Hive数据倾斜之:数据类型不一致导致的笛卡尔积
Hive数据倾斜之:数据类型不一致导致的笛卡尔积
一、问题描述
如果两张表的jion,关联键分布较均匀,没有明显的热点问题,在执行的过程中出现了数据倾斜的情况,是什么原因
二、原因分析
数据倾斜通常会出现在关联操作或者聚合操作相关的位置,所以出现数据倾斜后,可以先排查一下是否出现了某个key的数量过多,对于上述的问题,排查之后发现并没有明显的热点key的问题。接下里就考虑是不是数据本身分布的原因,想想也不合理,最后查看了数据,发现关联键的长度很长,有19位,就开始怀疑是不是两张表的关联键类型不一致,导致了隐式转换,查询了数据类型,果真不一样,一个是bigint类型,一个是string类型
那么为什么类型不一致会出现隐式转换呢,把执行的sql的单独拿出来看下执行计划,发现了如下的一段神奇东东
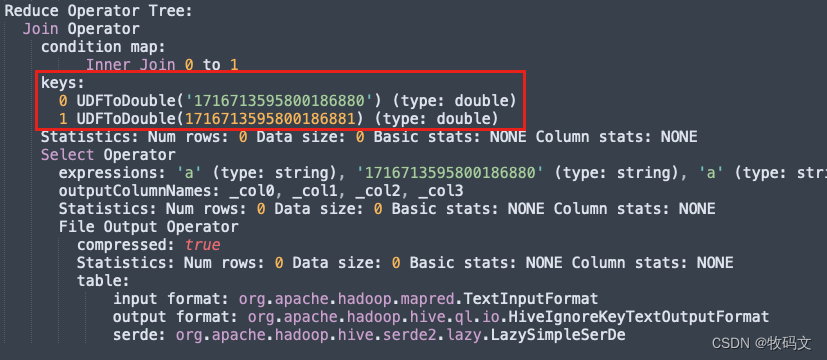
在hive2.7中,当类型不一致时,会自动将关联键转换为double类型,而double类型对于过大值的存储是有精度存储的
所以问题定位了,因为存在精度损失,所以那么多的key虽然不一样,但是被当作了一样,然后被无情的join在了一起,如果有2个key,就join4次,4个key,就join16次,那可不就倾斜了吗。
三、精度损失
所谓精度损失,就是在表示过大数值的时候会存在一定的误差。而double类型能准确的表示15-17位的数值,超过则会存在精度损失。
之所以double能精确表示15-17位数据,因为double类型是使用64位(8字节)来表示的。这意味着double类型的精度有53位。其中,52位用于表示有效数字(尾数),1位用于表示符号位。另外,double类型还有11位用于表示指数部分。由于双精度浮点数采用了IEEE 754标准,它可以表示非常大或非常小的数值,并且具有相对较高的精度。然而,由于浮点数的特性,它们可能会存在舍入误差和精度损失的问题。
比如:数值:171555543206125977 和 171555543206125979,在hive中就是想等的
输入:
select cast(171555543206125977 as double) = cast(171555543206125979 as double)
输出:
true
在双精度浮点数(double)中,无法精确地存储整数值1715555432061259777。由于双精度浮点数使用64位(8字节)来表示,其中一部分用于表示有效数字(尾数),一部分用于表示指数部分,还有一位用于表示符号位。
双精度浮点数的尾数部分有52位,可以精确地表示15到17位的十进制数值。而整数值1715555432061259777有19位,超过了双精度浮点数的精度范围。
当我们尝试将整数值1715555432061259777存储为双精度浮点数时,可能会出现舍入误差或精度损失。双精度浮点数会尽可能地接近给定的数值,但无法保证完全精确。
四、问题解决
解铃还需系铃人,既然是因为类型不一致导致的隐式转换从而导致的精度存储,那么就避免类型不一致的问题,在使用关联时候要确保关联键的类型一致,或者切换Spark引擎,因为Spark中不会出现这种问题