【SparkML系列3】特征提取器TF-IDF、Word2Vec和CountVectorizer
本节介绍了用于处理特征的算法,大致可以分为以下几组:
- 提取(Extraction):从“原始”数据中提取特征。
- 转换(Transformation):缩放、转换或修改特征。
- 选择(Selection):从更大的特征集中选择一个子集。
- 局部敏感哈希(Locality Sensitive Hashing, LSH):这类算法结合了特征转换的方面与其他算法。
Feature Extractors(特征提取器)
TF-IDF
词频-逆文档频率(Term frequency-inverse document frequency,简称TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,用以反映一个词语对于语料库中文档的重要性。用t表示一个词语,用d表示一个文档,用D表示语料库。词频TF(t,d)是词语t在文档d中出现的次数,而文档频率DF(t,D)是包含词语t的文档数量。如果我们仅使用词频来衡量重要性,那么很容易过分强调那些出现非常频繁但对文档信息贡献较小的词语,例如“a”、“the”和“of”。如果一个词语在整个语料库中出现得非常频繁,这意味着它对特定文档没有携带特殊信息。逆文档频率是衡量一个词语提供了多少信息的数值度量:
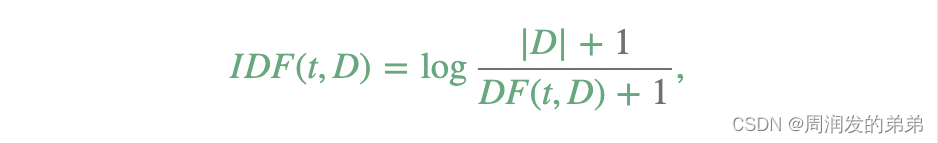
其中|D|是语料库中文档的总数。由于使用了对数,如果一个词语出现在所有文档中,其逆文档频率(IDF)值将变为0。注意,为了避免对语料库外的词语进行除零操作,应用了平滑项。TF-IDF值简单地是词频(TF)和逆文档频率(IDF)的乘积:
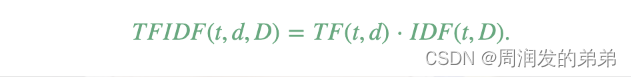
在词频和文档频率的定义上有几种不同的变体。在MLlib中,我们将TF和IDF分开,以使它们更加灵活。
TF:HashingTF和CountVectorizer都可以用来生成词频向量。
HashingTF是一个Transformer,它接受一组词语并将这些集合转换成固定长度的特征向量。在文本处理中,“一组词语”可能是一个词袋。HashingTF利用哈希技巧。通过应用一个哈希函数,将一个原始特征映射到一个索引(词项)上。这里使用的哈希函数是MurmurHash 3。然后根据映射后的索引计算词频。这种方法避免了计算全局的词到索引映射表,这对于大型语料库来说可能代价很高,但它会遭受潜在的哈希冲突,不同的原始特征经过哈希可能会变成相同的词项。为了减少冲突的机会,我们可以增加目标特征维度,即哈希表的桶数。由于使用简单的模运算来确定向量索引,建议使用2的幂作为特征维度,否则特征将不会均匀地映射到向量索引上。默认的特征维度是2的18次方,即262,144。一个可选的二元切换参数控制词频计数。当设置为true时,所有非零频率计数都设置为1。这对于模拟二元而不是整数计数的离散概率模型特别有用。
CountVectorizer将文本文档转换为词项计数向量。有关更多详情,请参考CountVectorizer。
IDF:IDF是一个估计器,它在数据集上进行训练并产生一个IDFModel。IDFModel接受特征向量(通常由HashingTF或CountVectorizer创建)并对每个特征进行缩放。直观地说,它降低了在语料库中频繁出现的特征的权重。
注意:spark.ml不提供文本分割工具。我们推荐用户使用斯坦福NLP小组的工具和scalanlp/chalk。
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}
import org.apache.spark.sql.SparkSession
/**
* @description TfIdfExample
* @date 2024/1/31 18:09
* @author by fangwen1
*/
object TfIdfExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[*]")
.appName("TfIdfExample")
.getOrCreate()
// 创建测试数据集
val sentenceData = spark.createDataFrame(Seq(
(0.0, "Hi I heard about Spark"),
(0.0, "I wish Java could use case classes"),
(1.0, "Logistic regression models are neat")
)).toDF("label", "sentence")
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
// 将文本转换成词,分词操作
val wordsData = tokenizer.transform(sentenceData)
wordsData.printSchema()
val hashingTF = new HashingTF()
.setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(20)
// 将词转换成特征
val featurizedData = hashingTF.transform(wordsData)
featurizedData.printSchema()
// alternatively, CountVectorizer can also be used to get term frequency vectors
//IDF来重新缩放特征向量
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
// 训练模型
val idfModel = idf.fit(featurizedData)
// 使用模型来测试数据
val rescaledData = idfModel.transform(featurizedData)
// 查看模型跑出来的特征数据
rescaledData.select("label", "features").show()
}
}
Word2Vec
Word2Vec是一个估计器(Estimator),它接受表示文档的单词序列,并训练一个Word2VecModel。该模型将每个单词映射到一个唯一的固定大小向量。Word2VecModel通过使用文档中所有单词的平均值将每个文档转换成一个向量;然后可以将这个向量用作预测、文档相似度计算等方面的特征。有关更多详细信息,请参阅MLlib用户指南中的Word2Vec部分。
示例
在下面的代码段中,我们从一组文档开始,每个文档都表示为一个单词序列。对于每个文档,我们将其转换为一个特征向量。然后,这个特征向量可以传递给一个学习算法。
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.feature.{Word2Vec, Word2VecModel}
/**
* @description Word2VecExample
* @date 2024/1/31 18:52
*/
object Word2VecExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[*]")
.appName("TfIdfExample")
.getOrCreate()
// 输入数据:每行数据都是一个词包
val documentDF = spark.createDataFrame(Seq(
"Hi I heard about Spark".split(" "),
"I wish Java could use case classes".split(" "),
"Logistic regression models are neat".split(" ")
).map(Tuple1.apply)).toDF("text")
// 将文本数据转换为数值向量形式
val word2Vec = new Word2Vec()
.setInputCol("text")
.setOutputCol("result")
.setVectorSize(3)
.setMinCount(0)
val model : Word2VecModel = word2Vec.fit(documentDF)
val result = model.transform(documentDF)
result.show()
}
}
CountVectorizer
CountVectorizer和CountVectorizerModel的目的是帮助将一系列文本文档转换成令牌计数的向量。当没有预先定义的词典时,CountVectorizer可以作为一个估计器来提取词汇,并生成一个CountVectorizerModel。该模型为文档在词汇表上生成稀疏表示,然后可以传递给其他算法,例如LDA。
在拟合过程中,CountVectorizer将选择在整个语料库中按词频排序的前vocabSize个词。一个可选的参数minDF也会影响拟合过程,它指定了一个词必须出现在多少个文档中才能被包含在词汇表中,这个数字可以是具体数目(如果小于1.0,则表示比例)。另一个可选的二元切换参数控制输出向量。如果设置为true,所有非零计数都会被设置为1。这对于建模二元计数而非整数计数的离散概率模型特别有用。
Examples
假设 我们有以下 DataFrame with columns id and texts:
| id | texts |
|---|---|
| 0 | Array(“a”, “b”, “c”) |
| 1 | Array(“a”, “b”, “b”, “c”, “a”) |
在texts中的每一行都是一个Array[String]类型的文档。调用CountVectorizer的fit会生成一个带有词汇表(a, b, c)的CountVectorizerModel。然后,在转换后,输出列“vector”包含:
| id | texts | vector |
|---|---|---|
| 0 | Array(“a”, “b”, “c”) | (3,[0,1,2],[1.0,1.0,1.0]) |
| 1 | Array(“a”, “b”, “b”, “c”, “a”) | (3,[0,1,2],[2.0,2.0,1.0]) |
每个向量表示文档在词汇表上的令牌计数。
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.feature.{CountVectorizer, CountVectorizerModel}
object CountVectorizerExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[*]")
.appName("TfIdfExample")
.getOrCreate()
val df = spark.createDataFrame(Seq(
(0, Array("a", "b", "c")),
(1, Array("a", "b", "b", "c", "a"))
)).toDF("id", "words")
// 从语料库中训练 CountVectorizerModel
val cvModel: CountVectorizerModel = new CountVectorizer()
.setInputCol("words")
.setOutputCol("features")
.setVocabSize(3)
.setMinDF(2)
.fit(df)
// 或者,用预先定义的词汇表来创建 CountVectorizerModel。
val cvm = new CountVectorizerModel(Array("a", "b", "c"))
.setInputCol("words")
.setOutputCol("features")
cvModel.transform(df).show(false)
}
}
FeatureHasher
特征哈希(FeatureHasher)将一组分类或数值特征投影到指定维度的特征向量中(通常远小于原始特征空间的维度)。这是通过使用哈希技巧将特征映射到特征向量中的索引来完成的。
FeatureHasher转换器操作多个列。每一列可以包含数值或分类特征。列数据类型的行为和处理方式如下:
数值列:对于数值特征,使用列名的哈希值来将特征值映射到其在特征向量中的索引。默认情况下,数值特征不被视为分类特征(即使它们是整数)。要将它们视为分类特征,请使用categoricalCols参数指定相关列。
字符串列:对于分类特征,使用字符串“column_name=value”的哈希值来映射到向量索引,指示值为1.0。因此,分类特征被“一键热编码”(类似于使用OneHotEncoder且dropLast=false)。
布尔列:布尔值的处理方式与字符串列相同。也就是说,布尔特征表示为“column_name=true”或“column_name=false”,指示值为1.0。
空值(缺失值)被忽略(在结果特征向量中隐式为零)。
这里使用的哈希函数也是HashingTF中使用的MurmurHash 3。由于使用哈希值的简单模运算来确定向量索引,建议使用2的幂作为numFeatures参数;否则,特征将不会均匀映射到向量索引上。
示例
假设我们有一个DataFrame,它包含4个输入列:real, bool, stringNum, 和 string。这些不同的输入数据类型将用来说明转换操作产生特征向量列的行为。
| real | bool | stringNum | string |
|---|---|---|---|
| 2.2 | true | 1 | foo |
| 3.3 | false | 2 | bar |
| 4.4 | false | 3 | baz |
| 5.5 | false | 4 | foo |
Then the output of FeatureHasher.transform on this DataFrame is:
| real | bool | stringNum | string | features |
|---|---|---|---|---|
| 2.2 | true | 1 | foo | (262144,[51871, 63643,174475,253195],[1.0,1.0,2.2,1.0]) |
| 3.3 | false | 2 | bar | (262144,[6031, 80619,140467,174475],[1.0,1.0,1.0,3.3]) |
| 4.4 | false | 3 | baz | (262144,[24279,140467,174475,196810],[1.0,1.0,4.4,1.0]) |
| 5.5 | false | 4 | foo | (262144,[63643,140467,168512,174475],[1.0,1.0,1.0,5.5]) |
生成的特征向量随后可以传递给学习算法。
import org.apache.spark.ml.feature.FeatureHasher
import org.apache.spark.sql.SparkSession
/**
* @description FeatureHasherExample
* @date 2024/1/31 19:21
*/
object FeatureHasherExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[*]")
.appName("TfIdfExample")
.getOrCreate()
val dataset = spark.createDataFrame(Seq(
(2.2, true, "1", "foo"),
(3.3, false, "2", "bar"),
(4.4, false, "3", "baz"),
(5.5, false, "4", "foo")
)).toDF("real", "bool", "stringNum", "string")
val hasher = new FeatureHasher()
.setInputCols("real", "bool", "stringNum", "string")
.setOutputCol("features")
val featurized = hasher.transform(dataset)
featurized.show(false)
}
}