BEV感知(1)--BEV感知算法
目录
一、BEV感知算法
BEV(Bird's Eye View)即鸟瞰图,通过使用摄像头,雷达,激光雷达等收集数据,通过计算机视觉、深度学习、机器学习等技术对数据进行处理和分析,从而实现对交通、障碍物、道路条件等信息的感知和识别,主要应用于自动驾驶领域。
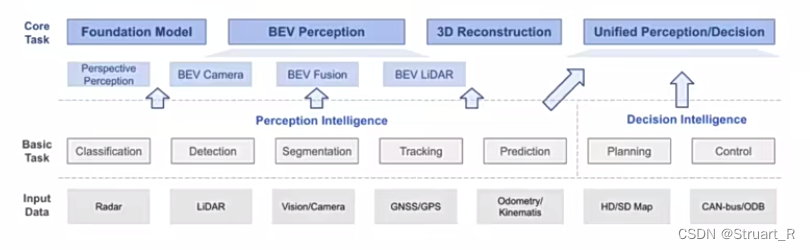
1、BEV感知
BEV感知是一个建立在众多子任务上的一个概念,包括分类、检测、分割、跟踪、预测、规划等,通过使用鸟瞰图来进行各项计算机视觉相关任务。
BEV感知输入:毫米波雷达(Radar)、激光雷达点云(LiDAR)、相机图像等,依据输入的不同,BEV感知算法有进一步的划分。
对于BEV感知任务中一般有BEV Camera(图像),BEV Fusion(图像和点云融合),BEV LiDAR(点云)三种方式。
2、BEV算法数据形式
BEV算法数据形式一般有纯图像、点云、图像点云融合三种形式。
(1)纯图像
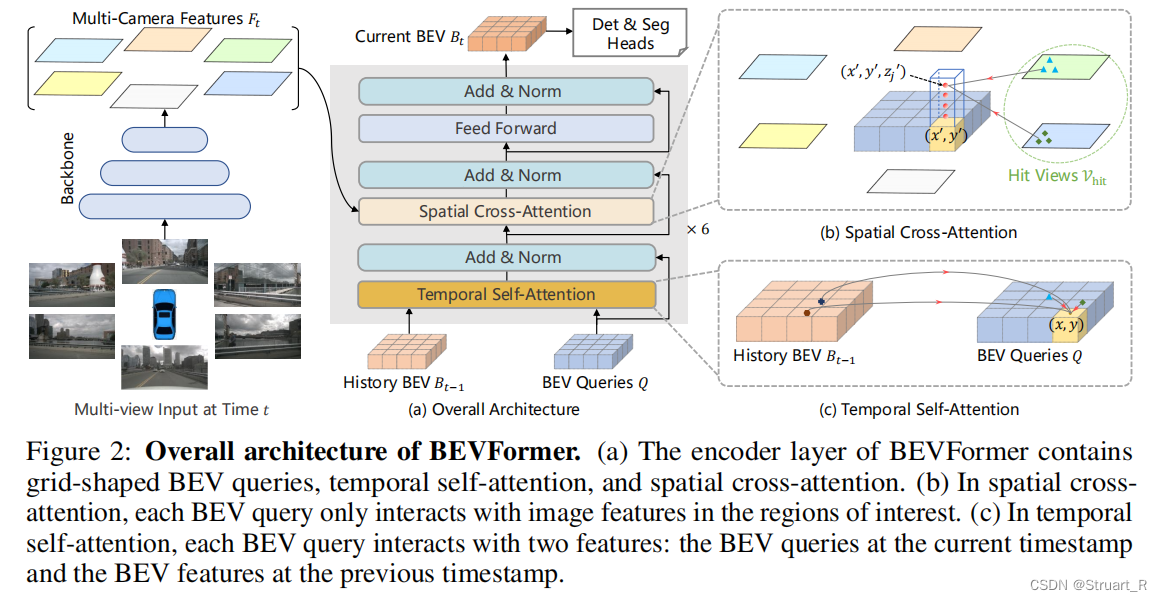
纯图像的输入一般就是BEVCamera感知模型,是完全基于车载摄像机的图像进行提取特征,感知当前场景的车辆、行人等任务的。其中介绍一个最为典型的BEVCamera——BEVFormer。
BEVFormer利用了基于transformer的Encoder,通过网格形式的BEV queries来利用空间和时间进行交互,从而设计可学习的BEV和注意力模块,在nuScenes测试集上对3D目标检测和地图分割任务中实现最优性能。
下图为BEVFormer的完整网络结构,输入多视角图像,经过backbone(一般为Resnet)之后,经过提取网络(前馈网络+时空注意力机制模块)得到BEV特征,最后接一个图像分割或检测的头组成完整的网络输出。
(2)点云
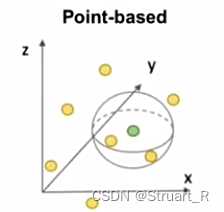
点云就是场景中若干点的组成集合,具有稀疏性、无序性,是一种3D表征,一般来说,点云是通过激光雷达对场景扫描得到的,下图为一个场景的点云图。

对于点云问题,由于点过于稀疏,数量巨大,一般有两种处理方法(聚合方法),分别是Point-based和Voxel-based。
Point-based处理点云数据,可以处理高密度的点云数据,更加灵活,但计算复杂度高,不规则性高。
Voxel-based处理体素数据,使数据结构更加规则,更好的表示体积信息,但收到网格限制,会丢失部分信息。

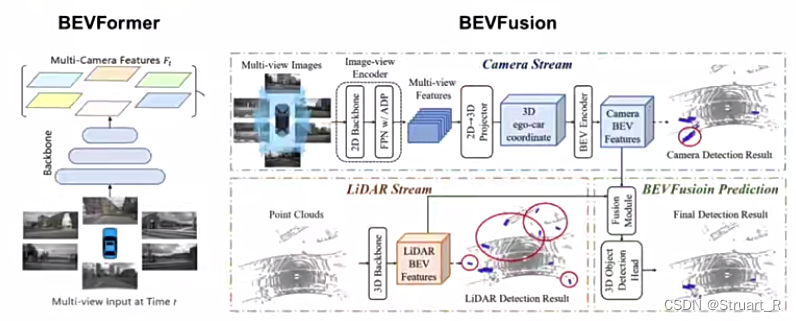
(3)图像和点云融合
下图为纯图像提取特征和Fusion形式的提取特征的比较,BEVFusion的特征是将Camera格式和LiDAR格式分别提取得到BEV特征后再进行融合。
二、BEV开源数据集
1、KITTI
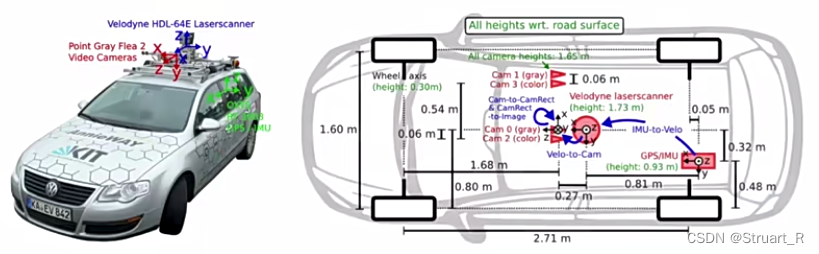
KITTI数据集通过车载相机、激光雷达等传感器进行采集,采集自德国卡尔斯鲁厄街道,数据规模为14999张图像及其对应点云,其中7481张训练集,7518张测试集,KITTI数据集标注了车、行人、骑车的人三类,共计80256个标注对象,下图为标注平台。

在官方论文中可以了解到,标注平台的传感器并不是统一坐标系的,存在R、T关系,另外对于摄像机的外参数做了统一。
KITTI数据表示法:
(1)第1字节 Pedestrian代表行人
(2)第2字节 “0.00” 表示是否被截断,处于0~1范围内,越大被截断遮挡的程度越大
(3)第3字节 “0” 表示行人不存在遮挡,离散值0(不存在遮挡),1(部分遮挡),2(严重遮挡),3(不确定)
(4)第4字节 “-0.20” 角度信息
(4)第5-8字节 “712.40, 143.00” 2D平面左上角坐标,“810.73 307.92”2D平面右下角坐标
(5)第9-11字节 “1.89 0.48 1.20” 3D平面上的高宽长(h,w,l),单位m
(6)第12-14字节 “1.84 1.47 8.41” 3D平面的坐标
(7)第15字节 “0.01” 置信度

2、nuScenes
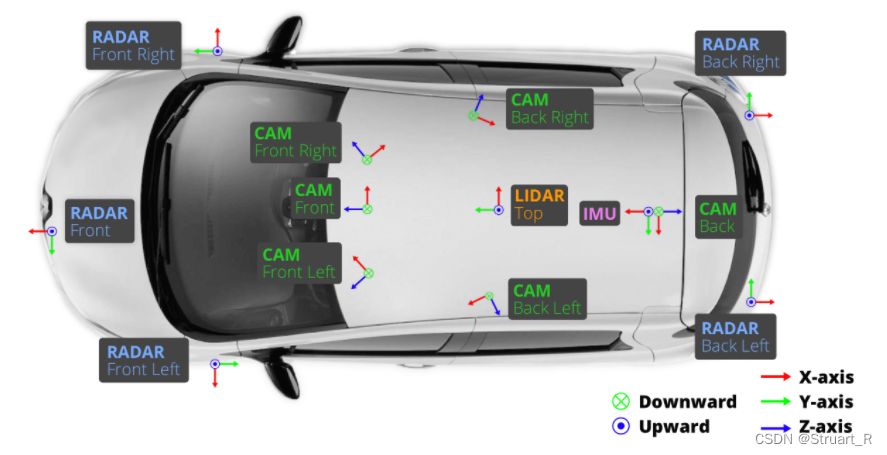
nuScenes要比KITTI数据集更加丰富一些,nuScenes采集了不同城市中的1000个场景,传感器系统包括6个摄像机、5个毫米波雷达、1个激光雷达、六轴传感器IMU和GPS。
nuScenes数据包含140万个相机图像、39万个激光雷达扫描结果、140万个毫米波雷达扫描结果,标注了32类共计140万个标注对象。
详细的介绍请看:对Nuscenes数据集一无所知,手把手带你玩转Nuscenes数据集_nuscenes数据集token作用

nuScenes数据集格式:maps、samples、sweeps、v1.0-*。
maps:所有地图文件的文件夹,光栅化的png图像和矢量化的json文件用于后续决策,不用于检测和分割。
samples:关键帧样本的传感器数据,已标注图像
sweeps:中间帧传感器数据,未标注数据
v1.0-*:其余json表

三、BEV感知方法
1、BEV LiDAR
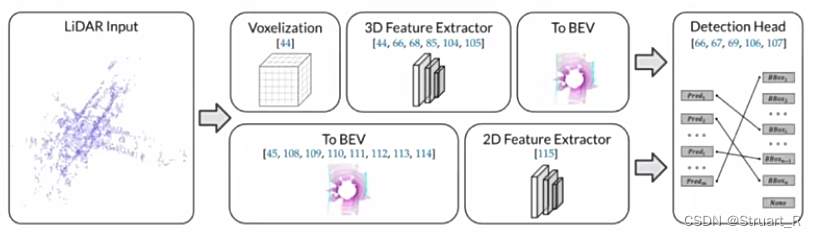
BEV LiDAR模式分为Pre-BEV(先提取特征,再生成BEV特征,代表算法PV-RCNN),Post-BEV(先转换为BEV特征,再提取特征,代表算法PointPillar)。下图为两种模式。
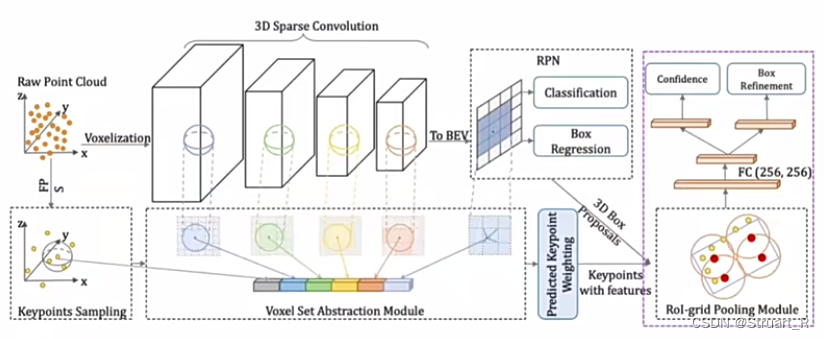
PV-RCNN网络:
以点云输入,提取BEV特征,应用于分割与检测。点云经过通过3D稀疏网络提取体素特征,通过关键点采样提取点特征,并将体素特征和点特征融合得到BEV特征,再PV-RCNN网络中得到BEV特征是简单的将3D点云向2D方向做投影得到BEV特征。
2、BEV Camera
BEV Camera模型输入相机图像,通过2D特征提取网络(特征共享),2D-3D视角转换网络(转换到3D可以看到俯视图),3Ddecoder检测模块,可以对照上面的BEV Former来看这三个模块。
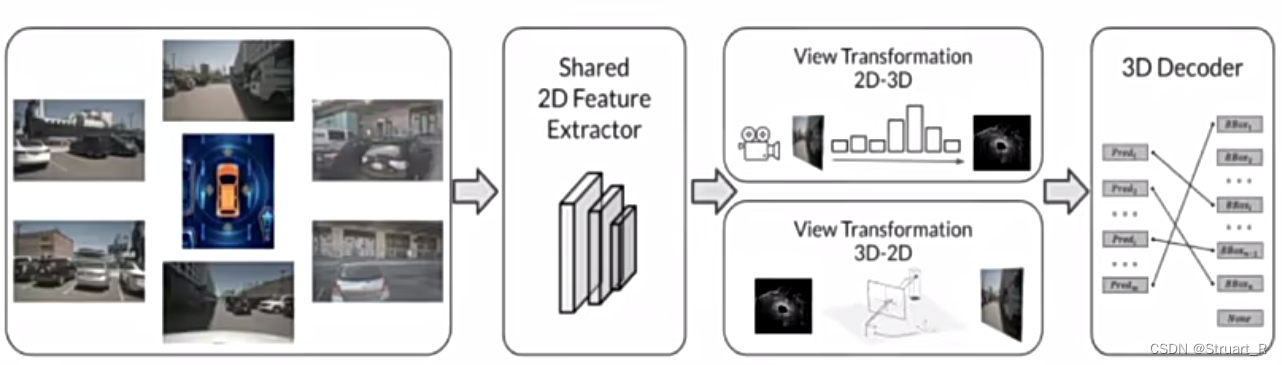
3、BEV Fusion
BEV主体模块分为2D图像处理流程,3D点云处理流程,BEV融合感知流程。BEV Fusion的重点在于如何进行融合,融合于两者提取BEV特征后,得到融合的BEV特征。
四、BEV感知算法优劣
对比通用3D检测结构和BEV感知结构,3D检测将2D转换到3D与3D点云相融合进行提取,而BEV感知结构将2D和3D转换为BEV结构进行融合。
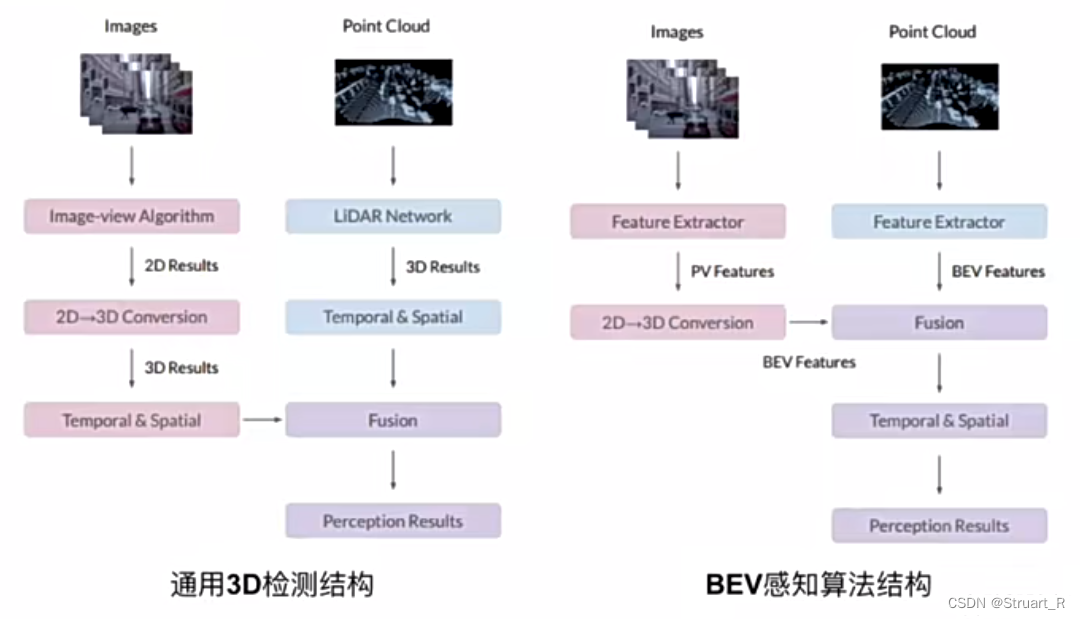
BEV感知算法可以对于2D图像的尺度变化和遮挡问题影响小,有利于利用视觉图像远距离识别物体,可以通过多使用Camera减少LiDAR的使用来降低成本,但在3D检测任务中仍然比现有的点云方案有一定差距。
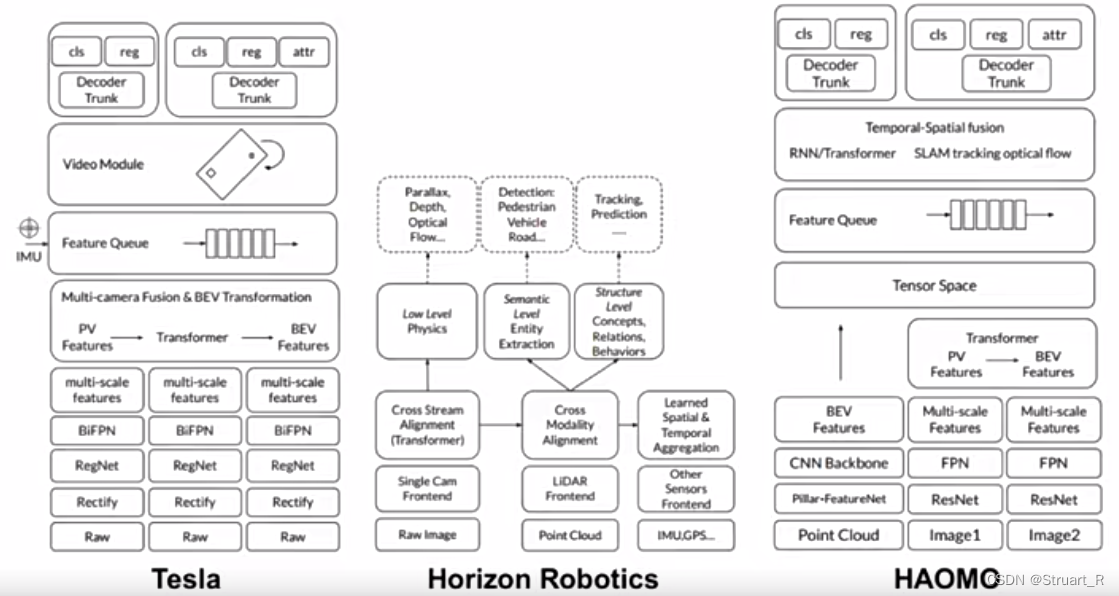
下图为Tesla、地平线、毫末对BEV感知的网络结构搭建。
参考视频:自动驾驶之心的BEV相关课程