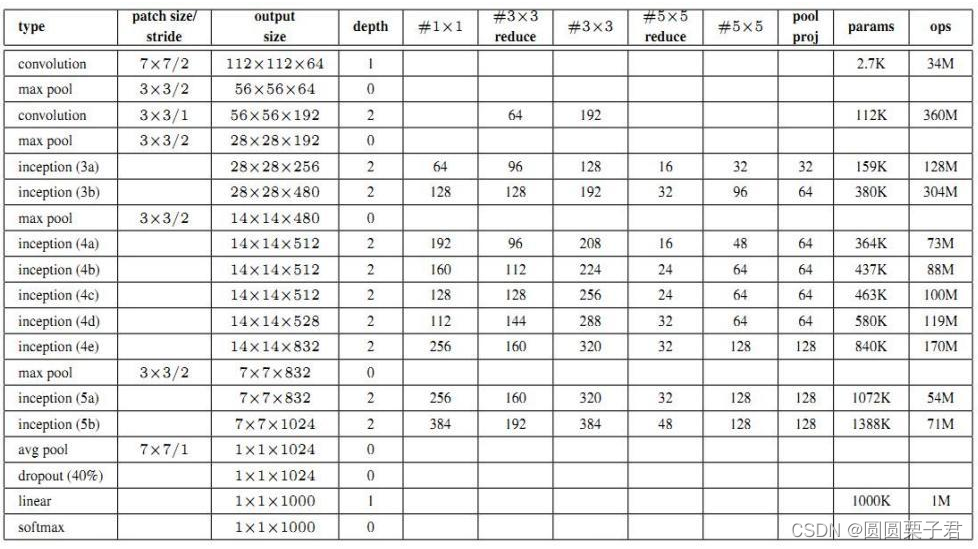
其实感觉对于GoogleNet结构除了inception结构和多出来的两个输出结构并没有什么好介绍的,具体介绍下inception结构,和那两个输出结构
2 inception结构
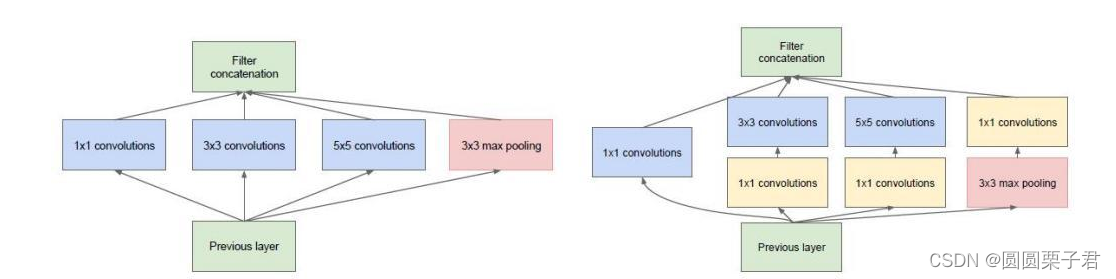
inception结构,就是将上述的四种卷积的结构进行concat通道合并输出到下一个inception
在原图中,inception结构是右图模样,有人会好奇,加不加1x1卷积有什么区别吗,其实整体感受效果是差不多,主要在于计算量上,先通过1x1来降维使通道压缩,然后再3x3卷积,会减少不少的计算量。
3 两个额外输出结构
主要是网络层次越深,容易导致梯度消失,或者梯度很小反向传播效果不好,导致模型学习能力不强,就添加了两个分支,这两个分支,因为输出的时候层次还不深,所以梯度不会很小,通过这两个分支的反向传播,增加模型的学习能力。
4 代码复现
import torch
import torch.nn as nn
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.relu = nn.ReLU()
def forward(self, x):
return self.relu(self.conv(x))
class Inception(nn.Module):
def __init__(self, in_channels, out_channels):
"""
:param in_channels: 输入通道数目, eg: 192
:param out_channels: 各个分支的输出通道数目, eg: [[64], [96,128], [16,32], [32]]
"""
super(Inception, self).__init__()
self.branch1 = nn.Sequential(
BasicConv2d(in_channels, out_channels[0][0], kernel_size=1, stride=1, padding=0)
)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, out_channels[1][0], kernel_size=1, stride=1, padding=0),
BasicConv2d(out_channels[1][0], out_channels[1][1], kernel_size=3, stride=1, padding=1)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, out_channels[2][0], kernel_size=1, stride=1, padding=0),
BasicConv2d(out_channels[2][0], out_channels[2][1], kernel_size=5, stride=1, padding=2)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(3, 1, padding=1),
BasicConv2d(in_channels, out_channels[3][0], kernel_size=1, stride=1, padding=0)
)
def forward(self, x):
"""
inception前向过程
:param x: [N,C,H,W]
:return:
"""
x1 = self.branch1(x) # [N,C,H,W] -> [N,C1,H,W]
x2 = self.branch2(x) # [N,C,H,W] -> [N,C2,H,W]
x3 = self.branch3(x) # [N,C,H,W] -> [N,C3,H,W]
x4 = self.branch4(x) # [N,C,H,W] -> [N,C4,H,W]
x = torch.concat([x1, x2, x3, x4], dim=1) # [N,C1+C2+C3+C4,H,W]
return x
class GoogLeNet(nn.Module):
def __init__(self, num_classes, add_aux_stage=False):
super(GoogLeNet, self).__init__()
self.stage1 = nn.Sequential(
BasicConv2d(3, 64, 7, 2, 3),
nn.MaxPool2d(3, 2, padding=1),
BasicConv2d(64, 64, 1, 1, 0),
BasicConv2d(64, 192, 3, 1, 1),
nn.MaxPool2d(3, 2, padding=1),
Inception( 192,[[64], [96, 128], [16, 32], [32]]), # inception3a
Inception(256, [[128], [128, 192], [32, 96], [64]]), # inception3b
nn.MaxPool2d(3, 2, padding=1),
Inception(480, [[192], [96, 208], [16, 48], [64]]) # inception4a
)
self.stage2 = nn.Sequential(
Inception(512, [[160], [112, 224], [24, 64], [64]]), # inception4b
Inception(512, [[128], [128, 256], [24, 64], [64]]), # inception4c
Inception(512, [[112], [144, 288], [32, 64], [64]]) # inception4d
)
self.stage3 = nn.Sequential(
Inception(528, [[256], [160, 320], [32, 128], [128]]), # inception4e
nn.MaxPool2d(3, 2, padding=1),
Inception(832, [[256], [160, 320], [32, 128], [128]]), # inception5a
Inception(832, [[384], [192, 384], [48, 128], [128]]), # inception5b
nn.AdaptiveAvgPool2d()
)
self.classify = nn.Conv2d(1024, num_classes, kernel_size=(1, 1), stride=(1, 1), padding=0)
if add_aux_stage:
self.aux_stage1 = nn.Sequential(
nn.MaxPool2d(5, 3, padding=0),
nn.Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), padding=0),
nn.ReLU(),
nn.AdaptiveAvgPool2d(output_size=(2, 2)),
nn.Flatten(1),
nn.Linear(4096, 2048),
nn.Dropout(p=0.4),
nn.ReLU(),
nn.Linear(2048, num_classes)
)
self.aux_stage2 = nn.Sequential(
nn.MaxPool2d(5, 3, padding=0),
nn.Conv2d(528, 1024, kernel_size=(1, 1), stride=(1, 1), padding=0),
nn.ReLU(),
nn.AdaptiveAvgPool2d(output_size=(2, 2)),
nn.Flatten(1),
nn.Linear(4096, 2048),
nn.Dropout(p=0.4),
nn.ReLU(),
nn.Linear(2048, num_classes)
)
else:
self.aux_stage1 = None
self.aux_stage2 = None
def forward(self, x):
"""
前向过程
:param x: [N,3,H,W]
:return:
"""
z1 = self.stage1(x) # [N,3,H,W] -> [N,512,H1,W1]
z2 = self.stage2(z1) # [N,512,H1,W1] -> [N,528,H2,W2]
z3 = self.stage3(z2) # [N,528,H2,W2] -> [N,1024,1,1]
# 三个决策分支的输出
# scores3 = self.classify(z3)[:, :, 0, 0] # [N,1024,1,1] -> [N,num_classes,1,1] -> [N,num_classes]
scores3 = torch.squeeze(self.classify(z3)) # [N,1024,1,1] -> [N,num_classes,1,1] -> [N,num_classes]
if self.aux_stage1 is not None:
scores1 = self.aux_stage1(z1)
scores2 = self.aux_stage2(z2)
return scores1, scores2, scores3
else:
return scores3