前端面试题型汇总(适合应届/社招1年水平)
【本文内容是我应届找实习的时候整理的(2020年),如果有部分内容落后或不正确的欢迎指正~同时也更新了社招篇面经,欢迎光临👉 前端面试题型汇总(适合社招两-三年水平)】
目录
title与h1的区别、b与strong的区别、i与em的区别
判断数据类型的方式(比较typeof与instanceof)
在地址栏里输入一个URL,到这个页面呈现出来,中间会发生什么?
为什么 vue 不需要关心 shouldcomponetupdate(react)
componentWillUpdate可以直接修改state的值吗?
super()和super(props)以及不写super的区别
mixin、hoc、render props、react-hooks的优劣如何?
webpack-dev-server和http服务器如nginx有什么区别?
HTML
-
HTML语义化
- 用正确的标签做正确的事情。
- html语义化让页面的内容结构化,结构更清晰,便于对浏览器、搜索引擎解析;即使在没有样式CSS情况下也以一种文档格式显示,并且是容易阅读的;
- 搜索引擎的爬虫也依赖于HTML标记来确定上下文和各个关键字的权重,利于SEO;
- 使阅读源代码的人对网站更容易将网站分块,便于阅读维护理解。
-
<!DOCTYPE>的作用
- 不是一个HTML标签,是一个用于告诉浏览器当前HTML版本的指令
- 告知浏览器按照何种规范解析页面
- 添加了,就等同于开启了标准模式
-
SEO中的TDK
在SEO中,所谓的TDK其实就是title、description、keywords这三个标签,这三个标签在网站的优化过程中,title标题标签,description描述标签,keywords关键词标签。
-
HTML5中新增标签
-
块级元素和内联元素
常用的块级元素:
address , center , div , dl ,, form , h1 , h2 , h3 , h4 , h5 , h6 , menu , ol , p , table , ul , li
常用内联的元素:
a , b , br , em , font , img , input , label , select , small , span , textarea
-
img中的alt和title的区别
alt是给搜索引擎识别,在图像无法显示时的替代文本;
title是关于元素的注释信息,主要是给用户解读。当鼠标放到文字或是图片上时有title文字显示。
(因为IE不标准)在IE浏览器中alt起到了title的作用,变成文字提示。在定义img对象时,将alt和title属性写全,可以保证在各种浏览器中都能正常使用。
-
title与h1的区别、b与strong的区别、i与em的区别
- title属性没有明确意义只表示是个标题,H1则表示层次明确的标题,对页面信息的抓取也有很大的影响;
- strong是标明重点内容,有语气加强的含义,使用阅读设备阅读网络时:会重读,而是展示强调内容。
- i内容展示为斜体,em表示强调的文本;
-
元标签
提供有关页面的元信息,比如针对搜索引擎和更新频度的描述和关键词。
-
label标签的作用
label标签来定义表单控制间的关系,当用户选择该标签时,浏览器会自动将焦点转到和标签相关的表单控件上。
<label for="Name">Number:</label> <input type="text" id="Name"/>
-
iframe的缺点
- 会阻塞主页面的Onload事件;
- 搜索引擎的检索程序无法解读这种页面,不利于SEO;
- iframe和主页面共享连接池,而浏览器对相同域的连接有限制,所以会影响页面的并行加载。
使用iframe之前需要考虑这两个缺点。如果需要使用iframe,最好是通过javascript。动态给iframe添加src属性值,这样可以绕开以上两个问题。
-
HTML和XHTML的区别
- XHTML 元素必须被正确地嵌套。
错误:
this is example.
正确:
this is example.
- XHTML 元素必须被关闭。
错误:
this is example.
正确:
this is example.
- 标签名必须用小写字母。
错误:
this is example.
正确:
this is example.
- 空标签也必须被关闭
错误:
正确:
- XHTML 文档必须拥有根元素。
所有的 XHTML 元素必须被嵌套于 根元素中。
-
repaint和reflow
repaint就是重绘,reflow就是回流
在性能优先的前提下,reflow的性能消耗要比repaint的大。
repaint是某个dom元素进行重绘,reflow是整个页面进行重排,也就是对页面所有的dom元素渲染。
- repaint的触发:
1)不涉及任何dom元素的排版问题的变动为repaint,例如元素的color、text-align等改变。
2)color的修改,text-align的修改,a:hover也会造成重绘,伪类引起的颜色等变化不会导致页面的回流,仅仅会触发重绘。
- reflow的触发:
1)width、height、border、margin、padding的修改
2)通过hover造成元素表现的改动,如display:none会导致回流
3)appendChild等dom元素操作。
4)font类style 的修改。
5) background的修改,现在经过浏览器厂家的优化,部分background的修改只会触发repaint。
- 如何尽量避免回流reflow:
a、尽可能在dom末稍通过修改class来修改元素的style属性,尽可能减少受影响的dom元素。
b、避免设置多项内联样式,使用常用的class方式进行设置样式,以避免设置样式时访问dom的低效率。
c、设置动画元素position属性为fixed或absolute:由于当前元素从dom流中独立出来,因此受影响的只有当前元素。
d、牺牲平滑度满足性能:动画精度太强,会造成更多的repaint/reflow,牺牲精度,能满足性能的损耗,获取性能和平滑度的平衡。
f、避免使用table进行布局,table每个元素的大小以及内容的改变,都会导致整个table进行重新计算,造成大幅度的repaint或者reflow。改用div则可以针对性的repaint和避免不必要的reflow。
g、避免在css中使用运算式
-
为什么div+css的格式替代了table
- div+css编写出来的文件比用table边写出来的文件小。
- table必须在页面完全加载后才显示,div则是逐行显示。
- table的嵌套性太多,没有div简洁
CSS
-
css样式初始化
- 原因
因为浏览器的兼容的问题,不同浏览器有些标签的默认值是不同的,如果没有CSS初始化往往会出现浏览器之间的页面显示差异。
- 弊端
初始化样式会对SEO有一定的影响
- 淘宝初始化样式
body, h1, h2, h3, h4, h5, h6, hr, p, blockquote, dl, dt, dd, ul, ol, li, pre, form, fieldset, legend, button, input, textarea, th, td { margin:0; padding:0; } body, button, input, select, textarea { font:12px/1.5tahoma, arial, \5b8b\4f53; } h1, h2, h3, h4, h5, h6{ font-size:100%; } address, cite, dfn, em, var { font-style:normal; } code, kbd, pre, samp { font-family:couriernew, courier, monospace; } small{ font-size:12px; } ul, ol { list-style:none; } a { text-decoration:none; } a:hover { text-decoration:underline; } sup { vertical-align:text-top; } sub{ vertical-align:text-bottom; } legend { color:#000; } fieldset, img { border:0; } button, input, select, textarea { font-size:100%; }
-
块级元素和内联元素样式区别
- 内联元素:
内联元素(inline)不会独占一行,相邻的内联元素会排在同一行。其宽度随内容的变化而变化。
内联元素不可以设置宽高
内联元素可以设置margin,padding,但只在水平方向有效。
- 块状元素:
- 块级元素会独占一行,默认情况下宽度自动填满其父元素宽度
- 块级元素可以设置宽高
- 块级元素可以设置margin,padding
- 内联块状元素 inline-block:
表现为同行显示并可修改宽高内外边距等属性。简单来说就是将对象呈现为inline对象,但是对象的内容作为block对象呈现(可以设置宽高和margin值)。之后的内联对象会被排列在同一内联。比如我们可以给一个span标签设置inline-block属性值,使其既具有block的宽度高度特性又具有inline的同行特性。
-
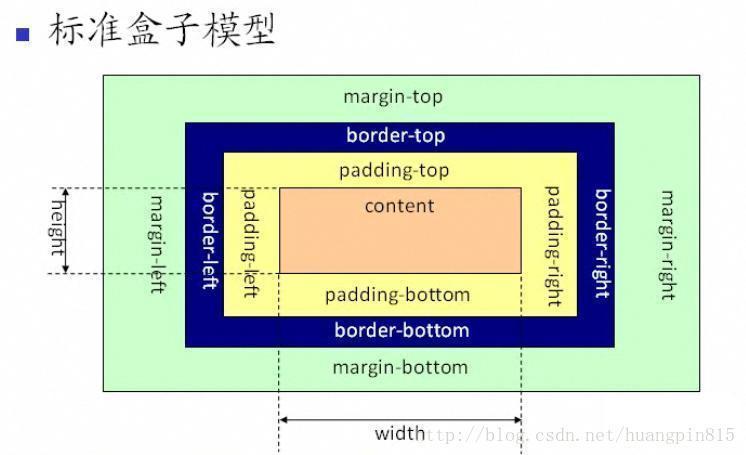
css的盒模型
IE 盒子模型、W3C 盒子模型;
- 盒模型: 内容(content)、填充(padding)、边界(margin)、 边框(border);
- 区 别: IE的content部分把 border 和 padding计算了进去;
-
伪类和伪元素
- 伪类
伪类选择元素基于的是当前元素处于的状态,或者说元素当前所具有的特性,而不是元素的id、class、属性等静态的标志。由于状态是动态变化的,所以一个元素达到一个特定状态时,它可能得到一个伪类的样式;当状态改变时,它又会失去这个样式。由此可以看出,它的功能和class有些类似,但它是基于文档之外的抽象,所以叫伪类。
:link
伪类将应用于未被访问过的链接,与:visited互斥。
:hover
伪类将应用于有鼠标指针悬停于其上的元素。
:active
伪类将应用于被激活的元素,如被点击的链接、被按下的按钮等。
:visited
伪类将应用于已经被访问过的链接,与:link互斥。
- 伪元素
与伪类针对特殊状态的元素不同的是,伪元素是对元素中的特定内容进行操作,它所操作的层次比伪类更深了一层,也因此它的动态性比伪类要低得多。实际上,设计伪元素的目的就是去选取诸如元素内容第一个字(母)、第一行,选取某些内容前面或后面这种普通的选择器无法完成的工作。它控制的内容实际上和元素是相同的,但是它本身只是基于元素的抽象,并不存在于文档中,所以叫伪元素。
:first-letter
伪元素的样式将应用于元素文本的第一个字(母)。
:first-line
伪元素的样式将应用于元素文本的第一行。
:before
在元素内容的最前面添加新内容。
:after
在元素内容的最后面添加新内容。
-
position各属性区别
relative 相对定位
不影响元素本身特性(无论区块元素还是内联元素会保留其原本特性)
不会使元素脱离文档流(元素原本位置会被保留,即改变位置也不会占用新位置)
没有定位偏移量时对元素无影响(相对于自身原本位置进行偏移)
用z-index样式的值可以改变一个定位元素的层级关系,从而改变元素的覆盖关系,值越大越在上面(z-index只能在position属性值为relative或absolute或fixed的元素上有效。) (两个都为定位元素,后面的会覆盖前面的定位)
- absolute 绝对定位
使元素完全脱离文档流(在文档流中不再占位)
使内联元素在设置宽高的时候支持宽高(改变内联元素的特性)
使区块元素在未设置宽度时由内容撑开宽度(改变区块元素的特性)
相对于最近一个有定位的父元素(定位属性除static之外)偏移(若其父元素没有定位则逐层上找,直到document)
相对定位一般配合绝对定位使用(将父元素设置相对定位,使其相对于父元素偏移)
可使用z-index改变显示层级
- fixed 固定定位
fixed生成固定定位的元素,相对于浏览器窗口进行定位。
- static 默认值
默认布局。元素出现在正常的流中(忽略 top, bottom, left, right 或者 z-index 声明)。
- sticky 粘性定位
粘性定位,该定位基于用户滚动的位置。
它的行为就像 position:relative; 而当页面滚动超出目标区域时,它的表现就像 position:fixed;,它会固定在目标位置。
-
display各属性区别
- block
单独占一行,可以设置width,height,maigin四个方向,padding四个方向;
元素宽度在不设置的情况下,是它本身父容器的100%(和父元素的宽度一致),除非设定一个宽度;
- inline
多个内联元素占同一行,直到放不下才换行。设置width,height,margin-top,margin-bottom,padding-top,padding-bottom无效;(通过添加背景颜色可以看出有设置上述属性,但是不会影响其他元素的布局)
- inline-block
像inline一样放置(比如和它相邻的元素处在同一行),像block一样表现。比如:input,select,img等。
float属性、position:absolute绝对定位 和上述替换元素表现为inline-block
- none
inline和inline-block出现的问题
水平呈现的元素间,换行显示或空格分隔的情况下会有间距
解决方法
- 相邻inline-block元素不分行写,写在同一行并且中间无空格
- select父元素使用font-size:0
-
float浮动对元素的影响
-
display:none和visibility:hidden的区别
- display:none是彻底消失,不在文档流中占位,浏览器也不会解析该元素;
- visibility:hidden是视觉上消失了,可以理解为透明度为0的效果,在文档流中占位,浏览器会解析该元素;
- 使用visibility:hidden比display:none性能上要好,display:none切换显示时,页面产生回流(当页面中的一部分元素需要改变规模尺寸、布局、显示隐藏等,页面重新构建,此时就是回流。所有页面第一次加载时需要产生一次回流),而visibility切换是否显示时则不会引起回流。
-
display,float,position的相互影响
position跟display、overflow、float这些特性相互叠加后会怎么样?
display属性规定元素应该生成的框的类型;position属性规定元素的定位类型;float属性是一种布局方式,定义元素在哪个方向浮动。
类似于优先级机制:position:absolute/fixed优先级最高,有他们在时,float不起作用,display值需要调整。float 或者absolute定位的元素,只能是块元素或表格。
-
样式中属性的继承
继承的属性
- 颜色 (color)
- 字体系列 (font-family)
- 字体大小 (font-size)
- 字体样式 (font-style)
- 字体重量 (font-weight)
- 文本对齐 (text-align)
非继承属性
- 背景 (background)
- 边界 (border)
- 余量 (margin)
- 填充 (padding)
- 显示 (display)
- 浮动 (float)
- 宽度 (width)
- 高度 (height)
-
BFC块级格式化上下文
满足下列css声明之一的元素便会生成BFC
- 根元素
- float的值不为none
- overflow的值不为visible(常用 overflow:hidden创建BFC区域)
- display的值为inline-block、table-cell、table-caption
- position的值不为static或relative
-
css hack
由于不同厂商的流览器或某浏览器的不同版本(如IE6-IE11,Firefox/Safari/Opera/Chrome等),对CSS的支持、解析不一样,导致在不同浏览器的环境中呈现出不一致的页面展现效果。这时,我们为了获得统一的页面效果,就需要针对不同的浏览器或不同版本写特定的CSS样式,我们把这个针对不同的浏览器/不同版本写相应的CSS code的过程,叫做CSS hack
-
css选择器及其权重优先级
1.id选择器( # myid)
2.类选择器(.myclassname)
3.标签选择器(div, h1, p)
4.相邻选择器(h1 + p)
5.子选择器(ul > li)
6.后代选择器(li a)
7.通配符选择器( * )
8.属性选择器(a[rel = "external"])
9.伪类选择器(a:hover, li:nth-child)
优先级:
important的权值为最高 1,0,0,0
ID的权值为 0,1,0,0
类的权值为 0,0,1,0
标签的权值为 0,0,0,1
伪类选择的权值为 0,0,1,0
通配选择符的权值 0,0,0,0
比较同一级别的个数,数量多的优先级高,如果相同即比较下一级别的个数:
important > 内联 > ID > 类| 伪类| 属性选择 > 标签 | 伪元素 > 通配符 > 继承
这也就解释了为什么11个标签的定义会比不上1个类的定义,1个类加11个标签会比不上2个类的权重高。
-
清除浮动的几种方法
什么时候需要清除浮动
浮动元素碰到包含它的边框或者浮动元素的边框停留。由于浮动元素不在文档流中,所以文档流的块框表现得就像浮动框不存在一样。浮动元素会漂浮在文档流的块框上。
浮动带来的问题:
- 父元素的高度无法被撑开,影响与父元素同级的元素
- 与浮动元素同级的非浮动元素(内联元素)会跟随其后
- 若非第一个元素浮动,则该元素之前的元素也需要浮动,否则会影响页面显示的结构。
清除浮动的方法:
1.父级div定义 height
原理:父级div手动定义height,就解决了父级div无法自动获取到高度的问题。
优点:简单、代码少、容易掌握
缺点:只适合高度固定的布局,要给出精确的高度,如果高度和父级div不一样时,会产生问题
2,结尾处加空div标签 clear:both
原理:添加一个空div,利用css提高的clear:both清除浮动,让父级div能自动获取到高度
优点:简单、代码少、浏览器支持好、不容易出现怪问题
缺点:不少初学者不理解原理;如果页面浮动布局多,就要增加很多空div,让人感觉很不好
3,父级div定义 伪类:after 和 zoom
原理:IE8以上和非IE浏览器才支持:after,原理和方法2有点类似,zoom(IE转有属性)可解决ie6,ie7浮动问题
优点:浏览器支持好、不容易出现怪问题(目前:大型网站都有使用,如:腾迅,网易,新浪等等)
缺点:代码多、不少初学者不理解原理,要两句代码结合使用才能让主流浏览器都支持
.clearfix:after{ display:table; clear:both; content:""; height:0px; } .clearfix {*zoom:1;} /*照顾IE6,IE7就可以了*/4,父级div定义 overflow:hidden(利用BFC检测区域的浮动的盒子高度)
原理:必须定义width或zoom:1,同时不能定义height,使用overflow:hidden生成BFC时,浏览器会自动检查浮动区域的高度
优点:简单、代码少、浏览器支持好
缺点:不能和position配合使用,因为超出的尺寸的会被隐藏。
-
动画(animation)
-
transition和animation的区别
- css3过渡(transition)、变化(transform)、动画(animation)
- transition是过渡,animation是动画。transition只能从一种状态过渡到另外一种状态,animation可以定制复杂动画,可以定义动画的区间等。
- transition必须通过一些行为才能触发(js或者伪类来触发),animation的话直接就可以触发。
-
媒体查询,@media
- link和@import 导入css文件的区别
- link是XHTML标签,除了加载CSS外,还可以定义RSS等其他事务;
- @import属于CSS范畴,只能加载CSS。
- link引用CSS时,在页面载入时同时加载;
- @import需要页面网页完全载入以后加载。
- link是XHTML标签,无兼容问题;
- @import是在CSS2.1提出的,低版本的浏览器不支持。
- link支持使用Javascript控制DOM去改变样式;
- @import不支持使用Javascript控制DOM去改变样式。
-
水平、垂直居中的几种方式
-
省略文本的样式
/*省略文本*/ white-space:nowrap; overflow: hidden; text-overflow: ellipsis;/* 多行省略 */ width:100px; overflow : hidden; text-overflow: ellipsis; display: -webkit-box; -webkit-line-clamp: 2; -webkit-box-orient: vertical;
-
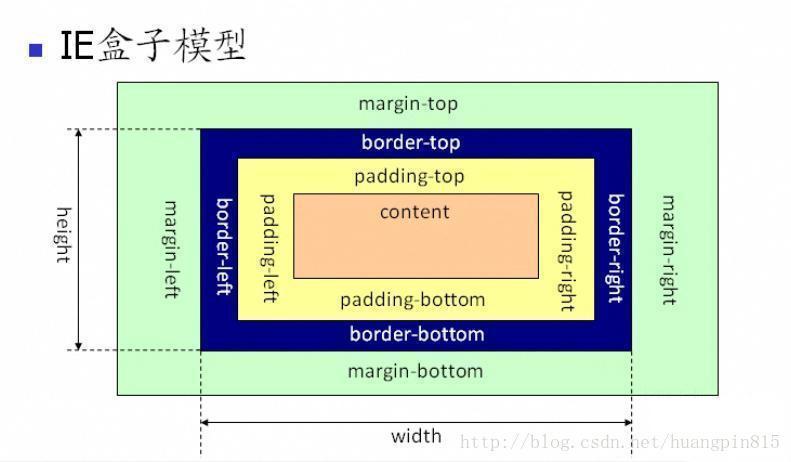
box-sizing属性
box-sizing属性可以指定盒子模型种类
content-box指定盒子模型为W3C的标准盒子模型
border-box指定盒子模型为IE盒子模型(width包含border和padding)
-
双栏布局和三栏布局
-
css预处理,less和sass
CSS预处理器用一种专门的编程语言,进行Web页面样式设计,然后再编译成正常的CSS文件,以供项目使用。CSS预处理器为CSS增加一些编程的特性,无需考虑浏览器的兼容性问题,例如你可以在CSS中使用变量、简单的逻辑程序、函数等等在编程语言中的一些基本特性,可以让你的CSS更加简洁、适应性更强、可读性更佳,更易于代码的维护等诸多好处。
-
css sprite
原理:
将许多的小图片整合到一张大图片中,利用css中的background-image属性,background-position属性定位某个图片位置,来达到在大图片中引用某个部位的小图片的效果。
优点:
- 减少网页的http请求,提升网页加载速度。
- 合并多张小图片成大图,能减少字节总数(大图大小<=多张小图大小).
缺点:
- 前期需要处理图片将小图合并,多些许工程量。
- 对于需要经常改变的图片维护起来麻烦。
-
z-index属性
注意点:
(1):z-index属性只作用在被定位了的元素上。所以如果你在一个没被定位的元素上使用z-index的话,是不会有效果的.
(2)同一个父元素下的元素的层叠效果会受父元素的z-index影响,如果父元素的z-index值很小,那么子元素的z-index值很大也不起作用
失效的情况:
1、父标签 position属性为relative;
2、问题标签无position属性(不包括static);
3、问题标签含有浮动(float)属性。
4、问题标签的祖先标签的z-index值比较小
解决方法:
第一种: position:relative改为position:absolute;
第二种:浮动元素添加position属性(如relative,absolute等);
第三种:去除浮动。
第四种:提高父标签的z-index值
-
scale和zoom区别
- zoom左上角缩放,scale默认中心缩放;scale可通过transform-origin来改变缩放焦点
- zoom缩放只可以是整数,scale可以是负数
- zoom缩放之后不占文档流,下方的元素会自动上移;scale缩放之后会仍然占据文档流(类似position:relative)
- room缩放之后,用js获取元素的宽高仍然是缩放之前的宽高;scale缩放之后,用js获取是缩放之后的宽高。
- 由于对文档流的影响,zoom会引起整个页面的重绘;而scale只改变的缩放的元素
- zoom在火狐上是不支持的(2019-06-15),请谨慎使用
-
src和href引入地址的区别
- href表示超文本引用,用在link和a等元素上,href是引用和页面关联,是在当前元素和引用资源之间建立联系。
- src表示引用资源,表示替换当前元素,用在img,script,iframe上,src是页面内容不可缺少的一部分。
- src是source的缩写,是指向外部资源的位置,指向的内部会迁入到文档中当前标签所在的位置;在请求src资源时会将其指向的资源下载并应用到当前文档中,例如js脚本,img图片和frame等元素。当浏览器解析到这一句的时候会暂停其他资源的下载和处理,直至将该资源加载,编译,执行完毕,图片和框架等元素也是如此,类似于该元素所指向的资源嵌套如当前标签内,这也是为什么要把js饭再底部而不是头部。
- 当浏览器解析到这一句的时候会识别该文档为css文件,会下载并且不会停止对当前文档的处理,这也是为什么建议使用link方式来加载css而不是使用@import。
-
flex弹性布局
-
px,em,rem,vh的区别
- px是最常用的css长度单位,缺点是其不能适应浏览器缩放时产生的变化,因此一般不用于响应式网站。
- em和rem属于相对类型的长度单位值,不过它们所参照的标准不同,em字体大小参照的是其父元素的字体大小值,其余如宽度单位是参照其本身字体大小,过多使用em容易造成耦合依赖,不易于修改维护;而rem的大小参照的是根节点的字体大小值,容易设置,常用于响应式布局。
- vh属于视口的绝对高度,常用100vw表示视口的总宽度,100vh表示视口的总高度。
参考文章:CSS:区别 px、em、rem
-
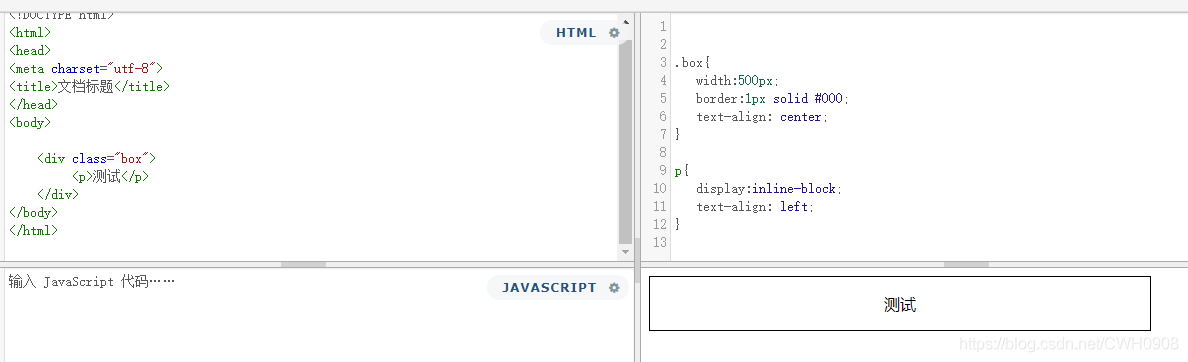
单行文字居中,多行文字左对齐
p标签是定义为内联块元素,始终是左对齐,因为内联块元素是最小宽度,当文字少的时候,然后外面的div把p标签设为居中。表现得效果就是把文字居中了,多行文字时,居中的p标签占据了整个div的宽度,表现了其自身的左对齐效果。
-
CSS面试题
例:
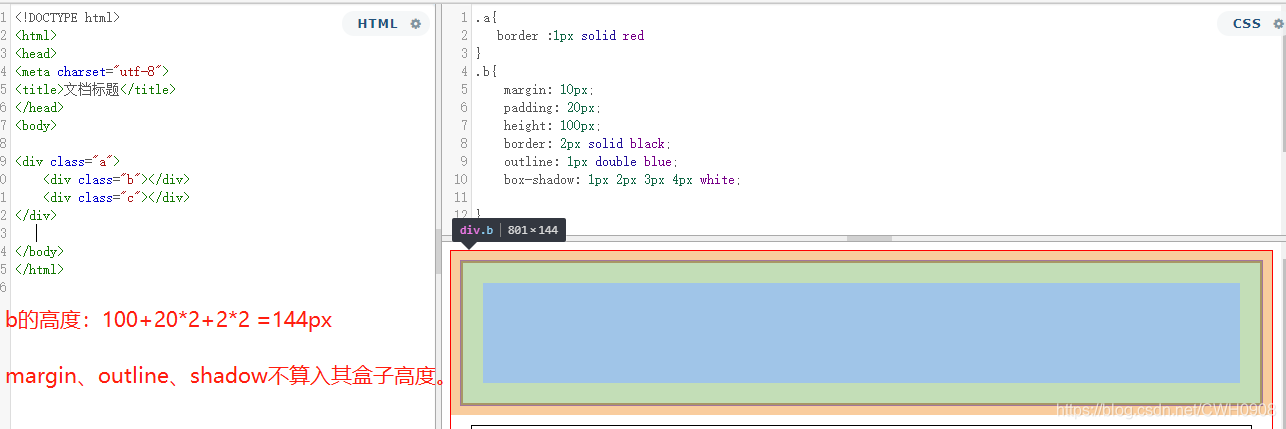
- 请写出以下盒子(a、b、c)分别占据的高度:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>文档标题</title> </head> <style> .a{ border :1px solid red } .b{ margin: 10px; padding: 20px; height: 100px; border: 2px solid black; outline: 1px double blue; box-shadow: 1px 2px 3px 4px white; } .c{ margin: 20px; padding: 10px; height: 50px; border: 1px solid black; box-sizing: border-box; } </style> <body> <div class="a"> <div class="b"></div> <div class="c"></div> </div> </body> </html>
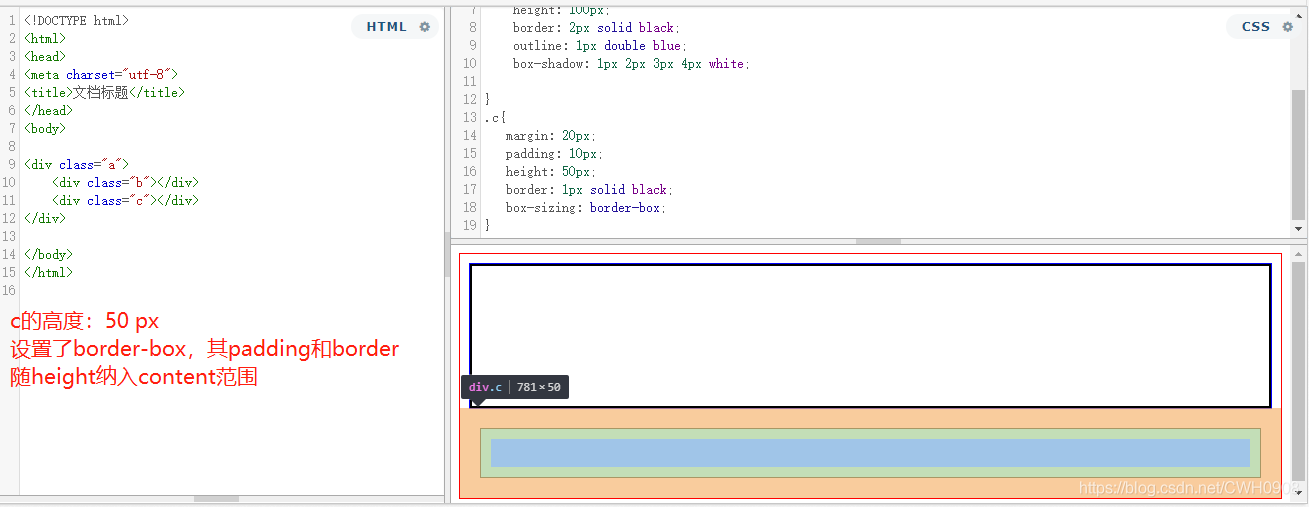
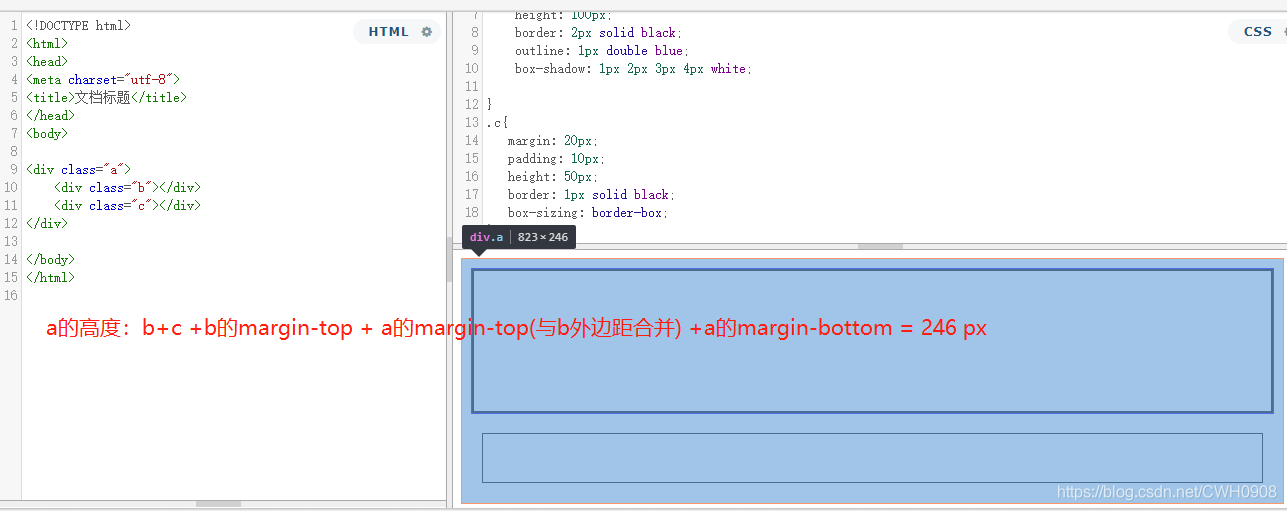
例:计算盒子c的padding值与margin值等于多少px
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>文档标题</title> </head> <style> .a{ position: relative; width: 2000px; height: 1000px; background:red; } .b{ box-sizing: border-box; width: 1000px; height: 500px; background:yellow; } .c{ width: 100px; height: 50px; margin: 20%; padding: 20%; background:blue; } </style> <body> <div class="a"> <div class="b"> <div class="c"> </div> </div> </div> </body> </html>padding为200px,margin为200px,c的盒子的百分比内外边距值是根据父级(b)的width进行计算的 ,其中子级百分比width和height根据规定,也是由父级的width进行计算的。
JavaScript
-
基本数据类型
- undefined
- null
- string
- boolean
- number
- symbol(ES6)
一种引用类型
- Object
-
undefined和null的区别
- null: 代表“空值”,代表一个空对象指针,使用typeof运算得到 “object”,所以可以认为它是一个特殊的对象值。
- undefined: Undefined类型,当一个声明了一个变量未初始化时,得到的就是undefined。
null是javascript的关键字,可以认为是对象类型,它是一个空对象指针,和其它语言一样都是代表“空值”,
不过 undefined 却是javascript才有的。
undefined是在ECMAScript第三版引入的,为了区分空指针对象和未初始化的变量,它是一个预定义的全局变量。
没有返回值的函数返回为undefined,没有实参的形参也是undefined。
-
判断数据类型的方式(比较typeof与instanceof)
相同点:
- JavaScript 中 typeof 和 instanceof 常用来判断一个变量是否为空,或者是什么类型的。
typeof的定义和用法:返回值是一个字符串,用来说明变量的数据类型。
Instanceof定义和用法:instanceof 用于判断一个变量是否属于某个对象的实例,返回布尔值
- typeof 一般只能返回如下几个结果:number,boolean,string,function,object,undefined。
- typeof 来获取一个变量是否存在,如 if(typeof a!="undefined"),而不要去使用 if(a) 因为如果 a 不存在(未声明)则会出错。
- 对于 Array,Null 等特殊对象使用 typeof 一律返回 object,这正是 typeof 的局限性。
常见面试题:判断JS数据类型的四种方法
-
参数的按值传递的理解
ECMAScript中所有函数的参数都是按值传递的。
-
执行环境和作用域链
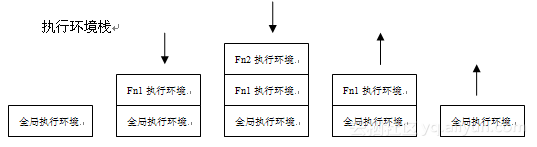
执行环境:
当JavaScript解释器初始化执行代码时,它首先默认进入全局执行环境;从此刻开始,函数的每次调用都会创建一个新的执行环境;每个函数都有自己的执行环境,当执行流进入一个函数时,函数的环境就会被推入一个环境栈中,在函数执行完后栈将其环境弹出,保存在其中的所有变量和函数定义也随之销毁(全局执行环境直到应用程序退出也随之销毁,例如关闭网页或退出浏览器)
作用域链:
当代码在一个环境中执行时,会创建变量对象的一个作用域链,作用域链中的下一个变量对象包含(外部)环境,一直延续到全局执行环境,全局执行环境的变量对象始终是作用域链中的最后一个对象。
简述一下作用域链
访问一个变量属性时先在当前内部作用域中查找,未找到时就会到外部作用域进行往上查找,直到全局作用域为止,由此形成作用域链。
-
模仿块级作用域
- 使用立即执行函数
function函数作用域- es6中的let、const命令创建
-
js原型和原型链
简述一下原型链:
所有函数都有一个prototype属性,所有引用类型(对象)都有__proto__属性,当对象调用当前实例不存在的属性和函数的时候就会沿着__proto__属性向上查找prototype原型对象中的属性和函数,直到Object原型对象为止,由此形成原型链。
-
作用域链和原型链的区别
- 作用域是针对变量的
- 原型链是针对构造函数的
-
js创建对象的方式
- 工厂模式
- 构造函数模式
- 原型模式
- 组合模式
- 寄生构造函数模式
- 稳妥构造函数模式
-
js实现继承的方式
- 原型链继承
- 借用构造函数继承
- 组合继承
- 原型式继承
- 寄生式继承
- 寄生组合式继承
-
对闭包的理解
什么是闭包:
闭包的概念
函数执行时形成的私有上下文EC(FN),正常情况下,代码执行完会出栈后释放;但是特殊情况下,如果当前私有上下文中的某个东西被上下文以外的事物占用了,则上下文不会出栈释放,从而形成不销毁的上下文。 函数执行函数执行过程中,会形成一个全新的私有上下文,可能会被释放,可能不会被释放,不论释放与否,他的作用是:
(1)保护:划分一个独立的代码执行区域,在这个区域中有自己私有变量存储的空间,保护自己的私有变量不受外界干扰(操作自己的私有变量和外界没有关系);
(2)保存:如果当前上下文不被释放【只要上下文中的某个东西被外部占用即可】,则存储的这些私有变量也不会被释放,可以供其下级上下文中调取使用,相当于把一些值保存起来了;
我们把函数执行形成私有上下文,来保护和保存私有变量机制称为
闭包。闭包是指有权访问另一个函数作用域中的变量的函数--《JavaScript高级程序设计》
全面的回答: 在js中变量的作用域属于函数作用域, 在函数执行完后,作用域就会被清理,内存也会随之被回收,但是由于闭包函数是建立在函数内部的子函数, 由于其可访问上级作用域,即使上级函数执行完, 作用域也不会随之销毁, 这时的子函数(也就是闭包),便拥有了访问上级作用域中变量的权限,即使上级函数执行完后作用域内的值也不会被销毁。
闭包的特性:
1、内部函数可以访问定义他们外部函数的参数和变量。(作用域链的向上查找,把外围的作用域中的变量值存储在内存中而不是在函数调用完毕后销毁)设计私有的方法和变量,避免全局变量的污染。
1.1.闭包是密闭的容器,,类似于set、map容器,存储数据的
1.2.闭包是一个对象,存放数据的格式为 key-value 形式
2、函数嵌套函数
3、本质是将函数内部和外部连接起来。优点是可以读取函数内部的变量,让这些变量的值始终保存在内存中,不会在函数被调用之后自动清除
闭包形成的条件:
- 函数的嵌套
- 内部函数引用外部函数的局部变量,延长外部函数的变量生命周期
闭包的用途:
- 模仿块级作用域
- 保护外部函数的变量 能够访问函数定义时所在的词法作用域(阻止其被回收)
- 封装私有化变量
- 创建模块
闭包应用场景
闭包的两个场景,闭包的两大作用:
保存/保护。 在开发中, 其实我们随处可见闭包的身影, 大部分前端JavaScript 代码都是“事件驱动”的,即一个事件绑定的回调方法; 发送ajax请求成功|失败的回调;setTimeout的延时回调;或者一个函数内部返回另一个匿名函数,这些都是闭包的应用。闭包的优点:延长局部变量的生命周期
闭包缺点:会导致函数的变量一直保存在内存中,过多的闭包可能会导致内存泄漏
练习题:

-
this指向问题
this 永远指向最后调用它的那个对象
- 在调用函数时使用
new关键字,函数内的this是一个全新的对象。- 如果
apply、call或bind方法用于调用、创建一个函数,函数内的 this 就是作为参数传入这些方法的对象。- 当函数作为对象里的方法被调用时,函数内的
this是调用该函数的对象。比如当obj.method()被调用时,函数内的 this 将绑定到obj对象。- 如果调用函数不符合上述规则,那么
this的值指向全局对象(global object)。浏览器环境下this的值指向window对象,但是在严格模式下('use strict'),this的值为undefined。- 如果符合上述多个规则,则较高的规则(1 号最高,4 号最低)将决定
this的值。- ES6的箭头函数,将忽略上面的所有规则,
this被设置为它被创建时的上下文。改变 this 指向的方法:
- 使用 ES6 的箭头函数
- 在函数内部使用
_this = this- 使用
apply、call、bind- new 实例化一个对象
-
模拟new实现创建对象
通过new创建对象经历4个步骤
- 创建一个新Object对象;[var o = {};]
- 将构造函数的作用域赋给新对象(因此this指向了这个新对象)执行构造函数中的代码(为这个新对象添加属性); [Person.apply(o)] [Person原来的this指向的是window]
- 为其绑定原型对象;
- 返回新生成的对象。
-
防抖函数
防抖:在高频发的事件调用时,每次将定义好的定时器清除掉,只有当高频发事件调用最后一次的时候,由于没有再调用该事件函数,没有清除定义的定时器,那么定时器将正常工作,即定时器等待时间内连续调用10次后显示1,连续调用20次后显示的还是1。
通俗来讲就是,你要我在30s内搬100块砖,我偷懒,我结束时才搬一块。
主要用于 防止表单重复提交。
-
节流函数
节流:在高频发的事件调用时,不会清除定义好的定时器。假设你的定时器为1s,加入if判断语句,如果你高频发事件的调用间隔小于1s,那么你在这1s的定时器等待时间内调用的次数都当成一次,即连续调用10次后如果花了三秒钟则显示3,连续调用20次后如果花了三秒钟那么也显示3,就是看你的调用时间。注意,将若干函数调用合成为一次(稀释函数的执行频率),并在给定时间过去之后,调用一次(仅仅只会调用一次)。
通俗来讲就是,你要我在30s内搬100块砖,我搬,不过我每1s(定时器范围)才搬一块,多了我不干,所以我最后才搬了30块砖。
主要用于搜索框请求频率的稀释。
-
DOM操作
-
DOM0级和DOM2级的事件处理程序
DOM0级
分为2个:一是在标签内写onclick事件
二是在JS写οnclick=function(){}函
<input id="myButton" type="button" value="Press Me" onclick="alert('thanks');" >document.getElementById("myButton").onclick = function () { alert('thanks'); }为什么没有1级DOM
DOM级别1于1998年10月1日成为W3C推荐标准。1级DOM标准中并没有定义事件相关的内容,所以没有所谓的1级DOM事件模型。在2级DOM中除了定义了一些DOM相关的操作之外还定义了一个事件模型 ,这个标准下的事件模型就是我们所说的2级DOM事件模型 。
DOM2级
有两个用来添加和移除事件处理程序的函数:addEventListener()和removeEventListener()。
它们都有三个参数:第一个参数是事件名(如click);
第二个参数是事件处理程序函数;
第三个参数如果是true则表示在捕获阶段调用,为false表示在冒泡阶段调用。
- addEventListener():可以为元素添加多个事件处理程序,触发时会按照添加顺序依次调用。
- removeEventListener():不能移除匿名添加的函数。
document.getElementById("myTest").attachEvent("onclick", function(){alert(1)}); //IE下使用attachEvent(),等价于 document.getElementById("myTest").addEventListener("click", function(){alert(1)}, false);dom0(属性绑定,兼容性好)和dom2(函数绑定,兼容性不好,万恶的IE)事件绑定的区别
- 如果定义了两个dom0级事件,dom0级事件会覆盖
- dom2不会覆盖,会依次执行
- dom0和dom2可以共存,不互相覆盖,但是dom0之间依然会覆盖
- 为啥不直接都用dom0呢??按照W3C标准所推崇的——结构,行为,样式分离。 DOM0级的耦合度是最高的,所以说是其中最“笨”的方法。所以说这里要依次判断,如果浏览器能用好方法就用好方法,不然在降低标准,不然再降,到DOM0就是极限了。
-
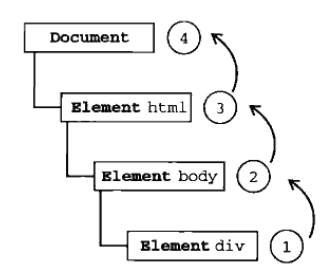
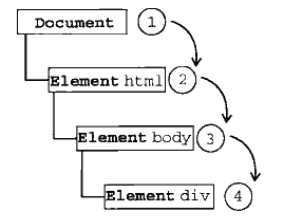
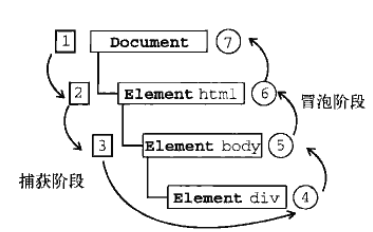
事件冒泡和事件捕获
事件冒泡(常用)
IE中采用的事件流是事件冒泡,先从具体的接收元素,然后逐步向上传播到不具体的元素。
事件捕获(不常用)
先由不具体的元素接收事件,最具体的节点最后才接收到事件。
DOM事件流
-
不同浏览器如何阻止事件冒泡
- event.stopPropagation();||event.cancelBubble=true;
事实上stoppropagation和cancelBubble的作用是一样的,都是用来阻止浏览器默认的事件冒泡行为。不同之处在于stoppropagation属于W3C标准,适用于Firefox等浏览器,但是不支持IE浏览器(IE8以下)。相反cancelBubble不符合W3C标准,而且只支持IE浏览器。所以很多时候,我们都要结合起来用。不过,cancelBubble在新版本chrome,opera浏览器中已经支持。
- event.preventDefault()阻止标签默认事件;
-
跨浏览器的事件对象EventUtil
在JavaScript中,DOM0级、DOM2级与旧版本IE(8-)为对象添加事件的方法不同
为了以跨浏览器的方式处理事件,需要编写一段“通用代码”,即跨浏览器的事件处理程序
习惯上,这个方法属于一个名为EventUtil的对象
编写并使用该对象后,可保证处理事件的代码能在大多数浏览器下一致的运行
-
事件委托及其好处
把一个或者一组元素的事件委托到它的父层或者更外层元素上,真正绑定事件的是外层元素,当事件响应到需要绑定的元素上时,会通过事件冒泡机制从而触发它的外层元素的绑定事件上,然后在外层元素上去执行函数。
优点:
- 减少内存消耗
- 动态绑定事件(因为事件是绑定在父层的,和目标元素的增减是没有关系的)
局限性:
- focus、blur 之类的事件本身没有事件冒泡机制,所以无法委托
- mousemove、mouseout 这样的事件,虽然有事件冒泡,但是只能不断通过位置去计算定位,对性能消耗高,因此也不适合事件委托
-
JSON和XML的对比
JSON对象的两个很重要的方法
JSON.parse() //JSON字符串转换为JSON对象 JSON.stringify() //JSON对象转化为字符串
- JSON相对于XML来讲,数据的体积小,传递的速度更快些
- JSON与JavaScript的交互更加方便,更容易解析处理,更好的数据交互
- XML对数据描述性比较好;
- JSON的速度要远远快于XML
-
Ajax请求的实现
-
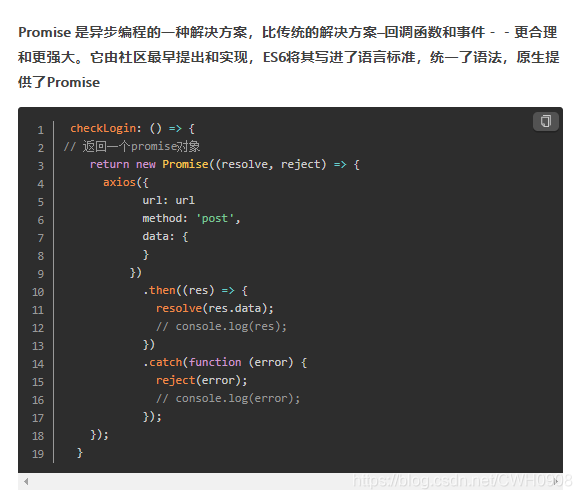
Axios和Ajax的区别
axios 是一个基于Promise 用于浏览器和 nodejs 的 HTTP 客户端,本质上也是对原生XMLHttpRequest的封装,只不过它是Promise的实现版本,符合最新的ES规范,它本身具有以下特征:
1.从浏览器中创建 XMLHttpRequest
2.支持 Promise API
3.客户端支持防止CSRF
4.提供了一些并发请求的接口(重要,方便了很多的操作)
5.从 node.js 创建 http 请求
6.拦截请求和响应
7.转换请求和响应数据
-
浏览器的同源策略
同源策略规定跨域之间的脚本是隔离的,一个域的脚本不能访问和操作另外一个域的绝大部分属性和方法。是用于隔离潜在恶意文件的重要安全机制
属于同源,必须同时满足以下三个相同
- 域名
- 协议
- 端口
-
常用的跨域方案
- JSONP:
Ajax不能跨域,但是script标签和img标签都可以跨域。动态创建script,即新创建script标签,将回调函数名通过后缀的方式写入url地址,服务端收到后进行处理,将包含有json数据格式的对象封装在这个回调函数的参数里里面。客户端收到这个动态script的有参数的回调函数调用,执行操作,更新数据。
缺点:
1、无法发送post请求
2、要确定jsonp的请求是否失败并不容易,大多数框架的实现都是结合超时时间来判定。
为什么不支持post请求:
浏览器的同源策略限制从一个源加载的文档或脚本与来自另一个源的资源进行交互,jsonp跨域本质上是通过动态script标签, 本质上也是对静态资源的访问,所以只能是get请求
- CORS(跨域资源共享)
CORS的整个过程都由浏览器自动完成,前端无需做任何设置,跟平时发送ajax请求并无差异。实现CORS的关键在于服务器,只要服务器实现CORS接口,就可以实现跨域通信。
- window.postMessage()
适合在APP内嵌网页与APP webview 的通信
- nginx
由运维/前端 配置允许访问的域名
- websocket协议
WebSocket protocol是HTML5一种新的协议。它实现了浏览器与服务器全双工通信,同时允许跨域通讯,是server push技术的一种很好的实现。
原生WebSocket API使用起来不太方便,我们使用Socket.io,它很好地封装了webSocket接口,提供了更简单、灵活的接口,也对不支持webSocket的浏览器提供了向下兼容。
- node中间间代理跨域
node中间件实现跨域代理,原理大致与nginx相同,都是通过启一个代理服务器,实现数据的转发,也可以通过设置cookieDomainRewrite参数修改响应头中cookie中域名,实现当前域的cookie写入,方便接口登录认证
-
cookie、localStorage、sessionStorage的区别
存储大小:
cookie数据大小不能超过4k。
sessionStorage和localStorage 虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大。
生命周期:
localStorage 存储持久数据,浏览器关闭后数据不丢失除非主动删除数据;
sessionStorage 数据在当前浏览器窗口关闭后自动删除。
注意:
通过点击链接(或者用了 window.open)打开的新标签页之间是属于同一个 session 的,但新开一个标签页总是会初始化一个新的 session,即使网站是一样的,它们也不属于同一个 session。
-
在地址栏里输入一个URL,到这个页面呈现出来,中间会发生什么?
- 输入url后,首先需要找到这个url域名的服务器ip,为了寻找这个ip,浏览器首先会寻找缓存,查看缓存中是否有记录,缓存的查找记录为:浏览器缓存-》系统缓存-》路由器缓存,缓存中没有则查找系统的hosts文件中是否有记录,如果没有则查询DNS服务器用以解析ip地址。
- 得到服务器的ip地址后,浏览器根据这个ip以及相应的端口号,构造一个http请求,这个请求报文会包括这次请求的信息,主要是请求方法,请求说明和请求附带的数据,并将这个http请求封装在一个tcp包中,这个tcp包会依次经过传输层,网络层,数据链路层,物理层到达服务器,服务器解析这个请求来作出响应,返回相应的html给浏览器。
- 因为html是一个树形结构,浏览器根据这个html来构建DOM树,在dom树的构建过程中如果遇到JS脚本和外部JS连接,则会停止构建DOM树来执行和下载相应的代码,这会造成阻塞,这就是为什么推荐JS代码应该放在html代码的后面,之后根据外部央视,内部央视,内联样式构建一个CSS对象模型树CSSOM树,构建完成后和DOM树合并为渲染树,这里主要做的是排除非视觉节点,比如script,meta标签和排除display为none的节点,之后进行布局,布局主要是确定各个元素的位置和尺寸。
- 之后是渲染页面,因为html文件中会含有图片,视频,音频等资源,在解析DOM的过程中,遇到这些都会进行并行下载,浏览器对每个域的并行下载数量有一定的限制,一般是4-6个,当然在这些所有的请求中我们还需要关注的就是缓存,缓存一般通过Cache-Control、Last-Modify、Expires等首部字段控制。


-
call、bind、apply区别
call与apply都属于Function.prototype的一个方法,所以每个function实例都有call、apply属性;
作用
call()方法和apply()方法的作用相同:改变this指向。区别(接收参数的方式不同)
- call():第一个参数是对象,其余参数都直接传递给函数(参数必须逐个列举出来)。
- apply():第一个参数是对象,传递给函数的是参数数组或者arguments类数组对象。
传递参数并非call()和apply()真正的作用,真正强大的地方是能修改函数运行的作用域(改变this指向)
-
get、post的区别
- Get 请求能缓存,Post 不能
- Post 相对 Get 安全,因为Get 请求都包含在 URL 里,且会被浏览器保存历史纪录,Post 不会,但在抓包的情况下都是一样的。
- Post 可以通过 request body来传输比 Get 更多的数据,Get 没有这个技术
- URL有长度限制,会影响 Get 请求,但是这个长度限制是浏览器规定的,不是 RFC 规定的
- Post 支持更多的编码类型且不对数据类型限制
-
“ ===”、“ ==”的区别
- ==,当且仅当两个运算数相等时,它返回 true,即不检查数据类型
- ===,只有在无需类型转换运算数就相等的情况下,才返回 true,需要检查数据类型
-
同步和异步的区别
同步是阻塞模式,异步是非阻塞模式。
- 同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去;
- 异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态。当有消息返回时系统会通知进程进行处理,这样可以提高执行的效率。
-
JS模块化的好处

-
执行上下文

-
深拷贝
- 浅拷贝是指创建一个对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,那么拷贝的就是基本类型的值,如果属性是引用类型,那么拷贝的就是内存地址,所以如果其中一个对象修改了某些属性,那么另一个对象就会受到影响。
- 深拷贝是指从内存中完整地拷贝一个对象出来,并在堆内存中为其分配一个新的内存区域来存放,并且修改该对象的属性不会影响到原来的对象。
深拷贝和浅拷贝的实现方式分别有哪些?
- 浅拷贝:(1) Object.assign的方式 (2) 通过对象扩展运算符 (3) 通过数组的slice方法 (4) 通过数组的concat方法。
- 深拷贝:(1) 通过JSON.stringify来序列化对象 (2) 手动实现递归的方式
使用变量 a 拷贝对象 b,改变 a 中的值 b 中的值也会跟着改变,这叫做浅拷贝。要想让 a 独立于 b 就需要深拷贝。(非基本类型)
简易处理
function deepClone() { return JSON.parse(JSON.stringify(obj)) }复制代码既然是简易处理就有他的不足,上面主要是用了 JSON 的序列化和反序列化。而 JSON 是不支持function和 undefined 的,因此碰到这些情况会缺失,但是已经能够满足大部分情况了。
复杂处理
Object.assign (伪深度拷贝,只能拷贝第一层)
定义:将源对象(source)的所有可枚举属性,复制到目标对象(target)
用法:
合并多个对象 var target = { a: 1, b: 1 }; var source1 = { b: 2, c: 2 }; var source2 = { c: 3 }; Object.assign(target, source1, source2); 复制代码完全深拷贝就需要采用递归的方式了
function clone(obj) { function whichType(o) { if (o === null) return "Null"; if (o === undefined) return "Undefined"; return Object.prototype.toString.call(o).slice(8, -1); //返回数据类型 } var result; var oType = whichType(obj); if (oType === "Object") { result = {}; } else if (oType === "Array") { result = []; } else { return obj; } for (var key in obj) { // key值为 对象的key值, 数组的下标值 var copy = obj[key]; if (whichType(copy) == "Object" || whichType(copy) == "Object") { result[key] = clone(copy); //递归调用 } else { result[key] = copy; //基本类型直接返回 } } return result; }递归实现深拷贝解析 (面试回答)
为什么要实现深拷贝呢?浅拷贝的限制所在了。它只能拷贝一层对象。如果有对象的嵌套,那么浅拷贝将无能为力浅拷贝引用的是内存地址,当修改拷贝的数据时会影响原来的数据,因此复杂数据类型需要使用深拷贝来克隆数据。
为什么序列化和反序列化不行呢? JSON 是不支持function和 undefined 的,因此碰到这些情况会缺失,只能使用递归实现深拷贝。
如何实现数据深拷贝的递归方式呢?深拷贝的递归实现方式,首先需要判断传入的数据的类型,对于基本数据类型或者 null
和 undefined 则直接返回,对于复杂数据类型(Array和Object),使用 Object.prototype.toString.call (数据) 的方式获取到数据类型,然后使用 for in 循环来得到 复杂数据类型的每个属性值(for in 取出的是对象的key值,数组的下标值),对于每个属性值,如果还是复杂数据类型(嵌套对象等),则继续调用此函数递归求解到基本数据类型为止,如果是基本数据类型,则返回,最后返回克隆的数据即可实现深拷贝。
-
js中import和require的区别
ES6标准发布后,module成为标准,标准使用是以export指令导出接口,以import引入模块。但是在我们一贯的node模块中,我们依然采用的是CommonJS规范,使用require引入模块,使用module.exports导出接口。
遵循规范
require是 CommonJS/AMD规范引入方式import是es6的一个语法标准,如果要兼容浏览器的话必须转化成es5的语法调用时间
- require是运行时调用,所以require理论上可以运用在代码的任何地方
- import是编译时调用,所以必须放在文件开头
本质
- require是赋值过程,其实require的结果就是对象、数字、字符串、函数等,再把require的结果赋值给某个变量
- import是解构过程,但是目前所有的引擎都还没有实现import,我们在node中使用babel支持ES6,也仅仅是将ES6转码为ES5再执行,import语法会被转码为require
参考文章:import和require的区别
-
js拼接两个数组的方式
- 方法一:使用for循环
var arr = ['tom', 'jerry']; var arr2 = [1, 2]; for(var i=0; i<arr2.length; i++){ arr.push(arr2[i]) } console.log(arr); // ['tom', 'jerry', 1, 2]
- 方法二:使用concat(),注意concat()方法生成了一个新的数组,并不改变原来的数组。
var arr = ['tom', 'jerry']; var arr2 = [1, 2]; var newArr = arr.concat(arr2); console.log(newArr); // ["tom", "jerry", 1, 2]
- 方法三: 使用apply劫持数组的push方法(推荐,apply具体使用方法参考MDN)
var arr = ['tom', 'jerry']; var arr2 = [1, 2]; arr.push.apply(arr, arr2); console.log(arr) // ["tom", "jerry", 1, 2]
- 方法四:使用es6中的 ‘点语法’ 扩展运算符(推荐)
var arr = ['tom', 'jerry']; var arr2 = [1, 2]; arr.push(...arr2); console.log(arr) // ["tom", "jerry", 1, 2]
- 备注:扩展运算符(...)
扩展运算符( spread )是三个点(...)。它好比 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列。 console.log(1, ...[2, 3, 4], 5) // 1 2 3 4 5 [...document.querySelectorAll('div')] // [<div>, <div>, <div>]
-
String、Number类型运算
console.log(1 + "2" + "2"); console.log(1 + +"2" + "2"); console.log(1 + -"1" + "2"); console.log(+"1" + "1" + "2"); console.log( "A" - "B" + "2"); console.log( "A" - "B" + 2);以上代码将输出到控制台:
"122" "32" "02" "112" "NaN2" NaN这里的基本问题是JavaScript(ECMAScript)是一种松散类型的语言,它对值执行自动类型转换以适应正在执行的操作。让我们来看看这是如何与上面的每个例子进行比较。
- 示例1:1 +“2”+“2”输出:“122”说明:第一个操作在1 +“2”中执行。由于其中一个操作数(“2”)是一个字符串,所以JavaScript假定需要执行字符串连接,因此将1的类型转换为“1”,1 +“2”转换为“12”。然后,“12”+“2”产生“122”。
- 示例2:1 + +“2”+“2”输出:“32”说明:根据操作顺序,要执行的第一个操作是+“2”(第一个“2”之前的额外+被视为一个一元运算符)。因此,JavaScript将“2”的类型转换为数字,然后将一元+符号应用于它(即将其视为正数)。结果,下一个操作现在是1 + 2,当然这会产生3.但是,我们有一个数字和一个字符串之间的操作(即3和“2”),所以JavaScript再次转换数值赋给一个字符串并执行字符串连接,产生“32”。
- 示例3:1 + - “1”+“2”输出:“02”说明:这里的解释与前面的示例相同,只是一元运算符是 - 而不是+。因此,“1”变为1,然后在应用 - 时将其变为-1,然后将其加1到产生0,然后转换为字符串并与最终的“2”操作数连接,产生“02”。
- 示例4:+“1”+“1”+“2”输出:“112”说明:尽管第一个“1”操作数是基于其前面的一元+运算符的数值类型转换的,当它与第二个“1”操作数连接在一起时返回一个字符串,然后与最终的“2”操作数连接,产生字符串“112”。
- 示例5:“A” - “B”+“2”输出:“NaN2”说明:由于 - 运算符不能应用于字符串,并且既不能将“A”也不能将“B”转换为数值, “ - ”B“产生NaN,然后与字符串”2“串联产生”NaN2“。
- 例6:“A” - “B”+2输出:NaN说明:在前面的例子中,“A” - “B”产生NaN。但是任何运算符应用于NaN和其他数字操作数仍然会产生NaN。
-
数组去重的几种方式
let originalArray = [1,2,3,4,5,3,2,4,1]; // 方式1 const result = Array.from(new Set(originalArray)); console.log(result); // -> [1, 2, 3, 4, 5] // 方式2 const result = []; const map = new Map(); for (let v of originalArray) { if (!map.has(v)) { map.set(v, true); result.push(v); } } console.log(result); // -> [1, 2, 3, 4, 5] // 方式3 const result = []; for (let v of originalArray) { if (!result.includes(v)) { result.push(v); } } console.log(result); // -> [1, 2, 3, 4, 5] // 方式4 for (let i = 0; i < originalArray.length; i++) { for (let j = i + 1; j < originalArray.length; j++) { if (originalArray[i] === originalArray[j]) { originalArray.splice(j, 1); j--; } } } console.log(originalArray); // -> [1, 2, 3, 4, 5] // 方式5 const obj = {}; const result = originalArray.filter(item => obj.hasOwnProperty(typeof item + item) ? false : (obj[typeof item + item] = true)); console.log(result); // -> [1, 2, 3, 4, 5]
-
JS正则表达式
示例:
常用操作符
- \d : 0-9之间的任意一个数字 \d只占一个位置
- \w : 数字,字母 ,下划线 0-9 a-z A-Z _
- \s : 空格或者空白等
- \D : 除了\d
- \W : 除了\w
- \S : 除了\s
- . : 除了\n之外的任意一个字符
- \ : 转义字符
- | : 或者
- () : 分组
- \n : 匹配换行符
- \b : 匹配边界 字符串的开头和结尾 空格的两边都是边界 => 不占用字符串位数
- ^ : 限定开始位置 => 本身不占位置
- $ : 限定结束位置 => 本身不占位置
- [a-z] : 任意字母 []中的表示任意一个都可以
- [^a-z] : 非字母 []中^代表除了
- [abc] : abc三个字母中的任何一个 [^abc]除了这三个字母中的任何一个字符
字符 描述 \ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符。序列 '\\' 匹配 "\" 而 "\(" 则匹配 "("。
^ 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。
$ 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。
* 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。
+ 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。
? 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 。? 等价于 {0,1}。
{n} n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。
{n,} n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。
{n,m} m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。
? 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o'。
. 匹配除换行符(\n、\r)之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用像"(.|\n)"的模式。
(pattern) 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 '\(' 或 '\)'。
(?:pattern) 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 'industry|industries' 更简略的表达式。
(?=pattern) 正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,"Windows(?=95|98|NT|2000)"能匹配"Windows2000"中的"Windows",但不能匹配"Windows3.1"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?!pattern) 正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如"Windows(?!95|98|NT|2000)"能匹配"Windows3.1"中的"Windows",但不能匹配"Windows2000"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?<=pattern) 反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如," (?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows",但不能匹配"3.1Windows"中的"Windows"。(? 反向否定预查,与正向否定预查类似,只是方向相反。例如" (?"能匹配"3.1Windows"中的"Windows",但不能匹配"2000Windows"中的"Windows"。x|y 匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。
[xyz] 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。
[^xyz] 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'、'l'、'i'、'n'。
[a-z] 字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。
[^a-z] 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。
\b 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。
\B 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。
\cx 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。
\d 匹配一个数字字符。等价于 [0-9]。
\D 匹配一个非数字字符。等价于 [^0-9]。
\f 匹配一个换页符。等价于 \x0c 和 \cL。
\n 匹配一个换行符。等价于 \x0a 和 \cJ。
\r 匹配一个回车符。等价于 \x0d 和 \cM。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。
\S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\t 匹配一个制表符。等价于 \x09 和 \cI。
\v 匹配一个垂直制表符。等价于 \x0b 和 \cK。
\w 匹配字母、数字、下划线。等价于'[A-Za-z0-9_]'。
\W 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'。
\xn 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。
\num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。
\n 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。
\nm 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。
\nml 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。
\un 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。
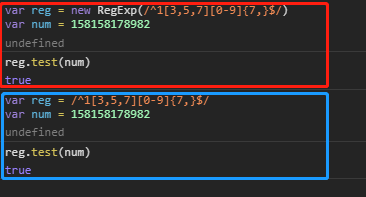
-
defer 、async 和sync
defer:延迟 async :异步 sync:同步
当浏览器碰到
script脚本的时候:
没有
defer或async,浏览器会立即加载并执行指定的脚本,“立即”指的是在渲染该script标签之下的文档元素之前,也就是说不等待后续载入的文档元素读到就加载并执行。有
async,加载和渲染后续文档元素的过程将和script.js的加载与执行并行进行(异步)。有
defer,加载后续文档元素的过程将和script.js的加载并行进行(异步),但是script.js的执行要在所有元素解析完成之后,DOMContentLoaded事件触发之前完成。然后从实用角度来说呢,首先把所有脚本都丢到 之前是最佳实践,因为对于旧浏览器来说这是唯一的优化选择,此法可保证非脚本的其他一切元素能够以最快的速度得到加载和解析。
接着,我们来看一张图:
蓝色线代表网络读取,红色线代表执行时间,这俩都是针对脚本的;绿色线代表 HTML 解析。
此图告诉我们以下几个要点:
- defer 和 async 在网络读取(下载)这块儿是一样的,都是异步的(相较于 HTML 解析)
- 它俩的差别在于脚本下载完之后何时执行,显然 defer 是最接近我们对于应用脚本加载和执行的要求的
- 关于 defer,此图未尽之处在于它是按照加载顺序执行脚本的,这一点要善加利用
- async 则是一个乱序执行的主,反正对它来说脚本的加载和执行是紧紧挨着的,所以不管你声明的顺序如何,只要它加载完了就会立刻执行
- 仔细想想,async 对于应用脚本的用处不大,因为它完全不考虑依赖(哪怕是最低级的顺序执行),不过它对于那些可以不依赖任何脚本或不被任何脚本依赖的脚本来说却是非常合适的,最典型的例子:Google Analytics

JS面试题
例:
var a={}, b={key:'b'}, c={key:'c'}; a[b]=123; a[c]=456; console.log(a[b]);此代码的输出将是456(不是123)。
原因如下:设置对象属性时,JavaScript会隐式地将参数值串联起来。在这种情况下,由于b和c都是对象,它们都将被转换为“[object Object]”。因此,a [b]和a [c]都等价于[“[object Object]”],并且可以互换使用。因此,设置或引用[c]与设置或引用[b]完全相同。
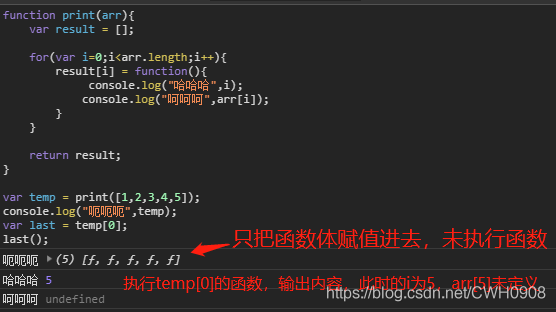
例:
var a = 10; var obj = { a: 20, say: () => { // 此处改为箭头函数 console.log(this.a); } }; obj.say(); // -> 10例
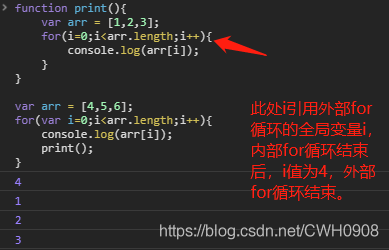
例
Vue面试题
-
vue的生命周期
Vue实例有一个完整的生命周期,也就是从开始创建、初始化数据、编译模板、挂载Dom、渲染→更新→渲染、销毁等一系列过程,我们称这是Vue的生命周期。通俗说就是Vue实例从创建到销毁的过程,就是生命周期。
每一个组件或者实例都会经历一个完整的生命周期,总共分为三个阶段:初始化、运行中、销毁。
- 实例、组件通过new Vue() 创建出来之后会初始化事件和生命周期,然后就会执行beforeCreate钩子函数,这个时候,数据还没有挂载呢,只是一个空壳,无法访问到数据和真实的dom,一般不做操作
- 挂载数据,绑定事件等等,然后执行created函数,这个时候已经可以使用到数据,也可以更改数据,在这里更改数据不会触发updated函数,在这里可以在渲染前倒数第二次更改数据的机会,不会触发其他的钩子函数,一般可以在这里做初始数据的获取
- 接下来开始找实例或者组件对应的模板,编译模板为虚拟dom放入到render函数中准备渲染,然后执行beforeMount钩子函数,在这个函数中虚拟dom已经创建完成,马上就要渲染,在这里也可以更改数据,不会触发updated,在这里可以在渲染前最后一次更改数据的机会,不会触发其他的钩子函数,一般可以在这里做初始数据的获取
- 接下来开始render,渲染出真实dom,然后执行mounted钩子函数,此时,组件已经出现在页面中,数据、真实dom都已经处理好了,事件都已经挂载好了,可以在这里操作真实dom等事情...
- 当组件或实例的数据更改之后,会立即执行beforeUpdate,然后vue的虚拟dom机制会重新构建虚拟dom与上一次的虚拟dom树利用diff算法进行对比之后重新渲染,一般不做什么事儿
- 当更新完成后,执行updated,数据已经更改完成,dom也重新render完成,可以操作更新后的虚拟dom
- 当经过某种途径调用$destroy方法后,立即执行beforeDestroy,一般在这里做一些善后工作,例如清除计时器、清除非指令绑定的事件等等
- 组件的数据绑定、监听...去掉后只剩下dom空壳,这个时候,执行destroyed,在这里做善后工作也可以
-
v-for中:key的作用
需要使用key来给每个节点做一个唯一标识,Diff算法就可以正确的识别此节点,找到正确的位置区插入新的节点。key的作用主要是为了高效的更新虚拟DOM
-
组件中的data为什么是个函数
组件是可复用的
vue实例,一个组件被创建好之后,就可能被用在各个地方,而组件不管被复用了多少次,组件中的data数据都应该是相互隔离,互不影响的,基于这一理念,组件每复用一次,data数据就应该被复制一次,之后,当某一处复用的地方组件内data数据被改变时,其他复用地方组件的data数据不受影响。每个组件实例可以维护一份被返回对象的独立拷贝。
-
虚拟DOM节点
优点:
- 保证性能下限: 虚拟DOM可以经过diff找出最小差异,然后批量进行patch,这种操作虽然比不上手动优化,但是比起粗暴的DOM操作性能要好很多,因此虚拟DOM可以保证性能下限
- 无需手动操作DOM: 虚拟DOM的diff和patch都是在一次更新中自动进行的,我们无需手动操作DOM,极大提高开发效率
- 跨平台: 虚拟DOM本质上是JavaScript对象,而DOM与平台强相关,相比之下虚拟DOM可以进行更方便地跨平台操作,例如服务器渲染、移动端开发等等
缺点:
- 无法进行极致优化: 在一些性能要求极高的应用中虚拟DOM无法进行针对性的极致优化,比如VScode采用直接手动操作DOM的方式进行极端的性能优化
虚拟DOM实现原理?
- 虚拟DOM本质上是JavaScript对象,是对真实DOM的抽象
- 状态变更时,记录新树和旧树的差异
- 最后把差异更新到真正的dom中
虚拟DOM详细实现见虚拟DOM原理

-
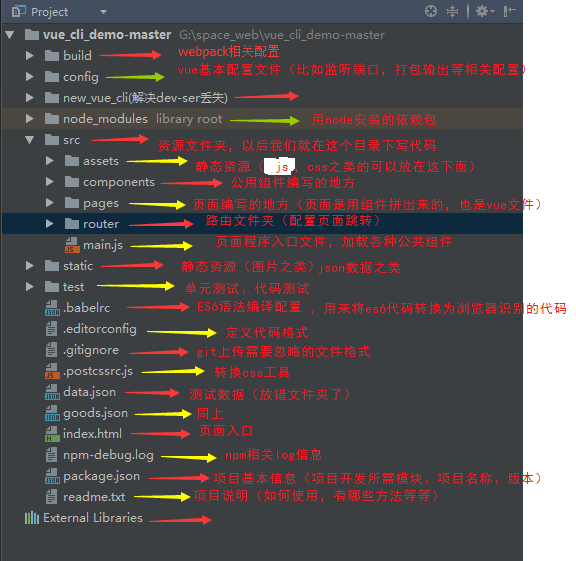
vue-cli 脚手架 目录 解析


-
Vue双向数据绑定原理
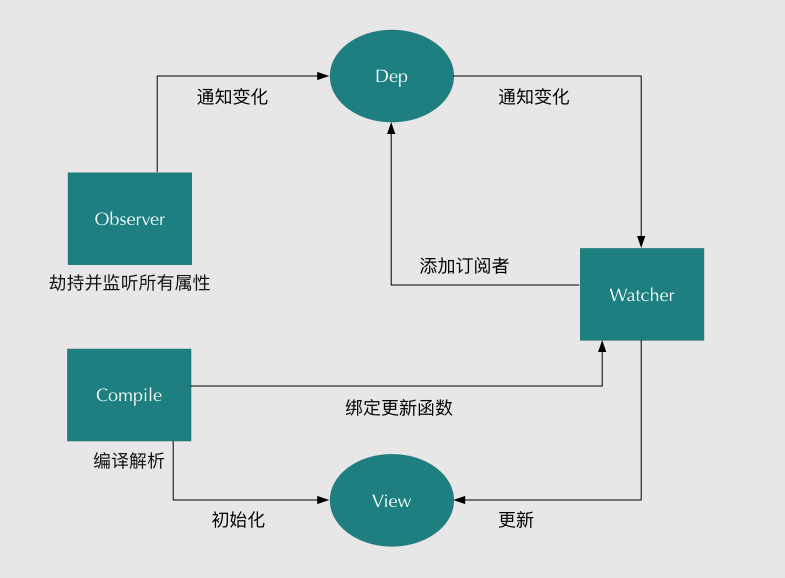
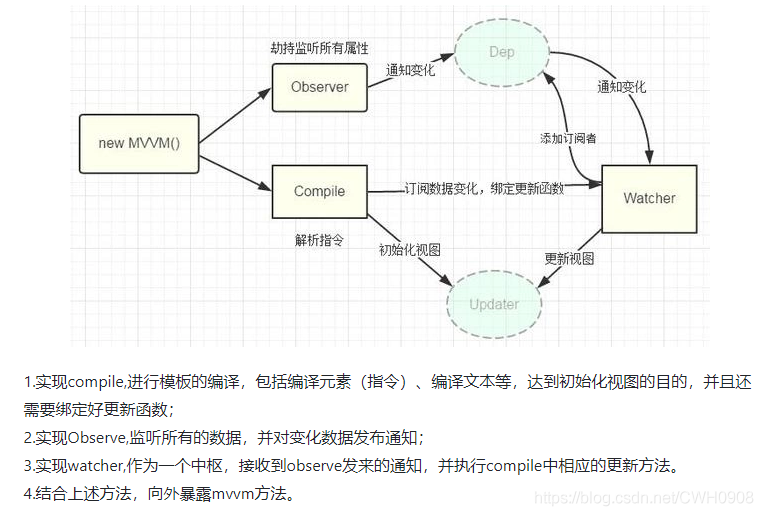
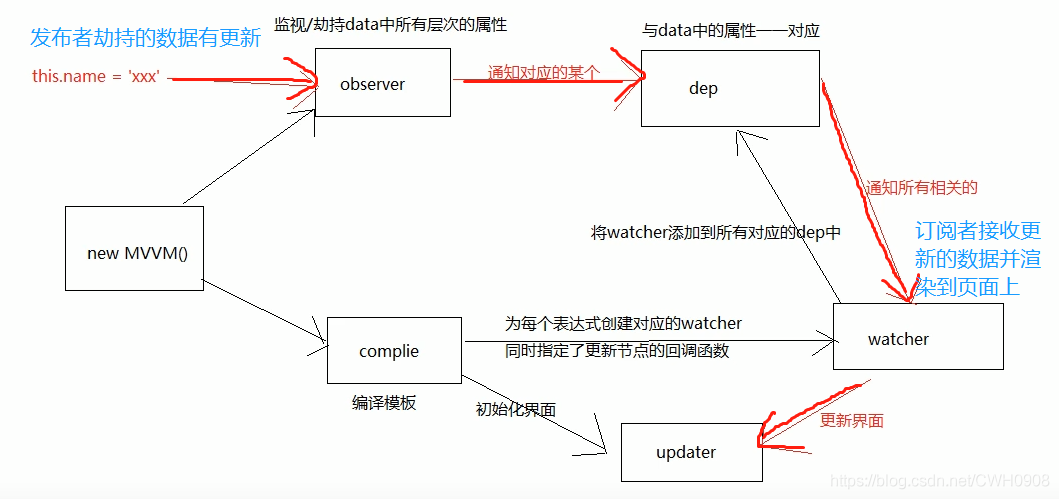
- vue数据双向绑定是通过数据劫持结合发布者-订阅者模式的方式来实现的。
- 首先要对数据进行劫持监听,所以我们需要设置一个监听器Observer,用来监听所有属性。如果属性发上变化了,就需要告诉订阅者Watcher看是否需要更新。
- 因为订阅者是有很多个,所以我们需要有一个消息订阅器Dep来专门收集这些订阅者,然后在监听器Observer和订阅者Watcher之间进行统一管理的。
- 接着,我们还需要有一个指令解析器Compile,对每个节点元素进行扫描和解析,将相关指令对应初始化成一个订阅者Watcher,并替换模板数据或者绑定相应的函数,此时当订阅者Watcher接收到相应属性的变化,就会执行对应的更新函数,从而更新视图。
参考文章:vue的双向绑定原理及实现
-
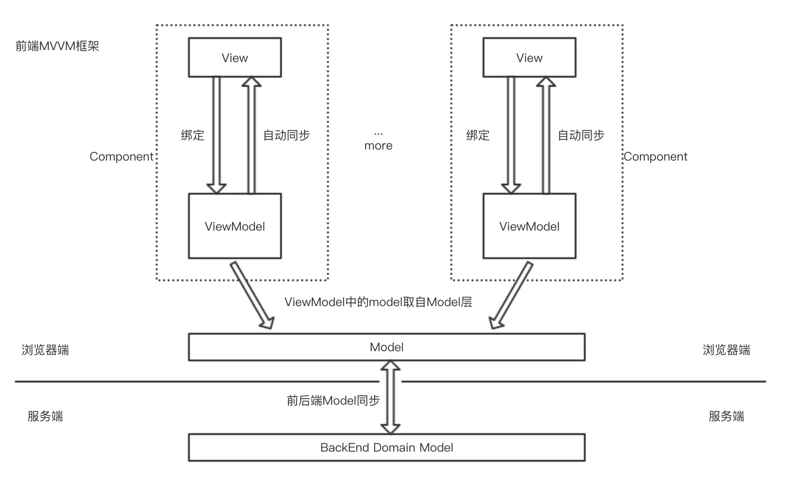
MVVM是什么?
- Model 层: 对应数据层的域模型,它主要做域模型的同步。通过 Ajax/fetch 等 API 完成客户端和服务端业务 Model 的同步。在层间关系里,它主要用于抽象出 ViewModel 中视图的 Model。
- View 层:作为视图模板存在,在 MVVM 里,整个 View 是一个动态模板。除了定义结构、布局外,它展示的是 ViewModel 层的数据和状态。View 层不负责处理状态,View 层做的是 数据绑定的声明、 指令的声明、 事件绑定的声明。
- ViewModel 层:把 View 需要的层数据暴露,并对 View 层的 数据绑定声明、 指令声明、 事件绑定声明 负责,也就是处理 View 层的具体业务逻辑。ViewModel 底层会做好绑定属性的监听。当 ViewModel 中数据变化,View 层会得到更新;而当 View 中声明了数据的双向绑定(通常是表单元素),框架也会监听 View 层(表单)值的变化。一旦值变化,View 层绑定的 ViewModel 中的数据也会得到自动更新。
-
简述一下MVVM模式
MVVM模式,即Model-View-ViewModel,其中,
Model是数据层,里面包含页面渲染所需要的数据。
View是视图层,即所呈现出来的页面。
VM层,是Model层和View层的桥梁。
View 和 Model 没有直接的联系,而是通过VM层进行交互,View 和 Model 之间的交互是双向的, 因此View 数据的变化会同步到Model中,而Model 数据的变化也会立即反应到View 上。开发者只需关注业务逻辑,不需要手动操作DOM。
-
MVVM的优缺点?
优点:
- 分离视图(View)和模型(Model),降低代码耦合,提高视图或者逻辑的重用性: 比如视图(View)可以独立于Model变化和修改,一个ViewModel可以绑定不同的"View"上,当View变化的时候Model不可以不变,当Model变化的时候View也可以不变。你可以把一些视图逻辑放在一个ViewModel里面,让很多view重用这段视图逻辑
- 提高可测试性: ViewModel的存在可以帮助开发者更好地编写测试代码
- 自动更新dom: 利用双向绑定,数据更新后视图自动更新,让开发者从繁琐的手动dom中解放
缺点:
- Bug很难被调试: 因为使用双向绑定的模式,当你看到界面异常了,有可能是你View的代码有Bug,也可能是Model的代码有问题。数据绑定使得一个位置的Bug被快速传递到别的位置,要定位原始出问题的地方就变得不那么容易了。另外,数据绑定的声明是指令式地写在View的模版当中的,这些内容是没办法去打断点debug的
- 一个大的模块中model也会很大,虽然使用方便了也很容易保证了数据的一致性,当时长期持有,不释放内存就造成了花费更多的内存
- 对于大型的图形应用程序,视图状态较多,ViewModel的构建和维护的成本都会比较高
-
Vue中MVVM实现的基本原理
-
Vue组件通信

-
computed和watch有什么区别?
computed:
computed是计算属性,也就是计算值,它更多用于计算值的场景computed具有缓存性,computed的值在getter执行后是会缓存的,只有在它依赖的属性值改变之后,下一次获取computed的值时才会重新调用对应的getter来计算computed适用于计算比较消耗性能的计算场景watch:
- 更多的是「观察」的作用,类似于某些数据的监听回调,用于观察
props$emit或者本组件的值,当数据变化时来执行回调进行后续操作- 无缓存性,页面重新渲染时值不变化也会执行
-
Vue组件的按需加载
// 工厂函数执行 resolve 回调 Vue.component('async-webpack-example', function (resolve) { // 这个特殊的 `require` 语法将会告诉 webpack // 自动将你的构建代码切割成多个包, 这些包 // 会通过 Ajax 请求加载 require(['./my-async-component'], resolve) })
-
vue-router的核心原理
vue-router通过hash与History两种方式实现前端路由,更新视图但不重新请求页面”是前端路由原理的核心之一
-
vue mixins和extends的区别
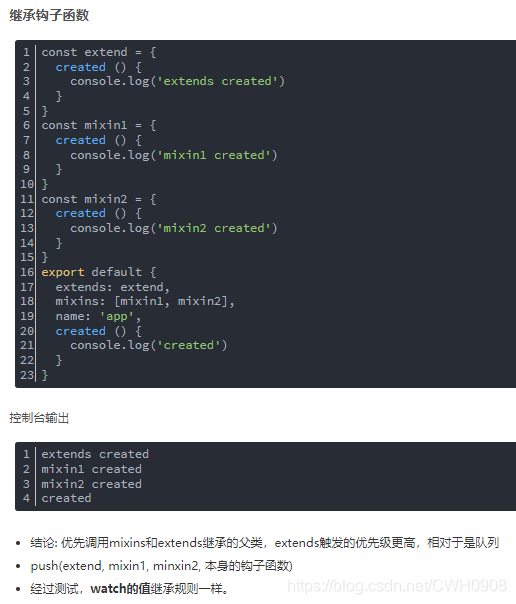
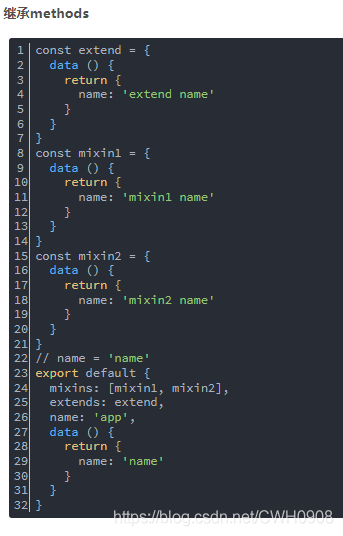
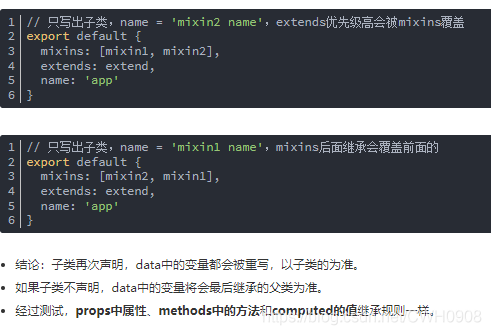
混合mixins和继承extends
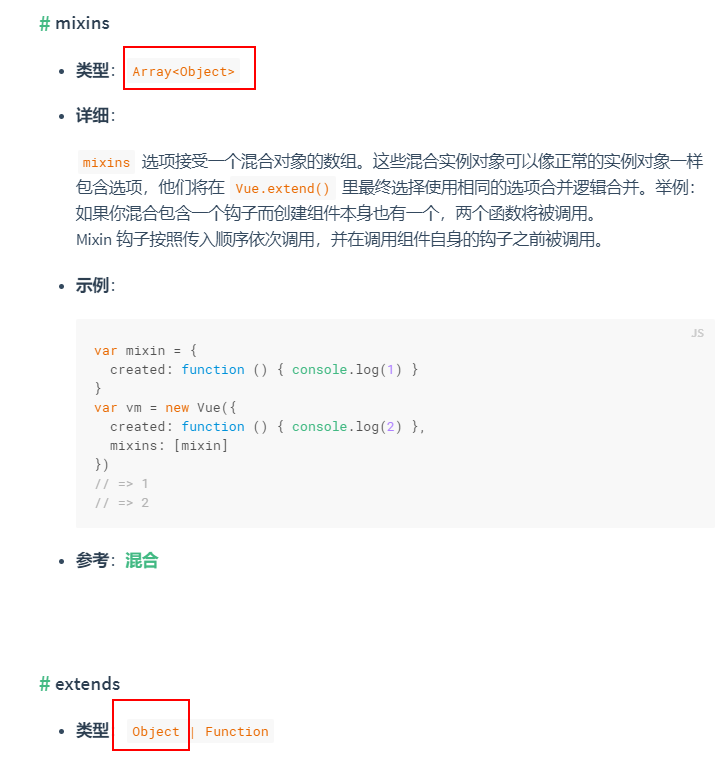
看看官方文档怎么写的,其实两个都可以理解为继承,mixins接收对象数组(可理解为多继承),extends接收的是对象或函数(可理解为单继承)。
关于mixins和extend你可以理解为mvc的c(controller),这一层。可见通用的成员变量(包括属性和方法)抽象成为一个父类,提供给子类继承,这样可以让子类拥有一些通用成员变量,然而子类也可以重写父类的成员变量。这样的整个编程思想就很面向对象,也就是继承性。
-
Vue的SEO优化
-
Vue 能检测到数组项赋值变化吗
vue中的数组的监听不是通过Object.defineProperty来实现的,是通过对'push', 'pop','shift','unshift','splice', 'sort','reverse'等改变数组本身的方法来通知监听的,所以直接给数组某一项赋值无法监听到变化,解决方案如下:
用vue的set方法改变数组或者对象
用改变数组本身的方法如splice, pop, shift等
用深拷贝,解构运算符
-
为什么 vue 不需要关心 shouldcomponetupdate(react)
在 React 应用中,当某个组件的状态发生变化时,它会以该组件为根,重新渲染整个组件子树。
如要避免不必要的子组件的重渲染,你需要在所有可能的地方使用 PureComponent,或是手动实现 shouldComponentUpdate 方法。同时你可能会需要使用不可变的数据结构来使得你的组件更容易被优化。
然而,使用 PureComponent 和 shouldComponentUpdate 时,需要保证该组件的整个子树的渲染输出都是由该组件的 props 所决定的。如果不符合这个情况,那么此类优化就会导致难以察觉的渲染结果不一致。这使得 React 中的组件优化伴随着相当的心智负担。
在 Vue 应用中,组件的依赖是在渲染过程中自动追踪的,所以系统能精确知晓哪个组件确实需要被重渲染。你可以理解为每一个组件都已经自动获得了 shouldComponentUpdate,并且没有上述的子树问题限制。
Vue 的这个特点使得开发者不再需要考虑此类优化,从而能够更好地专注于应用本身。
Vue 和 React 本质上都是实现这个逻辑,分歧在于 isDataChanged 如何计算。
React 选择把这个变量的计算过程交给开发者实现,如果开发者没有实现就默认为 true;Vue 凭借 getter/setter 特性可以自动计算出这个值,但牺牲了 IE8- 的兼容性。
React 面试题
-
React 生命周期
初始化阶段:
- getDefaultProps:获取实例的默认属性
- getInitialState:获取每个实例的初始化状态
- componentWillMount:组件即将被装载、渲染到页面上
- render:组件在这里生成虚拟的 DOM 节点
- componentDidMount:组件真正在被装载之后
运行中状态:
- componentWillReceiveProps:组件将要接收到属性的时候调用
- shouldComponentUpdate:组件接受到新属性或者新状态的时候(可以返回 false,接收数据后不更新,阻止 render 调用,后面的函数不会被继续执行了)
- componentWillUpdate:组件即将更新不能修改属性和状态
- render:组件重新描绘
- componentDidUpdate:组件已经更新
销毁阶段:
- componentWillUnmount:组件即将销毁
-
为何要在componentDidMount里面发送请求?
如果你要获取外部数据并加载到组件上,只能在组件"已经"挂载到真实的网页上才能作这事情,其它情况你是加载不到组件的。
- constructor被调用是在组件准备要挂载的最一开始,所以此时组件尚未挂载到网页上。
- componentWillMount方法的调用在constructor之后,在render之前,在这方法里的代码调用setState方法不会触发重渲染,所以它一般不会用来作加载数据之用,它也很少被使用到。
- 一般的从后台(服务器)获取的数据,都会与组件上要用的数据加载有关,所以都在componentDidMount方法里面作。虽然与组件上的数据无关的加载,也可以在constructor里作,但constructor是作组件state初绐化工作,并不是设计来作加载数据这工作的,componentDidMount方法中的代码,是在组件已经完全挂载到网页上才会调用被执行,所以可以保证数据的加载。此外,在这方法中调用setState方法,会触发重渲染。所以,官方设计这个方法就是用来加载外部数据用的,或处理其他的副作用代码。
constructor()中获取数据的话,如果时间太长,或者出错,组件就渲染不出来,你整个页面都没法渲染了。
componentDidMount()中能保证你的组件已经正确渲染。
总结下:
- 跟服务器端渲染(同构)有关系,如果在componentWillMount里面获取数据,fetch data会执行两次,一次在服务器端一次在客户端。在componentDidMount中可以解决这个问题。
- 在componentWillMount中fetch数据一定在render后才能到达,如果你忘记了设置初始状态,用户体验不好。
- react16.0以后,componentWillMount可能会被执行多次。
-
React单向数据流
React遵循从上到下的数据流向,即单向数据流。
单向数据流并非‘单向绑定’,甚至单向数据流与绑定没有‘任何关系’。对于React来说,单向数据流(从上到下)与单一数据源这两个原则,限定了React中要想在一个组件中更新另一个组件的状态(类似于Vue的平行组件传参,或者是子组件向父组件传递参数),需要进行状态提升。即将状态提升到他们最近的祖先组件中。子组件中Change了状态,触发父组件状态的变更,父组件状态的变更,影响到了另一个组件的显示(因为传递给另一个组件的状态变化了,这一点与Vue子组件的$emit()方法很相似)。
Vue也是单向数据流(https://cn.vuejs.org/v2/guide/components-props.html),只不过能实现双向绑定。
单向数据流中的‘单向’-- 数据从父组件到子组件这个流向叫单向。
绑定的单双向:View层与Module层之间的映射关系。
-
标签的作用
渲染第一个被location匹配到的并且作为子元素的或者
使用包裹和直接用一堆有什么区别呢?
是唯一的因为它仅仅只会渲染一个路径。相比之下(不使用包裹的情况下),每一个被location匹配到的将都会被渲染。
-
react中key值作用
Key 是 React 用于追踪哪些列表中元素被修改的标识。
保证某个元素的 key 在其同级元素中具有唯一性。在 Diff 算法中 React 会借助元素的 Key 值来判断该元素是新近创建的还是被移动而来的元素,从而减少不必要的元素重渲染。
-
为什么 setState 是异步的

-
react 性能优化是哪个周期函数?
shouldComponentUpdate 这个方法用来判断是否需要调用 render 方法重新描绘 dom。因为 dom 的描绘非常消耗性能,如果我们能在 shouldComponentUpdate 方法中能够写出更优化的 dom diff 算法,可以极大的提高性能。
-
为什么虚拟 dom 会提高性能?(必考)
虚拟 dom 相当于在 js 和真实 dom 中间加了一个缓存,利用 dom diff 算法避免了没有必要的 dom 操作,从而提高性能。
用 JavaScript 对象结构表示 DOM 树的结构;然后用这个树构建一个真正的 DOM 树,插到文档当中当状态变更的时候,重新构造一棵新的对象树。然后用新的树和旧的树进行比较,记录两棵树差异把 2 所记录的差异应用到步骤 1 所构建的真正的 DOM 树上,视图就更新了。
-
react diff算法的比较过程
- 把树形结构按照层级分解,只比较同级元素。
- 给列表结构的每个单元添加唯一的 key 属性,方便比较。
- React 只会匹配相同 class 的 component(这里面的 class 指的是组件的名字)
- 合并操作,调用 component 的 setState 方法的时候, React 将其标记为 dirty.到每一个事件循环结束, React 检查所有标记 dirty 的 component 重新绘制.
- 选择性子树渲染。开发人员可以重写 shouldComponentUpdate 提高 diff 的性能。
-
状态组件(类组件)和无状态组件(函数组件)的区别
- 无状态组件关心组件看起来是什么。展示专门通过 props 接受数据和回调,并且几乎不会有自身的状态,但当无状态组件拥有自身的状态时,通常也只关心 UI 状态而不是数据的状态。
- 容器组件则更关心组件是如何运作的。容器组件会为展示组件或者其它容器组件提供数据和行为(behavior),它们会调用 Flux actions,并将其作为回调提供给展示组件。容器组件经常是有状态的,因为它们是(其它组件的)数据源。
- 无状态组件的优缺点
优点:
- 易复用,易测试
- 与逻辑处理数据解耦,一般来说,app里有越多无状态组件越好,这说明逻辑处理都在上层,例如redux 中处理,这样可以在不渲染的前提下,测数据逻辑。
缺点:
没有生命周期,没办法用shouldComponentUpdate阻止重新渲染,这也就是说,它没有帮助我们提高性能的作用,这也是它跟PureComponent最大的不同。
-
状态(state)和属性(props)之间有何不同
- State 是一种数据结构,用于组件挂载时所需数据的默认值。State 可能会随着时间的推移而发生突变,但多数时候是作为用户事件行为的结果。
- Props是组件的配置。props 由父组件传递给子组件,并且就子组件而言,props 是不可变的。组件不能改变自身的 props,只能把数据变更到数据提交给父组件去处理,让父组件改变传递给子组件的props。
-
讲一下redux
- redux 是一个应用数据流框架,主要是解决了组件间状态共享的问题,原理是集中式管理,主要有三个核心方法,action,store,reducer,工作流程是 view 调用 store 的 dispatch 接收 action 传入 store,reducer 进行 state 操作,view 通过 store 提供的 getState 获取最新的数据。
- flux 也是用来进行数据操作的,有四个组成部分 action,dispatch,view,store,工作流程是 view 发出一个 action,派发器接收 action,让 store 进行数据更新,更新完成以后 store 发出 change,view 接受 change 更新视图。
- Redux 和 Flux 很像。主要区别在于 Flux 有多个可以改变应用状态的 store,在 Flux 中 dispatcher 被用来传递数据到注册的回调事件,但是在 redux 中只能定义一个可更新状态的 store,redux 把 store 和 Dispatcher 合并,结构更加简单清晰
- 新增 state,对状态的管理更加明确,通过 redux,流程更加规范了,减少手动编码量,提高了编码效率,同时缺点时当数据更新时有时候组件不需要,但是也要重新绘制,有些影响效率。一般情况下,我们在构建多交互,多数据流的复杂项目应用时才会使用它们。
-
render函数中return如果没有使用()会有什么问题
为了代码可读性我们一般会在return后面添加括号这样代码可以折行书写,否则就在return 后面紧跟着语句,不然的话,代码会报错
-
super()和super(props)有什么区别?
如果你使用了constructor就必须写super() 这个是用来初始化this的,可以绑定事件到this上
如果你想要在constructor中使用this.props,就必须给super添加参数 super(props)
-
react使用async/await
async componentDidMount() { try { const response = await axios.get('http://XXXXXX').then(res=>{ if(res.data.err = XXX){ throw Error(response.statusText); }else{ this.setState(XXX:res.data.XXX) } }) } catch (error) { console.log(error); } }
-
讲一下react 的 jsx
JSX 是一个 JavaScript 语法扩展。它类似于模板语言,但它具有 JavaScript 的全部能力。JSX 最终会被编译为
React.createElement()函数调用,返回称为 “React 元素” 的普通 JavaScript 对象。
-
componentWillUpdate可以直接修改state的值吗?
在componentWillUpdate中通过setState更新,会一直触发componentWillUpdate导致无限循环,最终报错。
-
super()和super(props)以及不写super的区别
1、如果你用到了constructor就必须写super(),是用来初始化this的,可以绑定事件到this上;
2、如果你在constructor中要使用this.props,就必须给super加参数:super(props);(无论有没有constructor,在render中this.props都是可以使用的,这是React自动附带的;)
3、如果没用到constructor,是可以不写的;React会默认添加一个空的constructor。
-
Context 的作用
Context 提供了一种在组件之间共享此类值的方式,而不必显式地通过组件树的逐层传递 props。
Context 主要应用场景在于很多不同层级的组件需要访问同样一些的数据。请谨慎使用,因为这会使得组件的复用性变差。
-
React的事件和普通的HTML事件有什么不同?
- 在 HTML 中事件名必须小写,而在 React 中它遵循camelCase(驼峰) 惯例
- 在 HTML 中你可以返回
false以阻止默认的行为,而在 React 中你必须地明确地调用preventDefault(),原生事件在合成事件之后,可以使用event.stopPropagation()来阻止冒泡。
-
为什么函数式组件没有生命周期?
因为函数式组件没有继承React.Component,由于生命周期函数是React.Component类的方法实现的,所以没继承这个类,自然就没法使用生命周期函数了
-
在React中如何避免不必要的render?
-
React 如何判断点击元素属于哪一个组件

-
this.refs.XXX 的作用
- refs 引用的是虚拟DOM, document.getXXX得到的是真实DOM。
- refs 可以引用到自定义的React组件,调用组件的方法,而document不能。
- 使用这种MVVM前端框架应该尽量不去直接访问DOM,当然某些情况下是必须要访问
-
vue和react路由的区别是什么?
二者的设计理念大致相同,无论是vue-router还是react-router,它们的最基本的初衷就是实现前端路由。所谓前端路由,简单来说,就是当浏览器的url产生变化时,不向服务器进行请求,而是直接控制前端页面产生变化,以期待前端在比如功能切换时,产生类似页面跳转等效果。
而这里面最基本的,无论是vue-router还是react-router,都要提供一种配置方式,让使用者可以配置出url路径和要展示的组件的对应关系。这样一来,用户通过页面点击或者其他方式触发浏览器url变化时,VUE或者React系统就可以找到这个url对应的VUE组件或者React组件,从而有针对性地,将这个组件在页面上渲染。
-
react绑定函数的四种方式
class App extends Component{ constructor(props){ super(props); this.function1 = this.function1.bind(this) } // 1,在constructor构造函数中绑定 function1(){ } // 2,在绑定事件时使用bind function2(params){ } // 3,在绑定事件时使用箭头函数 function3(params){ } // 4,新语法,直接使用箭头函数创建 function3 = ()=>{ } render(){ return <div onClick = {this.function2.bind(this,params)}> <div onClick = {(e)=>{this.function3(params,e)}}></div> </div> } }
-
react高阶组件
什么是高阶组件?
- 一个高阶组件只是一个包装了另外一个 React 组件的 React 组件。
高阶组件可以用来做什么
- 代码复用,逻辑抽象,抽离底层准备(bootstrap)代码
- 渲染劫持
- State 抽象和更改
- Props 更改
高阶组件工厂的实现
属性代理(Props Proxy)和 反向继承(Inheritance Inversion)。下面只介绍属性代理
属性代理的实现方法如下:
function ppHOC(WrappedComponent) { return class PP extends React.Component { render() { return <WrappedComponent {...this.props}/> } } }可以看到,这里高阶组件的 render 方法返回了一个 type 为 WrappedComponent 的 React Element(也就是被包装的那个组件),我们把高阶组件收到的 props 传递给它,因此得名 Props Proxy。
注意:
<WrappedComponent {...this.props}/> // is equivalent to React.createElement(WrappedComponent, this.props, null)它们都创建了一个 React Element,描述了 React 在『reconciliation』(可以理解为解析)阶段的渲染内容,如果你想了解更多关于 React Element 的内容,请看 Dan Abramov 的这篇博客 和官方文档上关于 reconciliation process 的部分。
Props Proxy 可以做什么?
- 更改 props
- 通过 refs 获取组件实例
- 抽象 state
- 把 WrappedComponent 与其它 elements 包装在一起
更改 props
你可以『读取,添加,修改,删除』将要传递给 WrappedComponent 的 props。
在修改或删除重要 props 的时候要小心,你可能应该给高阶组件的 props 指定命名空间(namespace),以防破坏从外传递给 WrappedComponent 的 props。
例子:添加新 props。这个应用目前登陆的一个用户可以在 WrappedComponent 通过 this.props.user 获取
function ppHOC(WrappedComponent) { return class PP extends React.Component { render() { const newProps = { user: currentLoggedInUser } return <WrappedComponent {...this.props} {...newProps}/> } } }通过 refs 获取组件实例
你可以通过 ref 获取关键词 this(WrappedComponent 的实例),但是想要它生效,必须先经历一次正常的渲染过程来让 ref 得到计算,这意味着你需要在高阶组件的 render 方法中返回 WrappedComponent,让 React 进行 reconciliation 过程,这之后你就通过 ref 获取到这个 WrappedComponent 的实例了。
例子:下方例子中,我们实现了通过 ref 获取 WrappedComponent 实例并调用实例方法。
function refsHOC(WrappedComponent) { return class RefsHOC extends React.Component { proc(wrappedComponentInstance) { wrappedComponentInstance.method() } render() { const props = Object.assign({}, this.props, {ref: this.proc.bind(this)}) return <WrappedComponent {...props}/> } } }当 WrappedComponent 被渲染后,ref 上的回调函数 proc 将会执行,此时就有了这个 WrappedComponent 的实例的引用。这个可以用来『读取,添加』实例的 props 或用来执行实例方法。
抽象 state
你可以通过向 WrappedComponent 传递 props 和 callbacks(回调函数)来抽象 state,这和 React 中另外一个组件构成思想 Presentational and Container Components 很相似。
例子:在下面这个抽象 state 的例子中,我们幼稚地(原话是naively :D)抽象出了 name input 的 value 和 onChange。我说这是幼稚的是因为这样写并不常见,但是你会理解到点。
function ppHOC(WrappedComponent) { return class PP extends React.Component { constructor(props) { super(props) this.state = { name: '' } this.onNameChange = this.onNameChange.bind(this) } onNameChange(event) { this.setState({ name: event.target.value }) } render() { const newProps = { name: { value: this.state.name, onChange: this.onNameChange } } return <WrappedComponent {...this.props} {...newProps}/> } } }然后这样使用它:
@ppHOC class Example extends React.Component { render() { return <input name="name" {...this.props.name}/> } }这里的 input 自动成为一个受控的input。
参考链接:深入理解 React 高阶组件 - 简书
用法实例:
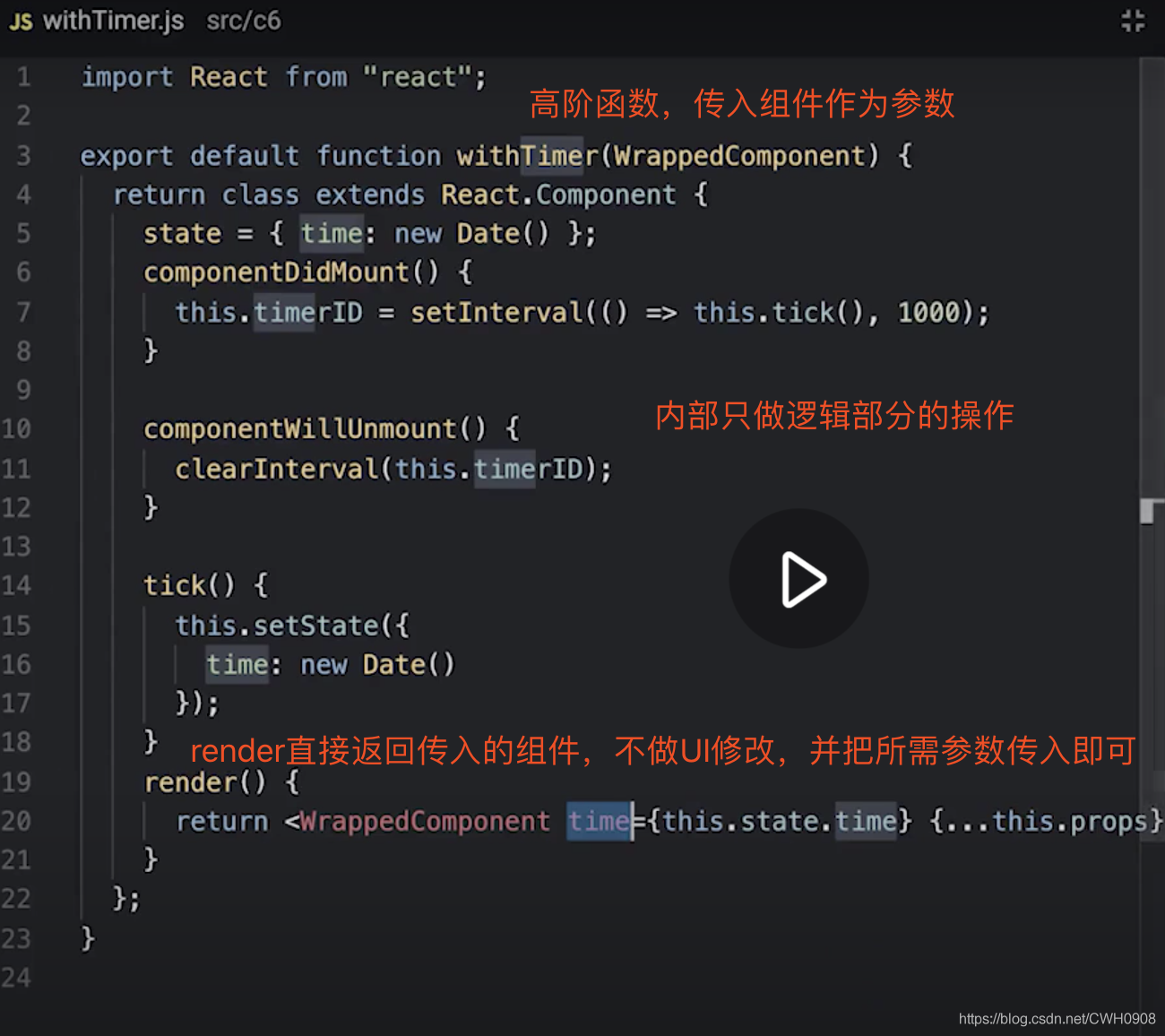
编写好高阶组件 withTimer用于给传入的组件注入定时器功能
在需要使用高阶组件的组件中引入高阶组件
// 1 引入有定时器功能的组件 import withTImer from 'XXXX'; // 2 只在UI上添加符合高阶组件显示的标签,并传入在高阶组件中定义好的 值,time class App from extends{ render(){ return <div> <h4> {this.props.time.toLocaleString()} </h4> </div> } } // export default withTimer(App)
-
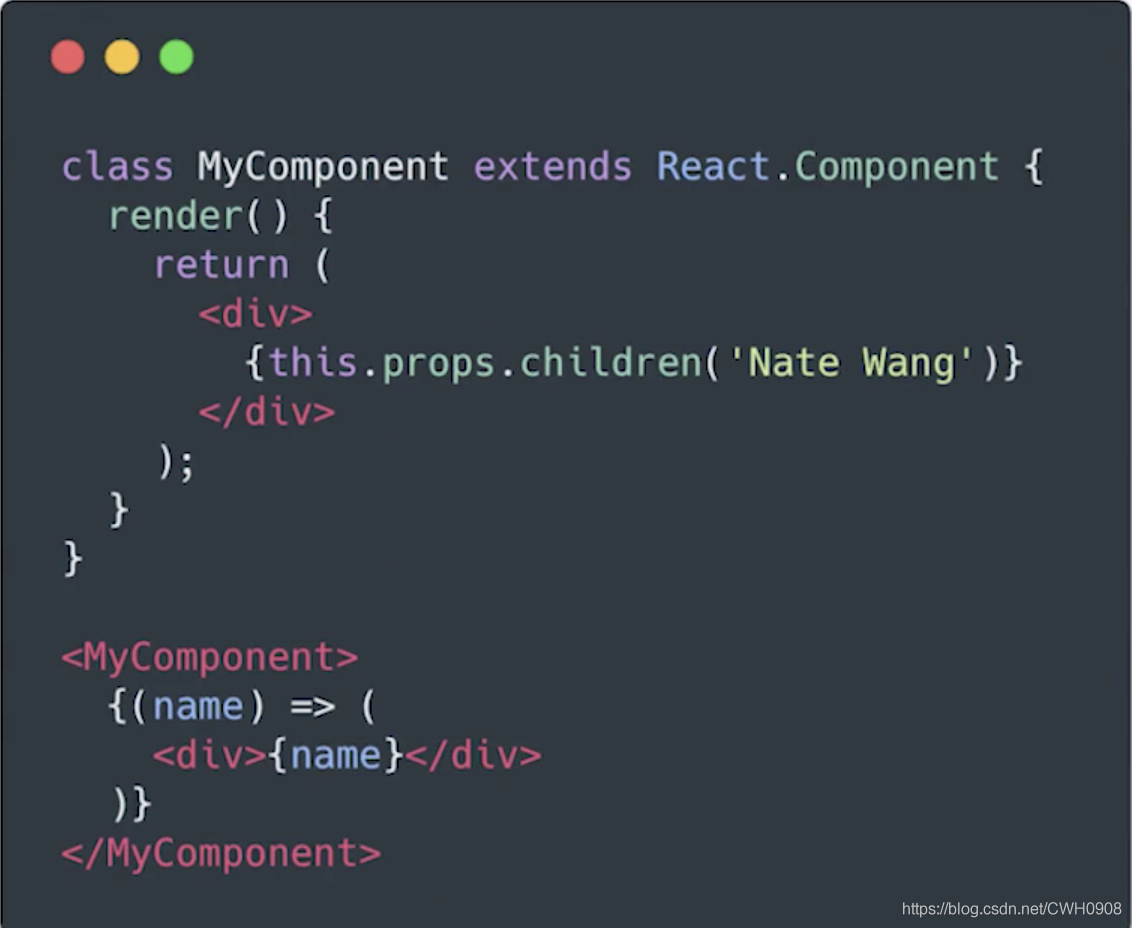
函数作为子组件
-
React 父组件如何调用子组件中的方法?
1、如果是在方法组件中调用子组件(
>= react@16.8),可以使用useRef和useImperativeHandle:const { forwardRef, useRef, useImperativeHandle } = React; const Child = forwardRef((props, ref) => { useImperativeHandle(ref, () => ({ getAlert() { alert("getAlert from Child"); } })); return <h1>Hi</h1>; }); const Parent = () => { const childRef = useRef(); return ( <div> <Child ref={childRef} /> <button onClick={() => childRef.current.getAlert()}>Click</button> </div> ); };2、如果是在类组件中调用子组件(
>= react@16.4),可以使用createRef:const { Component } = React; class Parent extends Component { constructor(props) { super(props); this.child = React.createRef(); } onClick = () => { this.child.current.getAlert(); }; render() { return ( <div> <Child ref={this.child} /> <button onClick={this.onClick}>Click</button> </div> ); } } class Child extends Component { getAlert() { alert('getAlert from Child'); } render() { return <h1>Hello</h1>; } }
-
React 有哪些优化性能的手段?
类组件中的优化手段
1、使用纯组件
PureComponent作为基类。2、使用
React.memo高阶函数包装组件。3、使用
shouldComponentUpdate生命周期函数来自定义渲染逻辑。方法组件中的优化手段
1、使用
useMemo。2、使用
useCallBack。其他方式
1、在列表需要频繁变动时,使用唯一 id 作为 key,而不是数组下标。
2、必要时通过改变 CSS 样式隐藏显示组件,而不是通过条件判断显示隐藏组件。
3、使用
Suspense和lazy进行懒加载,例如:import React, { lazy, Suspense } from "react"; export default class CallingLazyComponents extends React.Component { render() { var ComponentToLazyLoad = null; if (this.props.name == "Mayank") { ComponentToLazyLoad = lazy(() => import("./mayankComponent")); } else if (this.props.name == "Anshul") { ComponentToLazyLoad = lazy(() => import("./anshulComponent")); } return ( <div> <h1>This is the Base User: {this.state.name}</h1> <Suspense fallback={<div>Loading...</div>}> <ComponentToLazyLoad /> </Suspense> </div> ) } }
Suspense用法可以参考官方文档
-
react hook
详细用法:React Hooks_友人CWH的博客-CSDN博客
- 常用的react hook API为useState (允许您将 React state(状态) 添加到函数式组件中) 和 useEffect 。
import { useState, useEffect } from 'react'; function Example() { const [count, setCount] = useState(0); // 声明一个名为 count 的 state(状态)变量,并将其设置为 0 。React 将记住它在重新渲染之间的当 //前值,并为我们的函数提供最新的值。如果我们想要更新当前 count ,我们可以调用 setCount。 return <div> 读取 state(状态)可以直接使用count而无需使用this.state.count {count} <button onClick={() => setCount(count + 1)}> Click me </button> </div> }
- Hooks 使用的是您已经知道的 React 功能,只是采用了更直接的方式 - 例如 state(状态),lifecycle(生命周期),context(上下文) 和 refs 。 它们并没有从根本上改变 React 的工作方式,而且您对组件,props(属性) 和自上而下数据流的了解也同样重要。
- 可以将
useEffectHook 视为componentDidMount,componentDidUpdate和componentWillUnmount的组合。



-
mixin、hoc、render props、react-hooks的优劣如何?
Mixin的缺陷:
- 组件与
Mixin之间存在隐式依赖(Mixin经常依赖组件的特定⽅法,但在定义组件时并不知道这种依赖关系)- 多个
Mixin之间可能产⽣冲突(⽐如定义了相同的state字段)Mixin倾向于增加更多状态,这降低了应⽤的可预测性(The more state in your application, the harder it is to reason about it.),导致复杂度剧增- 隐式依赖导致依赖关系不透明,维护成本和理解成本迅速攀升:
- 难以快速理解组件⾏为,需要全盘了解所有依赖
Mixin的扩展⾏为,及其之间的相互影响- 组价⾃身的⽅法和
state字段不敢轻易删改,因为难以确定有没有Mixin依赖它Mixin也难以维护,因为Mixin逻辑最后会被打平合并到⼀起,很难搞清楚⼀个Mixin的输⼊输出HOC相⽐Mixin的优势:
HOC通过外层组件通过Props影响内层组件的状态,⽽不是直接改变其State不存在冲突和互相⼲扰,这就降低了 耦合度- 不同于
Mixin的打平+合并,HOC具有天然的层级结构(组件树结构),这⼜降低了复杂度HOC的缺陷:
- 扩展性限制:
HOC⽆法从外部访问⼦组件的State因此⽆法通过shouldComponentUpdate滤掉不必要的更新,React在⽀持ES6 Class之后提供了React.PureComponent来解决这个问题Ref传递问题:Ref被隔断,后来的React.forwardRef来解决这个问题Wrapper Hell:HOC可能出现多层包裹组件的情况,多层抽象同样增加了复杂度和理解成本- 命名冲突: 如果⾼阶组件多次嵌套,没有使⽤命名空间的话会产⽣冲突,然后覆盖⽼属性
- 不可⻅性:
HOC相当于在原有组件外层再包装⼀个组件,你压根不知道外层的包装是啥,对于你是⿊盒Render Props优点:
- 上述
HOC的缺点Render Props都可以解决Render Props缺陷:
- 使⽤繁琐:
HOC使⽤只需要借助装饰器语法通常⼀⾏代码就可以进⾏复⽤,Render Props⽆法做到如此简单- 嵌套过深:
Render Props虽然摆脱了组件多层嵌套的问题,但是转化为了函数回调的嵌套React Hooks优点:
- 简洁:
React Hooks解决了HOC和Render Props的嵌套问题,更加简洁- 解耦:
React Hooks可以更⽅便地把UI和状态分离,做到更彻底的解耦- 组合:
Hooks中可以引⽤另外的Hooks形成新的Hooks,组合变化万千- 函数友好:
React Hooks为函数组件⽽⽣,从⽽解决了类组件的⼏⼤问题:
this指向容易错误- 分割在不同声明周期中的逻辑使得代码难以理解和维护
- 代码复⽤成本⾼(⾼阶组件容易使代码量剧增)
React Hooks缺陷:
- 额外的学习成本(
Functional Component与Class Component之间的困惑)- 写法上有限制(不能出现在条件、循环中),并且写法限制增加了重构成本
- 破坏了
PureComponent、React.memo浅⽐较的性能优化效果(为了取最新的props和state,每次render()都要重新创建事件处函数)- 在闭包场景可能会引⽤到旧的
state、props值- 内部实现上不直观(依赖⼀份可变的全局状态,不再那么“纯”)
React.memo并不能完全替代shouldComponentUpdate(因为拿不到state change,只针对props change)
-
react 文章
Webpack面试题
-
什么是Webpack
WebPack可以看做是模块打包机,在webpack里一切文件皆模块。它做的事情是,分析你的项目结构,找到JavaScript模块以及其它的一些浏览器不能直接运行的拓展语言(Scss,TypeScript等),并将其打包为合适的格式以供浏览器使用。
-
webpack与grunt、gulp的不同?
- Gulp/Grunt是一种能够优化前端的开发流程的工具。
- WebPack是一种模块化的解决方案,不过Webpack的优点使得Webpack在很多场景下可以替代Gulp/Grunt类的工具。
他们的工作方式也有较大区别:
- Grunt和Gulp的工作方式是:在一个配置文件中,指明对某些文件进行类似编译,组合,压缩等任务的具体步骤,工具之后可以自动替你完成这些任务。
- Webpack的工作方式是:把你的项目当做一个整体,通过一个给定的主文件(如:index.js),Webpack将从这个文件开始找到你的项目的所有依赖文件,使用loaders处理它们,最后打包为一个(或多个)浏览器可识别的JavaScript文件。
三者都是前端构建工具,grunt和gulp在早期比较流行,现在webpack相对来说比较主流,不过一些轻量化的任务还是会用gulp来处理,比如单独打包CSS文件等。
- grunt和gulp是基于任务和流的。类似jQuery,找到一个(或一类)文件,对其做一系列链式操作,更新流上的数据, 整条链式操作构成了一个任务,多个任务就构成了整个web的构建流程。
- webpack是基于入口的。webpack会自动地递归解析入口所需要加载的所有资源文件,然后用不同的Loader来处理不同的文件,用Plugin来扩展webpack功能。
- gulp和grunt是流管理工具,通过一个个task配置执行用户需要的功能,如格式检验,代码压缩等,值得一提的是,经过这两者处理的代码只是局部变量名被替换简化,整体并没有发生改变,还是你的代码。
- webpack则进行了更彻底的打包处理,更加偏向对模块语法规则进行转换。主要任务是突破浏览器的鸿沟,将原本浏览器不能识别的规范和各种各样的静态文件进行分析,压缩,合并,打包,最后生成浏览器支持的代码,因此,webapck打包过后的代码已经不是你写的代码了,或许你再去看,已经看不懂啦
-
NPM和webpack的关系
-
分别介绍bundle,chunk,module是什么
- bundle:是由webpack打包出来的文件,
- chunk:代码块,一个chunk由多个模块组合而成,用于代码的合并和分割。
- module:是开发中的单个模块,在webpack的世界,一切皆模块,一个模块对应一个文件,webpack会从配置的entry中递归开始找出所有依赖的模块。
-
分别介绍什么是loader?什么是plugin?
- loader:模块转换器,用于将模块的原内容按照需要转成你想要的内容
- plugin:在webpack构建流程中的特定时机注入扩展逻辑,来改变构建结果,是用来自定义webpack打包过程的方式,一个插件是含有apply方法的一个对象,通过这个方法可以参与到整个webpack打包的各个流程(生命周期)。
-
什么 是模块热更新?
模块热更新是webpack的一个功能,他可以使得代码修改过后不用刷新浏览器就可以更新,是高级版的自动刷新浏览器。
好处:保持应用的数据状态,节省调试时间,样式调试更快
-
如何可以自动生成webpack配置?
webpack-cli /vue-cli /etc ...脚手架工具
-
webpack-dev-server和http服务器如nginx有什么区别?
webpack-dev-server使用内存来存储webpack开发环境下的打包文件,并且可以使用模块热更新,他比传统的http服务对开发更加简单高效。
-
webpack和gulp区别(模块化与流的区别)
gulp强调的是前端开发的工作流程,我们可以通过配置一系列的task,定义task处理的事务(例如文件压缩合并、雪碧图、启动server、版本控制等),然后定义执行顺序,来让gulp执行这些task,从而构建项目的整个前端开发流程。
webpack是一个前端模块化方案,更侧重模块打包,我们可以把开发中的所有资源(图片、js文件、css文件等)都看成模块,通过loader(加载器)和plugins(插件)对资源进行处理,打包成符合生产环境部署的前端资源。
Git面试题
-
git和svn的优缺点。
Git是分布式版本控制系统,SVN是集中式版本控制系统
SVN优缺点
- 优点:
- 管理方便,逻辑明确,符合一般人思维习惯。
- 易于管理,集中式服务器更能保证安全性。
- 代码一致性非常高。
- 适合开发人数不多的项目开发。
- 缺点:
- 服务器压力太大,数据库容量暴增。
- 如果不能连接到服务器上,基本上不可以工作,看上面第二步,如果服务器不能连接上,就不能提交,还原,对比等等。
- 不适合开源开发(开发人数非常非常多,但是Google app engine就是用svn的)。但是一般集中式管理的有非常明确的权限管理机制(例如分支访问限制),可以实现分层管理,从而很好的解决开发人数众多的问题。
Git优缺点
- 优点:
- 适合分布式开发,强调个体。
- 公共服务器压力和数据量都不会太大。
- 速度快、灵活。
- 任意两个开发者之间可以很容易的解决冲突。
- 离线工作。
- 缺点:
- 学习周期相对而言比较长。
- 不符合常规思维。
- 代码保密性差,一旦开发者把整个库克隆下来就可以完全公开所有代码和版本信息。
-
Git 里面的 origin
origin 是默认的远程版本库名称,你可以在 .git/config 之中进行修改,事实上 git push origin master 的意思是 git push origin master:master (将本地的 master 分支推送至远端的 master 分支,如果没有就新建一个)
-
fetch和merge和pull的区别
pull相当于git fetch 和 git merge,即更新远程仓库的代码到本地仓库,然后将内容合并到当前分支。
- git fetch:相当于是从远程获取最新版本到本地,不会自动merge
- git merge : 将内容合并到当前分支
- git pull:相当于是从远程获取最新版本并merge到本地
-
常用命令
- git show # 显示某次提交的内容 git show $id
- git add # 将工作文件修改提交到本地暂存区
- git rm # 从版本库中删除文件
- git reset # 从暂存区恢复到工作文件
- git reset HEAD^ # 恢复最近一次提交过的状态,即放弃上次提交后的所有本次修改
- git diff # 比较当前文件和暂存区文件差异 git diff
- git log -p # 查看每次详细修改内容的diff
- git branch -r # 查看远程分支
- git merge # 将branch分支合并到当前分支
- git stash # 暂存
- git stash pop #恢复最近一次的暂存
- git pull # 抓取远程仓库所有分支更新并合并到本地
- git push origin master # 将本地主分支推到远程主分支
浏览器和网络协议
-
http 和 https 有何区别
- http是HTTP协议运行在TCP之上。所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。
- https是HTTP运行在SSL/TLS之上,SSL/TLS运行在TCP之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。此外客户端可以验证服务器端的身份,如果配置了客户端验证,服务器方也可以验证客户端的身份
-
TCP传输的三次握手
为了准确无误地把数据送达目标处,TCP协议采用了三次握手策略。用TCP协议把数据包送出去后,TCP不会对传送 后的情况置之不理,它一定会向对方确认是否成功送达。握手过程中使用了TCP的标志:SYN和ACK。
发送端首先发送一个带SYN标志的数据包给对方。接收端收到后,回传一个带有SYN/ACK标志的数据包以示传达确认信息。
最后,发送端再回传一个带ACK标志的数据包,代表“握手”结束。
若在握手过程中某个阶段莫名中断,TCP协议会再次以相同的顺序发送相同的数据包。
-
从输入URL到页面加载成功显示经历了什么
- 当发送一个URL请求时,不管这个URL是Web页面的URL还是Web页面上每个资源的URL,浏览器都会开启一个线程来处理这个请求,同时在远程DNS服务器上启动一个DNS查询。这能使浏览器获得请求对应的IP地址。
- 浏览器与远程`Web`服务器通过`TCP`三次握手协商来建立一个`TCP/IP`连接。该握手包括一个同步报文,一个同步-应答报文和一个应答报文,这三个报文在浏览器和服务器之间传递。该握手首先由客户端尝试建立起通信,而后服务器应答并接受客户端的请求,最后由客户端发出该请求已经被接受的报文。
- 一旦`TCP/IP`连接建立,浏览器会通过该连接向远程服务器发送`HTTP`的`GET`请求。远程服务器找到资源并使用HTTP响应返回该资源,值为200的HTTP响应状态表示一个正确的响应。
- 此时,`Web`服务器提供资源服务,客户端开始下载资源。请求返回后,便进入了我们关注的前端模块简单来说,浏览器会解析`HTML`生成`DOM Tree`,其次会根据CSS生成CSS Rule Tree,而`javascript`又可以根据`DOM API`操作`DOM`
总结:
- DNS解析
- TCP连接
- 发送HTTP请求
- 服务器处理请求并返回HTTP报文
- 浏览器解析渲染页面
- 连接结束
-
常见的HTTP状态码
面试常用:
- 200 请求成功。
- 301 永久重定向。
- 302 临时重定向。
- 304 请求已缓存。
- 403 无权限访问。
- 404 找不到该网页。
- 405 请求方式不支持。
- 500 服务器错误。
- 502 代理服务器响应错误。
- 504 代理服务器响应超时。
汇总:
- 100 Continue 继续,发送post请求时,已发送了http header之后服务端将返回此信息,表示确认,之后发送具体参数信息
- 200 OK 正常返回信息
- 201 Created 请求成功并且服务器创建了新的资源
- 202 Accepted 服务器已接受请求,但尚未处理
- 301 Moved Permanently 请求的网页已永久移动到新位置。
- 302 Found 临时性重定向。
- 303 SeeOther 临时性重定向,且总是使用 GET 请求新的 URI。
- 304 Not Modified 自从上次请求后,请求的网页未修改过。
- 400 BadRequest 服务器无法理解请求的格式,客户端不应当尝试再次使用相同的内容发起请求。
- 401 Unauthorized 请求未授权。
- 403 Forbidden 禁止访问。
- 404 NotFound 找不到如何与 URI 相匹配的资源。
- 500 InternalServer Error 最常见的服务器端错误。
- 503 ServiceUnavailable 服务器端暂时无法处理请求(可能是过载或维护)。
汇总:
- 2开头 (请求成功)表示成功处理了请求的状态代码。
200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
201 (已创建) 请求成功并且服务器创建了新的资源。
202 (已接受) 服务器已接受请求,但尚未处理。
203 (非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。
204 (无内容) 服务器成功处理了请求,但没有返回任何内容。
205 (重置内容) 服务器成功处理了请求,但没有返回任何内容。
206 (部分内容) 服务器成功处理了部分 GET 请求。
- 3开头 (请求被重定向)表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。
300 (多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
303 (查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。
304 (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
305 (使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
307 (临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
- 4开头 (请求错误)这些状态代码表示请求可能出错,妨碍了服务器的处理。
400 (错误请求) 服务器不理解请求的语法。
401 (未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
403 (禁止) 服务器拒绝请求。
404 (未找到) 服务器找不到请求的网页。
405 (方法禁用) 禁用请求中指定的方法。
406 (不接受) 无法使用请求的内容特性响应请求的网页。
407 (需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。
408 (请求超时) 服务器等候请求时发生超时。
409 (冲突) 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。
410 (已删除) 如果请求的资源已永久删除,服务器就会返回此响应。
411 (需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。
412 (未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。
413 (请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
414 (请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。
415 (不支持的媒体类型) 请求的格式不受请求页面的支持。
416 (请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态代码。
417 (未满足期望值) 服务器未满足"期望"请求标头字段的要求。
- 5开头(服务器错误)这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。
500 (服务器内部错误) 服务器遇到错误,无法完成请求。
501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。
504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505 (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
-
浏览器的内核分别是什么
- Chrome:Blink(基于webkit,Google与Opera Software共同开发)
- IE: trident内核
- Firefox:gecko内核
- Safari:webkit内核
- Opera:以前是presto内核,Opera现已改用Google Chrome的Blink内核
-
优雅降级和渐进增强
- 优雅降级:(常用,兼容IE)
一开始就构建完整的功能,然后再针对低版本浏览器进行兼容。
- 渐进增强:
针对低版本浏览器进行构建页面,保证最基本的功能,然后再针对高级浏览器进行效果、交互等改进和追加功能达到更好的用户体验。
-
浏览器是如何渲染页面
- 解析HTML文件,创建DOM树。自上而下,遇到任何样式(link、style)与脚本(script)都会阻塞(外部样式不阻塞后续外部脚本的加载)。
- 解析CSS。优先级:浏览器默认设置<用户设置<外部样式<内联样式
- 将CSS与DOM合并,构建渲染树(Render Tree)
- 布局和绘制,重绘(repaint)和重排(reflow)
-
关于事件循环
node端
Node 的 Event Loop 分为 6 个阶段,它们会按照顺序反复运行。每当进入某一个阶段的时候,都会从对应的回调队列中取出函数去执行。当队列为空或者执行的回调函数数量到达系统设定的阈值,就会进入下一阶段。
Event Loop 6 个阶段:
- timers
- I/O callbacks
- idle, prepare
- poll
- check
- close callbacks
浏览器端
浏览器端 的情况与 node端 的情况相仿,当我们执行 JS 代码的时候其实就是往执行栈中放入函数,当遇到异步的代码时,会被挂起并在需要执行的时候加入到 Task(有多种 Task) 队列中。一旦执行栈为空,Event Loop 就会从 Task 队列中拿出需要执行的代码并放入执行栈中执行。
- 微任务(microtask)
- process.nextTick
- promise
- Object.observe(曾经是提案,如今已经废除)
- MutationOberver
- 宏任务(macrotask)
- script
- setTimeout
- setInterval
- setImmediate
- I/O
- UI渲染
执行顺序如下:
- 执行同步代码,这是宏任务
- 执行栈为空,查询是否有微任务要执行
- 必要时渲染UI
- 进行下一轮的 EventLoop ,执行宏任务中的异步代码
参考链接:JS事件循环——宏任务和微任务
setTimeout 误差
上面讲了定时器是属于 宏任务(macrotask) 。如果当前 执行栈 所花费的时间大于 定时器 时间,那么定时器的回调在 宏任务里,来不及去调用,所有这个时间会有误差。
我们看以下代码:
setTimeout(function () { console.log('biubiu'); }, 1000); //某个执行时间很长的函数();如果定时器下面的函数执行要 5秒钟,那么定时器里的log 则需要 5秒之后再执行,函数占用了当前 执行栈 ,要等执行栈执行完毕后再去读取 微任务(microtask),等 微任务(microtask) 完成,这个时候才会去读取 宏任务 里面的 setTimeout 回调函数执行。setInterval 同理,例如每3秒放入宏任务,也要等到执行栈的完成。
-
垃圾回收机制方式
标记清除(常用)和引用计数。
- 标记清除:
定义和用法:当变量进入环境时,将变量标记"进入环境",当变量离开环境时,标记为:"离开环境"。某一个时刻,垃圾回收器会过滤掉环境中的变量,以及被环境变量引用的变量,剩下的就是被视为准备回收的变量。
到目前为止,IE、Firefox、Opera、Chrome、Safari的js实现使用的都是标记清除的垃圾回收策略或类似的策略,只不过垃圾收集的时间间隔互不相同。
- 引用计数:
定义和用法:引用计数是跟踪记录每个值被引用的次数。
基本原理:就是变量的引用次数,被引用一次则加1,当这个引用计数为0时,被视为准备回收的对象。
-
Web攻击技术
- XSS 跨站脚本攻击,是说攻击者通过注入恶意的脚本,在用户浏览网页的时候进行攻击,比如获取cookie,或者其他用户身份信息,可以分为存储型和反射型,存储型是攻击者输入一些数据并且存储到了数据库中,其他浏览者看到的时候进行攻击,反射型的话不存储在数据库中,往往表现为将攻击代码放在url地址的请求参数中。主要是前端层面的,用户在输入层面插入攻击脚本,改变页面的显示,或则窃取网站 cookie,
- 预防方法:不相信用户的所有操作,对用户输入进行一个转义,不允许 js 对 cookie 的读写,为cookie设置httpOnly属性,对用户的输入进行检查,进行特殊字符过滤
- CSRF 跨站请求伪造,可以理解为攻击者盗用了用户的身份,以用户的名义发送了恶意请求,比如用户登录了一个网站后,立刻在另一个tab页面访问量攻击者用来制造攻击的网站,这个网站要求访问刚刚登陆的网站,并发送了一个恶意请求,这时候CSRF就产生了,比如这个制造攻击的网站使用一张图片,但是这种图片的链接却是可以修改数据库的,这时候攻击者就可以以用户的名义操作这个数据库。即以你的名义,发送恶意请求。
- 预防方法:使用验证码,检查https头部的refer,使用token,通过 cookie 加参数等形式过滤

-
理解Cookie和session机制
http是无状态协议,会话(Session)跟踪是Web程序中常用的技术,用来跟踪用户的整个会话。常用的会话跟踪技术是Cookie与Session。Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份。
- Cookie就是由服务器发给客户端的特殊信息,而这些信息以文本文件的方式存放在客户端,然后客户端每次向服务器发送请求的时候都会带上这些特殊的信息。
- Session技术则是服务端的解决方案,它是通过服务器来保持状态的。客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。这就是Session。客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了。
- 虽然Session保存在服务器,对客户端是透明的,它的正常运行仍然需要客户端浏览器的支持。这是因为Session需要使用Cookie作为识别标志。HTTP协议是无状态的,Session不能依据HTTP连接来判断是否为同一客户,因此服务器向客户端浏览器发送一个名为JSESSIONID的Cookie,它的值为该Session的id(也就是HttpSession.getId()的返回值)。Session依据该Cookie来识别是否为同一用户。
参考文章:理解Cookie和Session机制

-
Cookie和session、storage的区别和联系

-
缓存相关的Http请求头
headers字段 解释 案例 Expires
服务端告诉浏览器,先把这个文件缓存起来,在这个过期时间之前,该文件都不会变化
Expires: Mon, 1 Aug 2016 22:43:02 GMT
Cache-Control
由于Expires给定的是绝对时间,而客户端的系统时间可以由用户任意修改, Cache-Control为相对时间
Cache-Control: max-age=80
Last-Modified(response header) / If-Modified-Since (request header)
服务端收到请求后会对比目前文件的最后修改时间和该请求头的信息,如果没有修改,那就直接返回304给浏览器,而不返回实际资源。如果有变化了,就返回200,并且带上新的资源内容
If-Modified-Since:Mon, 01 Aug 2016 13:48:44 GMT
Etag / If-None-Match
第一次请求后响应头中包含了Etag,作为时间标签,下一次请求时会把原来的Etag标签带上(在请求头中变成了If-None-Match)作为校验标准,若这个文件如果发生了改变,则Etag也会改变。服务器对比浏览器请求头中的的If-None-Match:如果相同就返回304,而不返回实际资源如果不同,就返回200和新的资源。
-
观察者模式和发布-订阅模式的区别
1. 从定义上:
- 观察者模式: 在软件设计中是一个对象,维护一个依赖列表,当任何状态发生改变自动通知它们。
- 发布-订阅设计模式: 在发布-订阅模式,消息的发送方,叫做发布者,消息不会直接发送给特定的接收者,叫做订阅者。
2. 区别:
- 在观察者模式中,观察者知道被观察者,被观察者一直保持对观察者进行记录。在发布订阅模式中,发布者和订阅者不知道对方的存在, 它们只有通过消息代理进行通信•在发布订阅模式中,组件是松散耦合的,正好和观察者模式相反。
- 观察者模式大多数时候是同步的,比如当事件触发,被观察者就会去调用观察者的方法。而发布-订阅模式大多数时候是异步的(使用消息队列)。
- 观察者模式需要在单个应用程序地址空间中实现,而发布-订阅更像交叉应用模式。
性能优化
1.压缩css,js,图片
2.减少http请求次数, 合并css,js 合并图片(雪碧图)
3.使用CDN
4.减少dom元素数量
5.图片懒加载
6.静态资源另外用无cookie的域名
7.减少dom的访问(缓存dom)
8.巧用事件委托
9.样式表置顶、脚本置底
其他
yran对比npm的优势
并行安装:无论
npm还是yarn在执行包的安装时,都会执行一系列任务。npm是按照队列执行每个package,也就是说必须要等到当前package安装完成之后,才能继续后面的安装。而yarn是同步执行所有任务,提高了性能。离线模式:如果之前已经安装过一个软件包,用
yarn再次安装时之间从缓存中获取,就不用像npm那样再从网络下载了。安装版本统一:为了防止拉取到不同的版本,
yarn有一个锁定文件 (lock file) 记录了被确切安装上的模块的版本号。每次只要新增了一个模块,yarn就会创建(或更新)yarn.lock这个文件。这么做就保证了,每一次拉取同一个项目依赖时,使用的都是一样的模块版本。更好的语义化:
yarn改变了一些npm命令的名称,比如yarn add/remove,比npm原本的install/uninstall要更清晰。