【论文简述】Multi-sensor large-scale dataset for multi-view 3D reconstruction(CVPR 2023)
一、论文简述
1. 第一作者:Oleg Voynov
2. 发表年份:2023
3. 发表期刊:CVPR
4. 关键词:三维重建、数据集、多传感器
5. 探索动机:商品硬件越来越多地提供多传感器数据。使用来自不同传感器的数据,特别是RGB-D数据,有可能大大提高3D重建的质量。例如,多视图立体算法从RGB数据生成高质量的3D几何图形,但可能会错过无特征的表面;用深度传感器数据补充RGB图像可以获得更完整的重建。相反,商品深度传感器往往缺乏RGB相机提供的分辨率。
6. 工作目标:基于学习的技术极大地简化了组合来自多个传感器的数据的挑战性任务。然而,学习方法需要合适的数据进行训练。本数据集旨在补充现有的数据集,最重要的是,通过为具有挑战性反射特性的物体提供多传感器数据和高精度真值。
7. 核心思想:提出了一种新的多传感器数据集,用于多视图三维表面重建。它包括来自不同分辨率和模式的传感器的注册RGB和深度数据:智能手机,英特尔RealSense,微软Kinect,工业相机和结构光扫描仪。场景的选择是为了强调对现有算法具有挑战性的各种材料属性。提供在14种照明条件下,从100个观看方向获取107个不同场景的140万张图像。我们期望我们的数据集将对三维重建算法的评估和训练以及相关任务有用。
8. 论文下载:
https://skoltech3d.appliedai.tech/
二、实现过程
1. 介绍
3D重建中使用的传感器数据包括高度专业化和昂贵的CT、激光和结构光扫描仪,以及来自普通摄像机和深度传感器的视频,计算三维重建方法通常是针对特定类型的传感器量身定制的。然而,即使是商品硬件也越来越多地提供多传感器数据:例如,许多最近的手机都有多个RGB摄像头以及低分辨率深度传感器。使用来自不同传感器的数据,特别是RGB-D数据,有可能大大提高3D重建的质量。例如,多视图立体算法从RGB数据生成高质量的3D几何图形,但可能会错过无特征的表面;用深度传感器数据补充RGB图像可以获得更完整的重建。相反,商品深度传感器往往缺乏RGB相机提供的分辨率。
基于学习的技术极大地简化了组合来自多个传感器的数据的挑战性任务。然而,学习方法需要合适的数据进行训练。本数据集旨在补充现有的数据集,最重要的是,通过为具有挑战性反射特性的物体提供多传感器数据和高精度真值。
我们的数据集结构有望在几个方面有利于三维重建的研究。
多传感器数据。我们提供来自7种不同设备的高质量校准数据,包括来自商品传感器(手机、
Kinect, RealSense),来自结构光扫描仪的高分辨率几何数据,以及来自不同分辨率和不同相机的RGB数据。这使得依赖于传感器数据的不同组合的重建方法能够进行监督学习,特别是越来越常见的高分辨率RGB与低分辨率深度数据的组合。此外,多传感器数据简化了基于不同传感器类型(RGB、depth和RGB- d)的方法比较。
灯光和位姿的可变性。我们选择专注于所有场景的受控(但可变)照明和固定摄像机位置的设置,以实现来自多个传感器的高质量数据对齐,并系统地比较算法对各种因素的敏感性。我们的目标是使数据集足够大(总共1.39 M不同模式的图像)以支持训练机器学习算法,并提供相机位姿(每个对象100个),照明(14个照明设置,包括“硬”和漫射照明,闪光灯和背光)以及这些算法所需的反射属性的系统可变性。
目标选择。在我们数据集中的107个对象中,我们主要包括可能对上述现有算法提出挑战的对象;我们特别努力提高这些物体的三维高分辨率结构光数据的质量。
本文重点是实验室环境中单个对象的RGB和深度数据,类似于DTU数据集,而不是像Tanks and Temples或ETH3D那样具有自然光的复杂场景。这为系统探索和隔离不同算法优缺点的不同因素提供了手段,并补充了具有复杂场景的数据集提供的更全面的评估和训练数据。
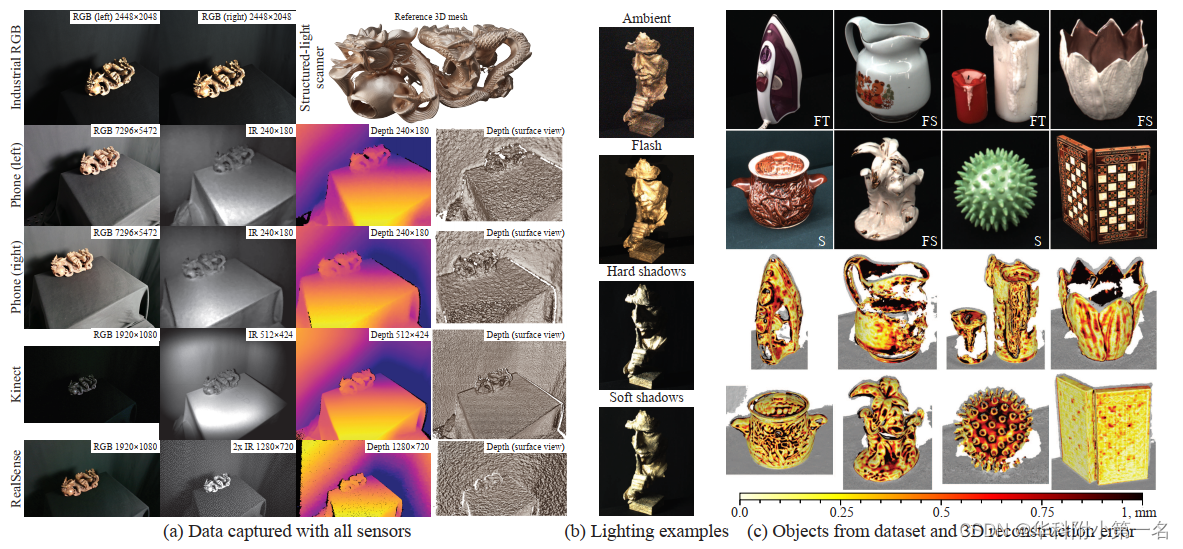
图1所示。本数据集包含(a)用7种不同设备(b)在不同光照条件下捕获的RGB-D数据。(c)专注于具有3D重建算法挑战性的材料,例如无特征(F),具有尖锐反射的高度镜面(S)或半透明(T),如由最先进算法产生的重建所示(与右下角的“简单”对象相比)。
2. 相关工作
开发了许多与3D重建任务相关的数据集(例如,参见对同步定位和地图绘制(SLAM)相关数据集的调查);只讨论与本文最密切相关的数据集。U表示非受控光照,帧是每个传感器计算的,也就是说,来自RGB-D传感器的所有数据都被计算为单个帧。获得的独立图像的数量可能相当大(我们的数据集为1.4 M)。对训练集和测试集的所有场景进行计数。
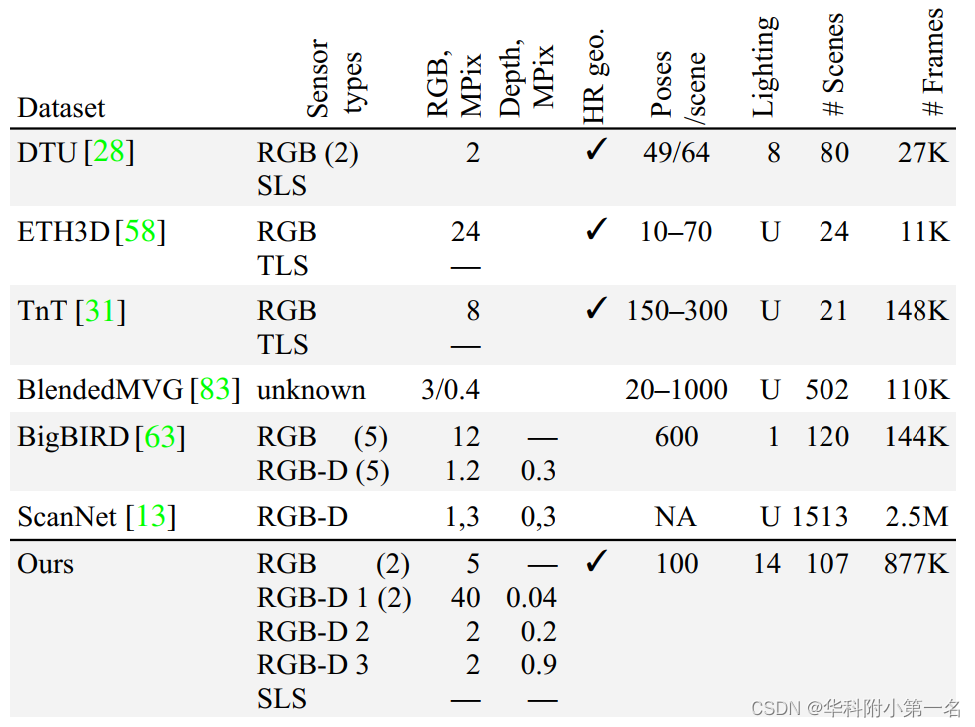
RGB数据集与高分辨率3D真值。许多数据集被设计用于多视图立体(MVS)方法。这些数据集还用于评估从一组RGB图像中重建由神经网络编码的隐式表面表示的方法,以及新视角合成任务。这类数据集通常包括高分辨率RGB,照片或视频,以及使用结构光扫描仪(SLS)或地面激光扫描仪(TLS)获得的高分辨率3D真值。Middlebury数据集侧重于两帧立体,除了RGB之外,还提供了准确的视差真值。在这一组中,具有可控光照和高分辨率真值的DTU数据集最常用于训练基于学习的MVS方法。大多数其他MVS数据集,虽然包含一些孤立物体的图像,但专注于完整的场景,通常是由手持、自由定位的相机收集的。与以前开发的具有高分辨率3D扫描仪数据的数据集相比,本文提供了最多数量的传感器,物体和照明条件,以及最具挑战性的物体。
低分辨率深度数据集。为SLAM、目标识别和分割等任务设计的数据集通常使用低分辨率深度传感器收集,如微软Kinect或英特尔RealSense;其中一些数据集结合了高分辨率RGB和低分辨率深度,但不提供高分辨率的深度真实值。一个明显的例外是CoRBS数据集,但它只包含四个场景。在这些数据集中,对相机位置和光照的控制程度从完全到没有不等。这些数据集通常用于非基于学习的深度融合方法的定性评估,这些方法从深度图中产生基于体素或基于表面的表面表示;它们还用于训练基于学习的方法,这些方法从RGB、深度或RGB- D数据中生成基于体素的表面表示。这些方法可能会受益于在训练中包含高分辨率深度数据。
合成数据集。ShapeNet和ModelNet常用于训练基于学习的深度融合方法。采用综合ICL-NUIM SLAM基准进行评价。这种方法受到现实数据和合成数据之间差异的限制。合成基准允许通过模拟采集过程轻松生成大型训练集。然而,真实世界的数据仍然需要准确地建模传感器,训练生成器和测试训练算法。本数据集可以用于这些目的。
具有多个深度分辨率的数据集。最近提出的RGB-D-D和ARKitScenes数据集朝着与本文类似的方向迈出了一步,分别将智能手机获取的低分辨率深度数据与中分辨率(0.3 MPix)飞行时间数据和高分辨率激光扫描数据配对。本文的数据集包含来自多个低分辨率和高分辨率深度传感器的输入,以及相关的高分辨率RGB图像,为评估和训练深度融合和RGB-D融合算法提供了一个框架,这些算法之前是在合成数据上训练的,以及开发新的。多重深度分辨率还支持深度图超分辨率等应用和深度图补全。
与本文的数据集类似,一项同时进行的工作将英特尔RealSense的RGB-D序列与通过结构光扫描捕获的注册真值进行了补充。本文提供注册深度图像从常见的传感器在三个级别的精度,并控制照明变化。
3. 数据集
本数据集由107个场景组成,其中有一个单一的日常物体或一小组物体在黑色背景上,参见图1中的示例。
使用安装在Universal Robots UR10机械臂上的多个传感器收集数据集,该传感器具有6个自由度和亚毫米级位置重复性。使用了如图2所示的传感器:(1)RangeVision光谱结构光扫描仪(SLS),(2)两台成像源DFK 33UX250工业RGB相机,(3)两台搭载飞行时间(ToF)深度传感器的华为Mate 30 Pro手机,(4)英特尔RealSense D435立体RGB-D摄像头,(5)微软Kinect v2 ToF RGB-D摄像头。
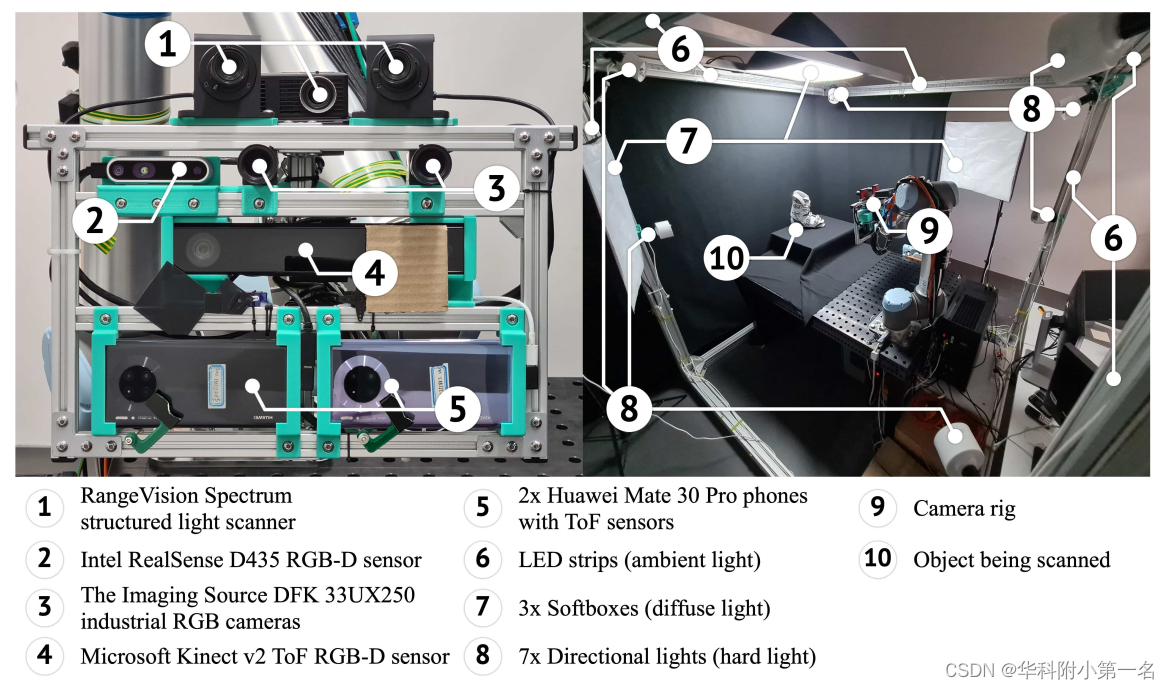
用金属框架包围了扫描区域,并在上面安装了光源,如图2所示。7个定向灯,3个漫射软盒,以及模仿环境光的LED条。还使用手机上的手电筒作为光源随着相机移动。为了防止深度传感器之间的串扰,增加了外部百叶窗,在其他传感器成像时关闭一个传感器的红外(IR)投影仪。
对于每个场景,在物体周围半径为70厘米的球体上移动摄像机钻机100个位置,对所有场景使用相同的轨迹,并使用14个照明设置收集数据。对于每个设备,除了SLS,收集了原始的RGB,深度和IR图像,包括RealSense的左和右IR图像。总共收集了每个场景、相机位置和照明设置的15张原始图像:6张RGB图像、5张IR图像和4张深度图像。由于来自手机和Kinect的ToF传感器的IR和深度数据不受光照条件的影响,在每个相机位置捕获一次这些数据。收集了SLS的部分扫描把27个位置合并成一个扫描图。下表提供了RGB,深度和IR图像,内在(Intr.)和外在(Extr.)校准参数,以及参考网格重建(Rec.)。标记为*的数据是在每次照明设置中捕获的。

数据集包含了大量具有挑战性和不同表面材料属性的对象,如表3所示。基于对关键表面反射参数的视觉估计,为每个目标分配一组对应于这些参数的定性标签。例如,镜面率表示物体的主要材料之一的镜面反射率与漫反射反射率的比率,反射清晰度表征反射函数峰值的尖锐程度。

表3. 数据集中的表面材料属性。
4. 讨论
召回最好的方法是w.r.t. (ACMP),在距离阈值为0.5 mm的情况下,至少53%的概率重构了本数据集中的所有场景,但只有一半的场景在80%或更高的概率上重建。精度和F-score表示的整体质量的最佳方法w.r.t(VisMVSNet)重建所有场景的准确率至少为32%,只有14个场景的准确率高于80%。这表明本数据集对最先进的3D重建方法有很多挑战。特别是,表面的无特征部分,特别是具有明显反射的部分,在重建中经常缺失。与此同时,VisMVSNet的性能也明显优UniMVSNet。这与它们在之前的基准测试(TnT和DTU)上的相对表现相反,这表明本数据集提出了一组不同的挑战。
不同类型方法的比较表明,深度图的重建精度明显低于RGB图像的重建,尽管有时可能更完整。这表明这些模式可以相互补充。类似地,使用神经表面表示的NeuS填充了对基于RGB的方法具有挑战性的表面区域,但通常不准确。值得注意的是,在使用相同的输入RGB图像和深度图时,与VisMVSNet和NeuS相比,神经网络RGB- D表面重建产生的表面质量明显较低。这说明了有效使用这两种模式的3D重建方法的发展空间,本数据集将促进这些方法的发展。
本数据集的主要(故意的)限制是使用实验室设置:专注于具有易于分离背景的静态孤立物体,所有场景的相机轨迹相同,实验室照明。另一个可能的限制是对象大小的范围很小,受设置的物理大小的限制。