基于Q-learning的强化学习案例(附python代码)
基于Q-learning的强化学习案例
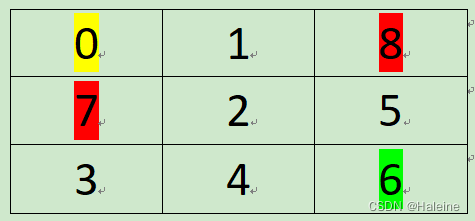
如图所示的一个表格,初始位置伟黄色的0,目标终点为绿色的6,想要通过策略学习找到从0到6的最短路径,其中红色的7和8是禁止通过的位置,Agent经过这两个位置会game over。
以下通过强化学习的Q-Learning方法来学习策略,找到最优的路径方案。
状态空间S 即为0~8
动作空间A 可以向左、向下和向右运动,设置为0 1 2
根据状态和动作,预先给定的奖励值在不同动作和状态下如下图

利用Q-learning算法,编写python代码如下
# 强化学习走Q表
import numpy as np
R = [[-1000, -100, 0],[-5, 0, -100],[-100, 0, 0],[-1000, -1000, 0],[-5, -1000, 100],[-5, 100, -1000],[0, -1000, -1000],[-1000, 0, 0],[0, 0, -1000]]
S = [[0, 7, 1], [0, 2, 8], [7, 4, 5], [3, 3, 4], [3, 4, 6], [2, 6, 5], [4, 6, 6], [7, 3, 2], [1, 5, 8]]
Q = np.zeros([9, 3])
gamma = 0.9
alpha = 0.9
cnt = 0
epoch = 10000
done = False
action = 0
state = 0
rt = 0
road = [0] #构建一个数组存放路径,0表示默认位置,s1
while cnt<epoch:
state = 0
done = False
while not done:
#贪心算法,确保不会一直按照已知的路走,有10%概率探索未知的方法
if np.random.rand()<0.9:
rt = max(Q[state,:])
action = [index for index, item in enumerate(Q[state,:]) if item == rt]
#当已知的路径有多条时随机选择一条
if len(action) > 1:
action = action[int(np.random.randint(0,len(action),size=(1,1)))]
else:
action = action[0]
else:
#随机去探索
action = int(np.random.randint(0,3,size=(1,1)))
#执行action切换到新的state
state_new = S[state][action]
#更新Q表
Q[state,action] = Q[state,action] + alpha*(R[state][action]+gamma*max(Q[state_new,:])-Q[state,action])
#将迭代state切换到新的状态
state = state_new
#记录走过的路径
road.append(state)
#6是成功,7,8是失败,均结束
if int(state) == 6 or int(state) ==7 or int(state) == 8:
done = True
cnt = cnt + 1
print(road)
road = [0] #清空当前路径,开始下一次迭代
print(Q)