抓取猫眼电影排行上
经过一系列基础知识的铺垫,我们将学习利用requests库和正则表达式来抓取猫眼TOP100的相关内容。
一、抓取首页
首先抓取第一页的内容。我们实现了get__one__page()方法,并给它传入url参数。然后将抓取的页面结果返回,再通过main()方法调用。初步代码实现如下:
import requests
def get_one_page(url):
headers={
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.03.3325.162 Safari/537.36'
}
response=requests.get(url, headers=headers)
if response.status_code==200:
return response.text
return None
def main():
url='http://maoyan.com/board/4'
html=get_one_page(url)
print(html)
main()这样运行后,就可以成功获取首页的源代码了。然后就需要解析页面,提取出我们想要的信息。
二、正则提取
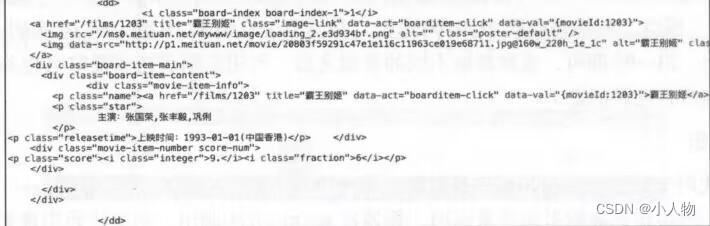
可以看到一部电影对应的源代码是一个dd节点,我们用正则表达式来提取这里面的一些电影信息。首先,需要提取它的排名信息。而它的排名信息是在class为board-index的i节点内,这里利用非贪婪匹配来提取i节点内的信息,正则表达式为:<dd>.*?board-index.*?>(.*?)</i>
随后需要提取电影的图片。可以看到,后面有a节点,其内部有两个img节点。经过检查后发现,第二个img节点的data-src属性是图片链接。提取正则表达式为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)"
再往后,需要提取电影的名称,它在后面的p节点内,class为name。所以,可以用name做一个标致位,然后进一步提取到其内a节点的正文内容,此时正则表达式为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?a.*?>(.*?)</a>
同理,提取主演、发布时间、评分等,总正则表达式为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)integer.*?>(.*?)</i>.*?</dd>
def parse_one_page(html):
pattern=re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>',
re.S)
items = re.findall(pattern, html)
print(items)这样就可以成功地将一页的10个信息都提取出来,这时一个列表形式。
但数据比较杂乱,我们再将匹配结果处理一下,遍历提取结果并生成字典,此时方法改写如下:
def parse_one_page(html):
pattern=re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>',
re.S)
items = re.findall(pattern, html)
print(items)
for item in items:
yield{
'index':item[0],
'image': item[1],
'title': item[2].strip(),
'actor': item[3].strip()[3:] if len(item[3])>3 else '',
'time': item[4].strip()[5:] if len(item[4])>5 else '',
'score':item[5].strip() + item[6].strip()
}