橘子学ES实战操作01之集群模式如何实现快照备份
我们知道ES中通过副本在一定意义上实现了数据的备份和高可用。但是我们说万一副本数据丢失了,不小心被rm -f了,你就说逆天不逆天吧,此时要实现数据真正意义上的备份就要使用到快照机制,来把数据持久化备份起来,万一数据被删了,也能及时恢复。
而单节点的操作直接看官网操作即可。这里就不演示了。或者我后面再补充,实际开发我们一般都是集群模式,官网地址如下:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/snapshot-restore.html
集群模式略有不同,不同在于存储仓库必须是分布式的文件存储,不能在每个节点的本地配置,因为他要做分布式的备份和恢复读取。你要是像单节点那样本地配置会报错。
我们这里来操作一下集群模式下的快照备份。而且我这个是在离线环境下的操作,实际上和有网络也大差不差,主要是一个数据包的安装区别,你要是有网络直接安装就行,我这里需要拷贝一个数据包。
一、环境配置
1. 集群模式
2. 有的机器是多节点,有的机器是单节点。这样更加具有普遍性。
机器1:node1 node2
机器2:node3
3. 文件服务器,minio,配置信息如下
endPoint: http://192.168.1.1
port: 9000
accessKey: accessKey123
accessSecret: accessSecret123
二、准备材料
离线环境需要下载离线的S3插件包,用于连接s3文件服务器。和自己的ES下载版本一致的最好。我是7.17.7的。
S3插件包地址:https://artifacts.elastic.co/downloads/elasticsearch-plugins/repository-s3/repositorys3-7.17.7.zip,你要是有网络直接Install安装即可。
在minio中建立一个专用快照文件的bucket,我创建为leviBucket。
三、操作步骤
# 1、拷贝s3插件包到指定位置(我这里为/opt/elastic/version7/)
# 2、在离线环境安装s3插件包,进入到每个ES节点的bin下面,使用elasticsearch-plugin命令安装repository-s3插件,将命令中的<plugin•zip>替换为插件压缩包的路径和文件名:
bin/elasticsearch-plugin install file:///path/to/plugin-zip运行该命令后,Elasticsearch将解压缩并安装插件。一路yes即可。
比如我的目录对应的命令就是./bin/elasticsearch-plugin install file:///opt/elastic/version7/repository-s3-7.17.7.zip。
注意这一步需要再每个es节点都执行,不然对应的node节点起不来。
# 3、 设置elasticsearch.keystore
为每一个ES节点配置文件服务器的连接信息,授权。我的文件服务器为minio,所以进入ES的bin目录,执行以下两句命令。
bin/elasticsearch-keystore add s3.client.default.access_key
执行之后再输入命令位置,输入minio的access_key也就是accessKey123
bin/elasticsearch-keystore add s3.client.default.secret_key
执行之后再输入命令位置,输入minio的minio的secret_key也就是accessSecret123
# 4、修改ES每一个节点的配置文件elasticsearch.yml,配置s3文件服务器的位置端点,在每个elasticsearch.yml最后添加
s3.client.default.endpoint: minio ip:端口
s3.client.default.protocol: http
对应到我的环境就是
s3.client.default.endpoint: 192.168.1.1:9000
s3.client.default.protocol: http
# 5、配置完毕重启每个ES节点
四、配置快照
启动之后,连接kibana,首先创建快照仓库,也就是你的快照最后存储在哪里,ES允许以仓库分隔。以下操作都在kibana以DSL命令的方式进行操作。
1、创建快照仓库
这个仓库是在ES层面的仓库,来实际关联minio的。
PUT _snapshot/minio_s3_repository
{
"type": "s3",
"settings": {
"bucket": "leviBucket"
}
}
这里面的type类型就是s3,bucket就是我创建在monio用来存储我们快照文件的桶,这样就会把以后的快照放到这个桶位置下。
该命令即为创建仓库,其中_snapshot为es的api,minio_s3_repository为我创建的仓库名。
type类型指定为s3文件服务。
bucket:leviBucket即为我的快照文件在minio中存储的bucket。
2、创建快照生成策略
2.1、进入kibana操作台
2.2、选择快照配置位置查看仓库是否创建成功
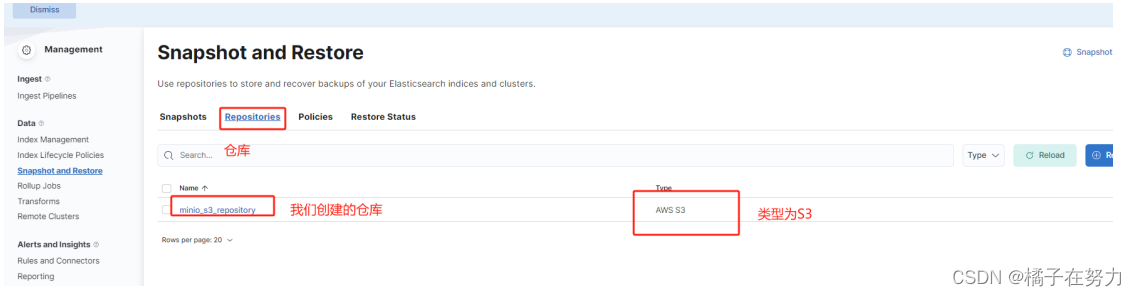
2.3、查看仓库,看到我们创建的仓库确实存在
这是我们刚才DSL创建的仓库。
2.4、创建策略
策略是快照策略,就是规定你的快照是怎么生成的,什么名字规则,什么生成时间间隔之类的。
1、进入策略位置。

2、create_policy创建快照
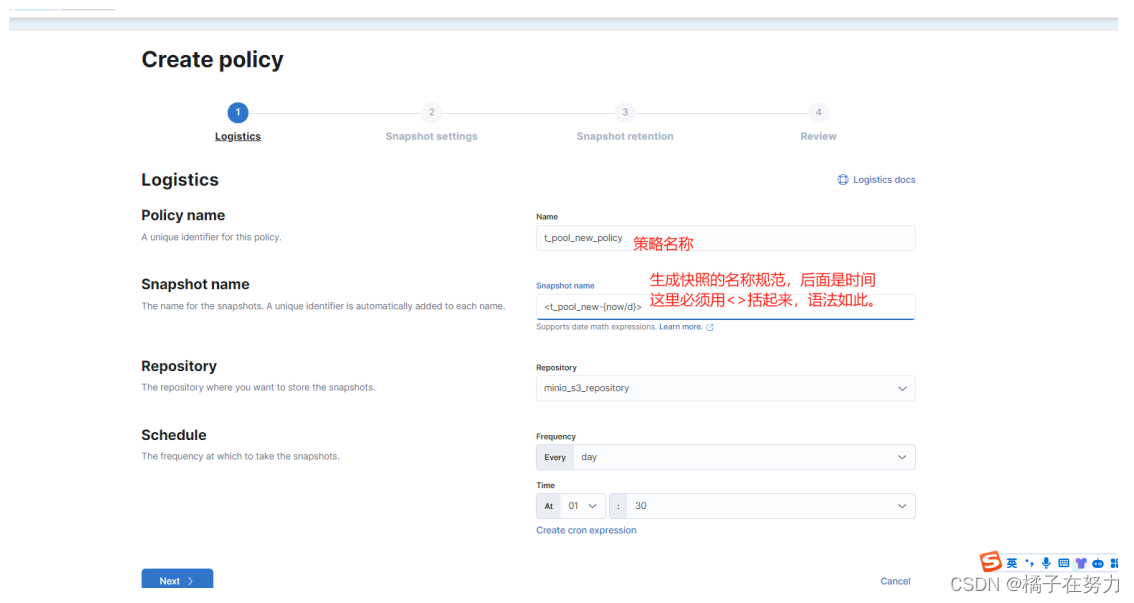
下面没有用红框写的分别是选中你的仓库和生成快照的定时任务。
选中仓库是表示你这个快照是在哪个仓库存储,定时任务表示多久执行一次创建快照。
3、然后进入下一步
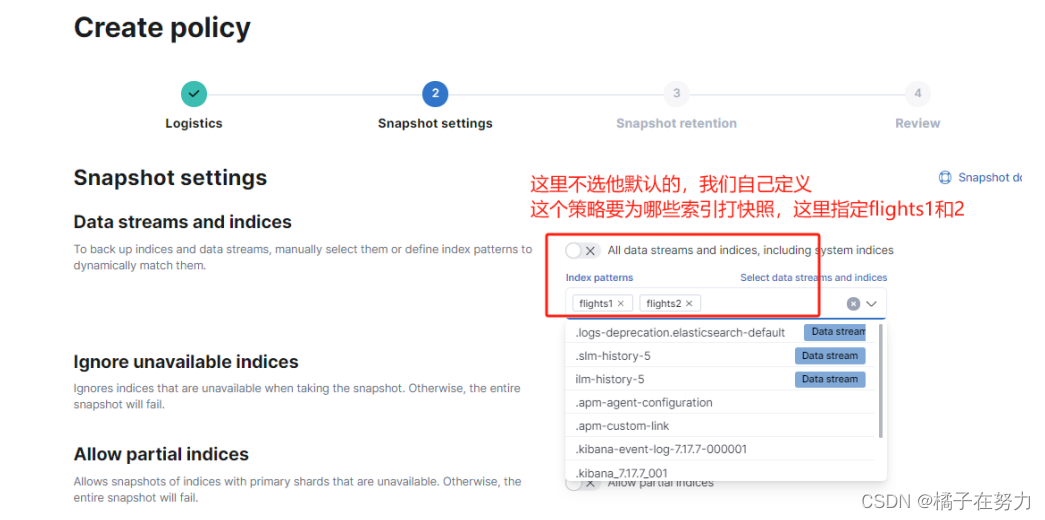
我们定义这个快照是为了flinght1和flight2做的,你也可以指定更多,或者用正则表达式更加方便。比如创建为levi*这样就是所有以levi开头的索引名字都能创建。
最后一路next就创建成功了。最后成功的就会在策略栏目下列出来。
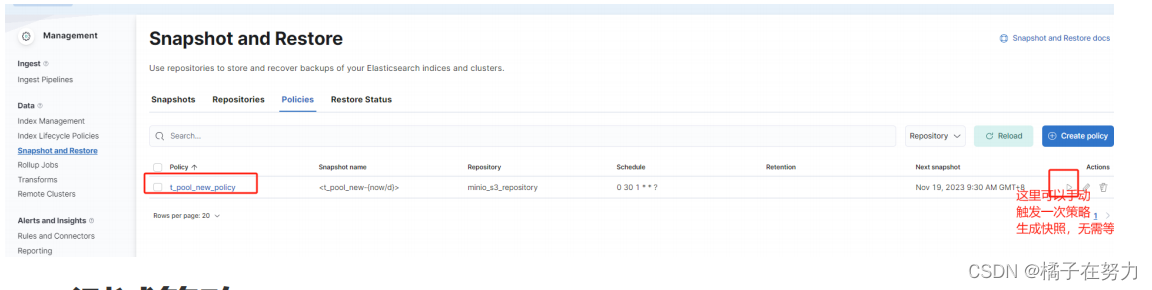
3、测试快照策略
我们创建了flights1和flights2索引,并且写入数据。

此时数据被写入,我们去手动触发一次快照生成。等不及定时任务了,你也可以等定时任务来触发创建。
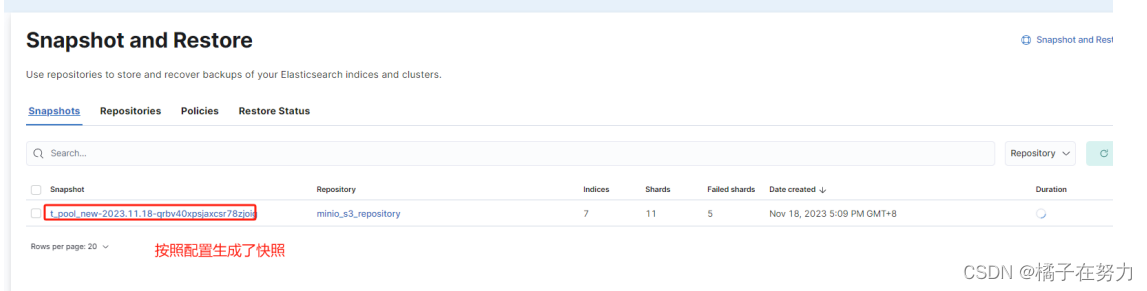
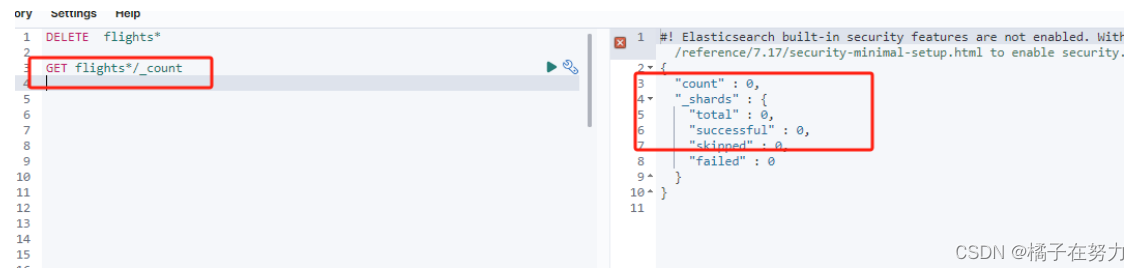
此时数据被持久化到minio中,完成备份。此时删除这两个索引。然后再次查询,无法查到数据,ES中已经没了数据,此时就是数据丢失了。这种删除副本数据也没了,那是真的丢了。
4、恢复数据
此时数据丢失,我们就使用刚才手动生成的快照来恢复数据。
# _snapshot为API
# minio_s3_repository为你的仓库
# t_pool_new-2023.11.18-4moglopcrkc5-wbf3dpkxa为你使用的快照,使用最新一个即可。
# _restore为恢复API
# wait_for_completion=true同步等待
# "indices": "flights1,flights2",指定恢复的索引
# 其余参数默认即可
POST /_snapshot/minio_s3_repository/t_pool_new-2023.11.18-8eb5f2ntspayw64cpnebw/_restore?wait_for_completion=true
{
"indices": "flights1,flights2",
"ignore_unavailable": true,
"include_global_state": false,
"include_aliases": false
}
此时就恢复了数据,再次检索即可。注意快照生成也是耗费IO和CPU资源的,如果能尽量保证集群稳定,快照生成时间间隔不要太频繁.
而且我们也看到,快照是依赖定时任务去触发的,也就是说在下次定时任务执行期间如果数据丢失,这个数据是不能被恢复的。因为还没生成快照备份。所以快照也是有一定的风险的。我们尽量不要随意的去执行删除操作,需要严格审核操作。