前端工程化基础(四):Git代码版本控制工具详解
Git版本控制工具详解
认识版本控制(版本控制)
- 是维护 工程蓝图的标准做法,能追踪工程蓝图从诞生一直到定案的过程
- 版本控制也是 一种软件工程技巧,借此能在软件开发的过程中,确保不同的人所编辑的同一程序都能得到同步
版本控制的功能
- 不同版本的存储管理
- 一个项目不断进行版本迭代,来修复之前的一些问题,增加新的功能等
- 如果手动维护的话,效率很低
- 重大版本的备份维护
- 恢复之前的项目版本
- 记录项目的点点滴滴
- 多人开发的代码合并
集中式版本控制
CVS和SVN属于集中式版本控制系统
- 他们的主要特点是 单一的集中管理的服务器,保存所有文件修订版本
- 系统开发人员通过客户端 连接到这台服务器,取出最新的文件或者提交更新
- 但是存在一个核心问题 :中央服务器不能出现故障
- 如果宕机一个小时,在这一个小时之内,谁都无法提交更新,也就无法协同工作
- 如果中心数据库所在的磁盘发生了损坏,且没有做备份,将会丢失所有的数据
- 项目的历史版本都会存在于中央服务器中
分布式版本控制
-
Git是属于分布式版本控制系统
-
客户端并不只提取最新版本的文件快照,而是把 代码仓库完整的镜像下来,包括完整的历史记录
-
这么一来,任何一处协同工作用的 服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复
-
因为每一次克隆操作,实际上都是一次对代码仓库的完整备份
-
与中央服务器不同的是,项目的历史版本,都会被克隆到协作开发的本地电脑,即每台电脑上都有备份
Bash-CMD-GUI区别
- Bash是Unix shell的一种, Linux与Mac OS X都将它作为默认的shell
- Git Bash 就是一个shell,是 windows下的命令行工具,可以执行Linux命令
- Git Bash是基于CMD的,在CMD的基础上增加了一些新的命令与功能
- Git CMD
- 命令提示符(CMD)是Windows操作系统上的命令行解释程序
- 其实就是 windows上面的CMD
- Git GUI
- 针对于不喜欢命令行界面的人
- 提供了一个 图形用户界面来运行Git命令
获取Git仓库 git clone/git init
- 当从零到一创建一个项目的时候,可以使用
git init创建一个新的仓库- 会生成一个.git文件
- 运行
git add .用于告诉git 管理当前目录下的所有文件 - 运行
git commit -m "描述"将本地文件提交到本地的git仓库中- 但没有提交到远程服务器中
- 当已经有一个项目,就可以复制远程仓库的地址,运行
git clone xxxxx
文件状态的划分
- Git在管理项目文件的时候,会对项目划分为以下几种状态
- **未跟踪:**一般在已经被Git管理的项目中,创建新文件的情况下
- **已跟踪:**当我们在项目文件中运行
git add .的命令后,就会将文件变为已跟踪的状态- **staged:**暂缓区中的文件状态,一般是在运行完
git add .命令后,就会放入暂缓区中 - **Unmodified:**运行完
git commit -m ""命令后,文件所处的状态,代表已经将代码提交到了本地的git仓库 - **Modified:**当对文件进行修改时候,文件的状态
- **staged:**暂缓区中的文件状态,一般是在运行完
- 运行命令顺序为
git add .git commit -m ""- 同时可以通过
git commit -a -m ""合并成一行代码
检查文件状态-git status
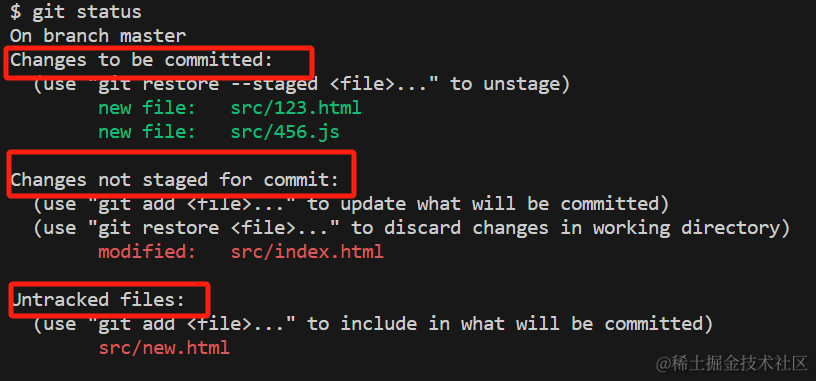
- 在项目目录下,输入命令 `git status,可以查看项目中的文件状态
git忽略文件
项目中存在特殊的文件(比如node_modules等),不希望git对其进行跟踪和管理的,可以对其进行忽略
- 创建 .gitignore文件即可啊,在文件中写入需要忽略的文件
- 实际开发中,不需要手动创建,通常框架的脚手架会自动生成
- 必要时候可以自己添加即可
- 在文件中写入的文件,使用
git status将不会查看该文件状态
test.js
- 在 github中有一个 gitignore项目,可以查看开发项目需要忽略的文件
Git的校验和
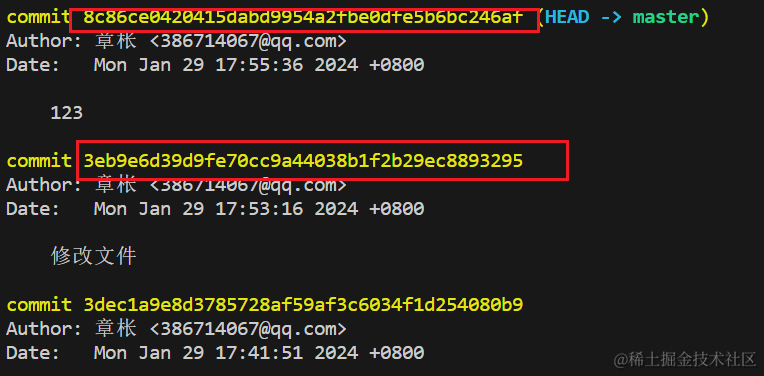
- 当我们输入
git log命令的时候,就可以查看到 commit后面跟着的字符串,这个字符串即为 校验和 - 校验和可以当作本次提交的唯一标识符,可以通过查看本次提交对文件的修改
- 校验和是通过SHA-1散列的算法生成的
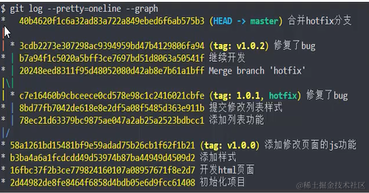
查看提交的历史 - git log
- 前面我们知道,可以通过
git log命令查看提交记录
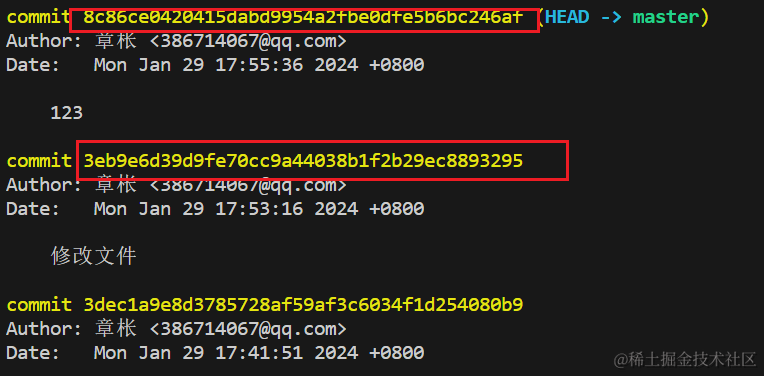
- 同时为了方便查看,我们可以使用
git log --pretty=oneline

- 通常在实际开发过程中,会有多个分支的出现,此时使用
git log --pretty=oneline --grapg进行查看
版本回退 - git reset
当我们对一个项目进行了多次的提交,想要回退到之前的版本,可以使用git reset命令进行操作
- 在上面的学习中,我们可以看到在最后一次提交后,commit的校验和后面都跟着一个 HEAD–>master
- 而 git reset实际上就是在 修改 HEAD的指向
git reset --hard HEAD^回退到上一版本git reset --hard xxxxx回退到指定的版本
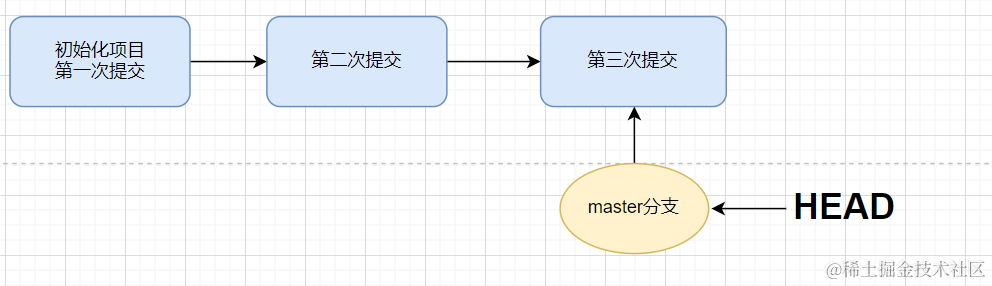
- 但是当我们回退到了指定的版本后,再通过
git log查看提交记录,会发现丢失了部分的提交记录

- 此时我们若想回到最新的提交记录,需要使用
git reflog命令进行查看所有的提交记录

- 之后通过
git reset --hard xxxxx命令即可恢复到最新的版本
远程仓库的操作
目前常用的三方远程仓库有:GitHub、Gitee以及GitLab
接下来我们以Gitee为例子,进行远程仓库的学习
创建Gitee账号以及创建一个仓库
- 登录Gitee官网进行账号注册
- 注册成功后,登录账号来到首页,创建一个新的仓库
- 输入仓库的名称,仓库的介绍等信息,之后选择创建仓库
- 此时我们就完成了一个仓库的创建
远程仓库拉取/提交代码 - git clone
当我们有了一个远程仓库的地址,可以使用
git clone的方式将仓库中的代码克隆下来但是在克隆的前,需要进行验证
远程仓库的验证-凭证
通过HTTPS协议克隆代码
-
因为HTTP协议是无状态的连接,所以每一次连接都需要输入用户名和密码
-
但是 Git拥有一个凭证系统,来保证我们只需要第一次输入凭证即可
-
当我们使用
git clone克隆代码的时候,会出现以下现象
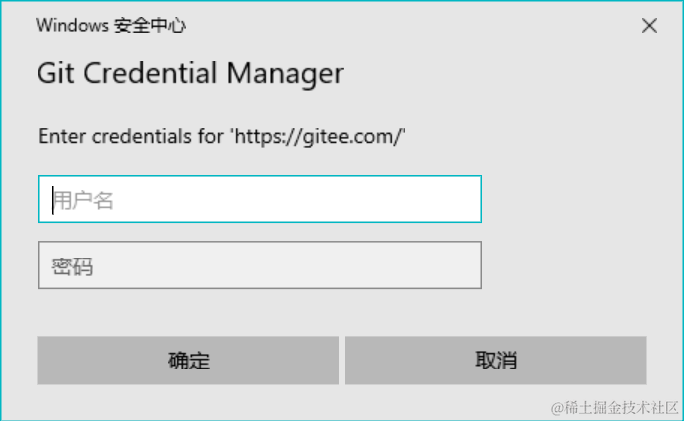
- 当我们输入完用户密码之后,Git就会将凭证自动保存下来,在后续的操作中,不用再输入凭证
- 随后我们就可以将修改完的代码进行提交
git add .git commit -m "描述"git push
本地仓库与远程仓库创建连接并push代码
当我们本地有一个项目,且通过
git init初始化了本地的仓库同时,再Gitee上面,有一个线上仓库
那么,我们想让这两个仓库创建连接,应当怎么做
- 首先进入到项目目录中,通过输入
git remote add '远程仓库地址' - 这样就建立了相应的连接
- 但是我们要清楚,本地仓库中有可能存在多个分支,远程仓库中也存在很多的分支
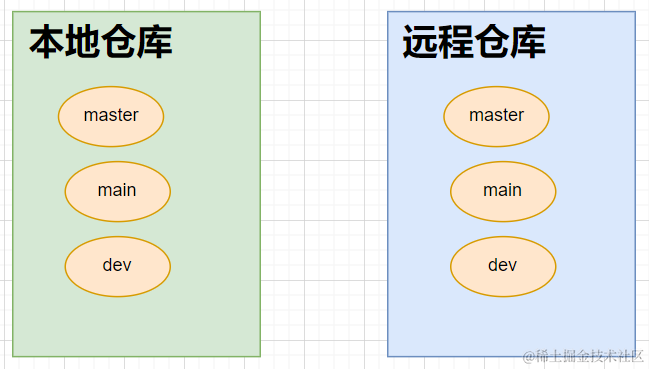
- 因此,为了顺利拉取提交代码,需要指定远程仓库的分支
git pull <remote> <branch>
本地分支的上游分支
每次拉取/提交代码的时候,都需要指定远程仓库的分支,会很麻烦,因此我们可以设置一下本地分支的上游分支,可以省略重复的步骤
-
通过输入命令
git branch --set-upstream-to=<远程仓库>/<远程仓库的分支> <本地仓库的分支> -
例如
git branch --set-upstream-to=origin/master master -
这样就设置了本地仓库的上游分支,可以直接通过 pull/push对代码进行提交以及拉取
拒绝合并不相干的历史
通常我们做了以上操作后,拉取代码的时候依旧会发生错误

- 在过去
git merge允许将两个没有共同基础的分支进行合并- 比如,我在本地创建了一个本地仓库,在Gitee上创建了一个远程仓库,这两个分支就没有共同的基础
- 这样造成 新创建的项目可能被一个维护者合并了很多没有必要的历史,到一个已经存在的项目中
- 而在 Git2.9版本之后,对 git merge进行了纠正,而我们可以通过
git merge --allow-unrelated-histories来恢复之前的操作 - 这样我们就可以正常的拉取代码了
Git标签(tag)
目的就是在某一个重大版本,打上版本的标签
创建标签
- 创建轻量标签
git tag v1.0.0 - 创建附注标签
git tag -a v1.0.1 -m "附注标签"
查看标签
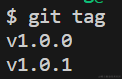
- 查看简单的标签
git tag
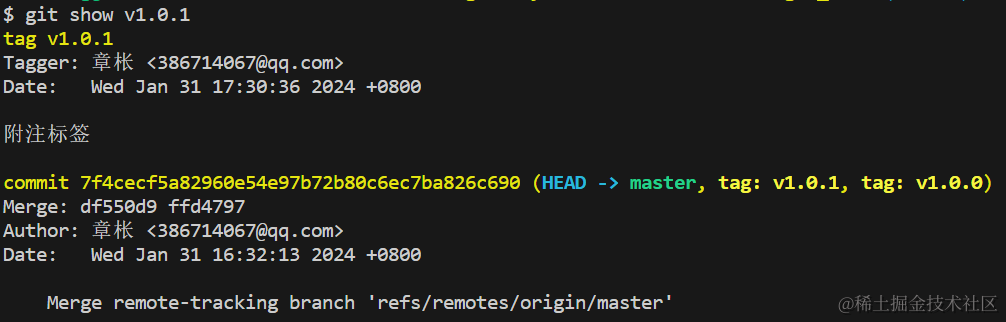
- 查看某一个tag的详细信息
git show v1.0.0
提交tag
- 提交某一个tag
git push origin v1.0.1 - 提交所有的tag
git push origin tags
删除tag
- 删除本地的tag
git tag -d v1.0.0 - 删除远程的tag
git push origin -d v1.0.1
检出tag
回退到某一个tag的版本
- 使用
git checkout v1.0.0即可
Git提交对象(Git原理)
前面我们对Git的基本操作进行了学习,那么它的底层原理是怎么样的
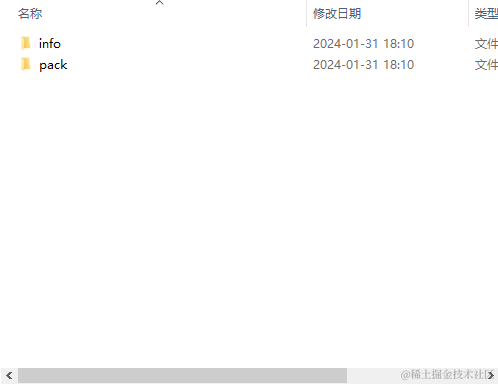
- 我们从0-1创建一个项目,首先需要使用
git init初始化本地仓库- 在项目文件夹下面会自动生成一个 .git的隐藏文件夹
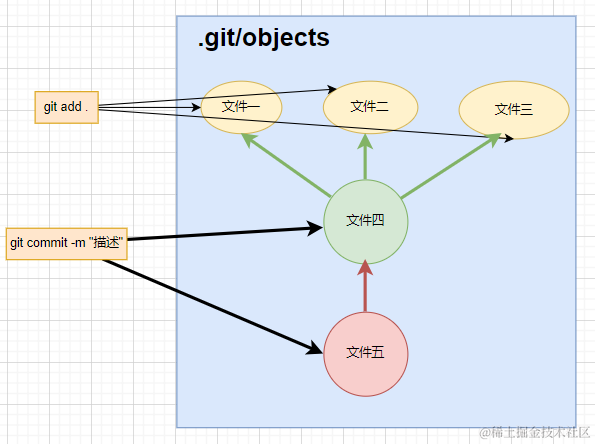
- 而我们项目的文件就会保存在 .git/objects文件夹下面
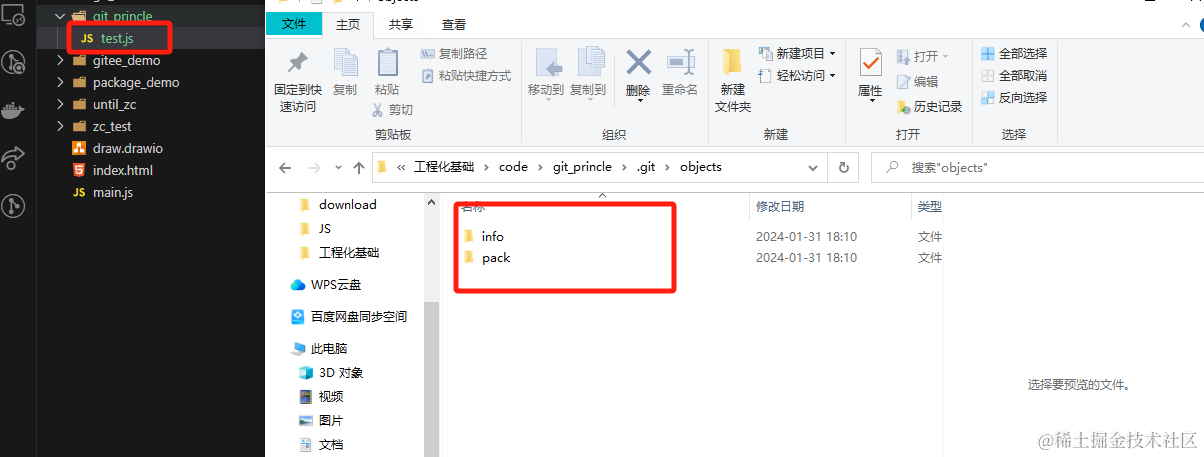
- 我们在项目中新增一个 test.js文件,其中写入
console.log(123)代码- 此时objects文件夹中没有变化
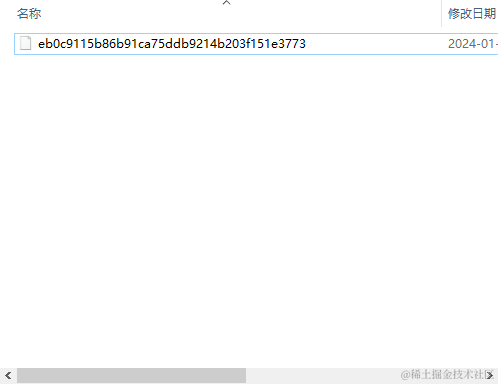
- 当我们运行
git add .命令后,会生成一个文件夹- 文件夹里面会包含一长串的字符串

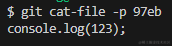
- 我们可以通过
git cat-file -p 文件夹名称+文件名称查看这个文件中的具体内容git cat-file -p 97eb- 由此我们可以知道,
git add .命令就会将我们的文件转成二进制文件保存在 objects文件夹中
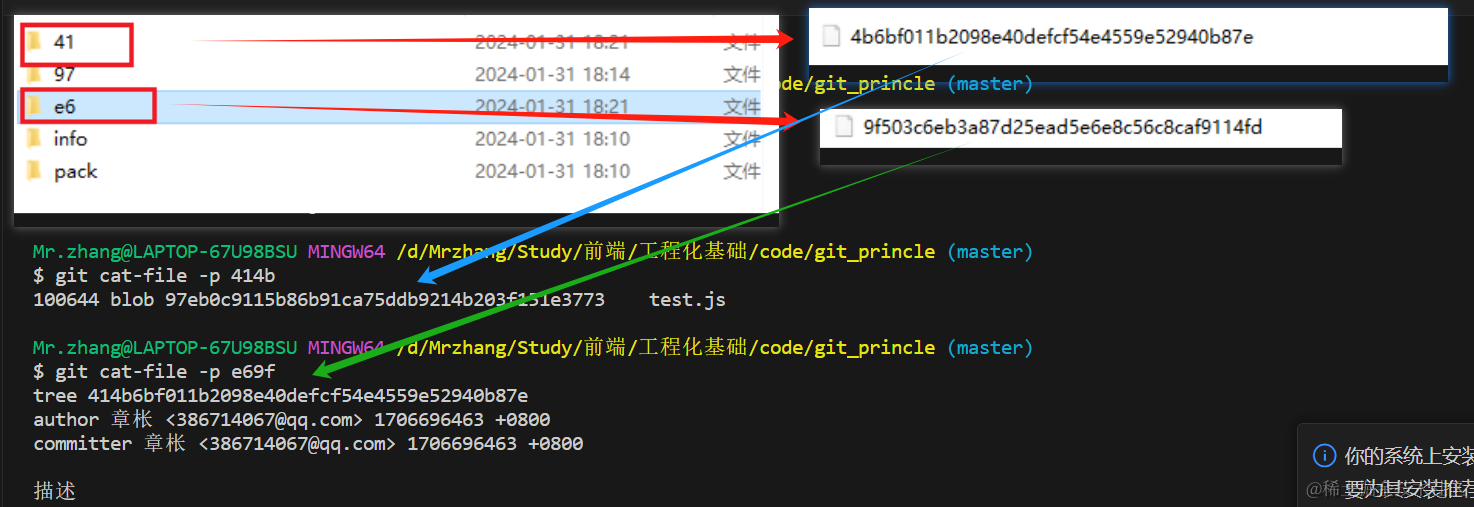
- 当我们执行
git commit -m "描述"命令- 会生成两个文件夹,41和e6
- 分别查看两个二进制文件,会发现在e6文件中,有一个tree 指向了41文件
- 而41 文件右指向了97中的文件
- 可以通过以下图形,进行理解
- 多次提交
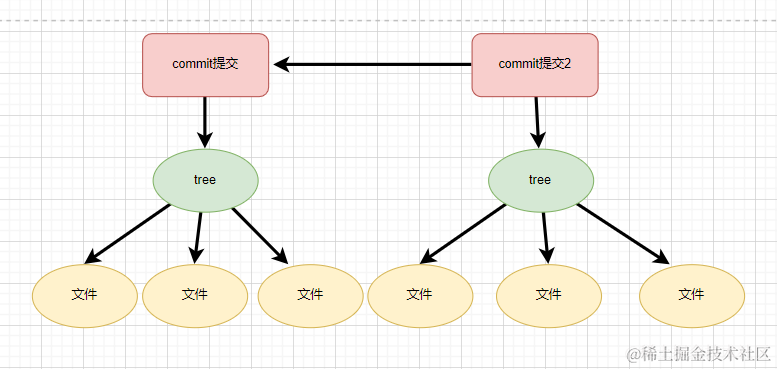
Git master分支
- 我们可以使用
git branch 分支名称来创建一个分支:例如创建一个 dev分支git branch dev - 而Git实现分支的切换,实际上是通过控制HEAD的指向进行控制的
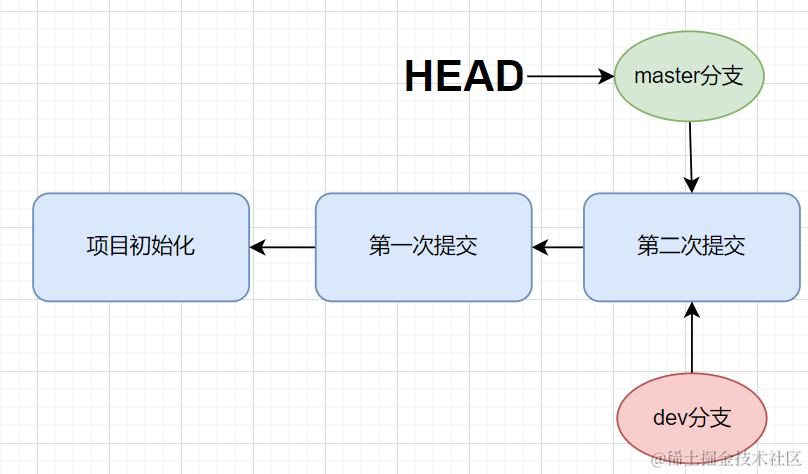
- 我们可以使用
git checkout dev来切换分支
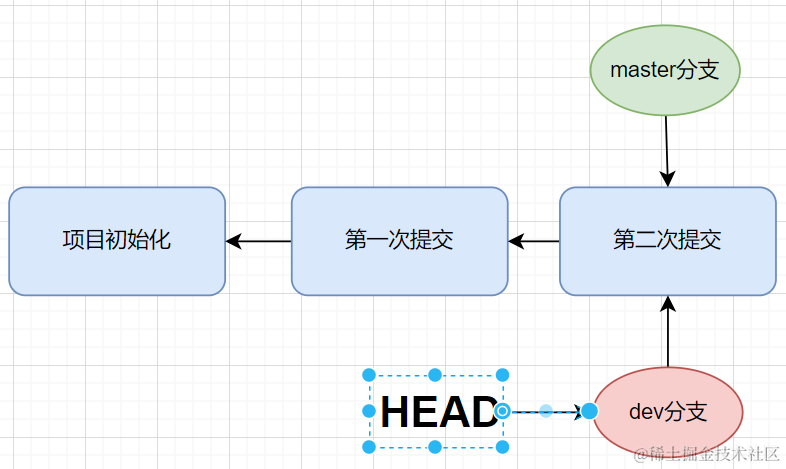
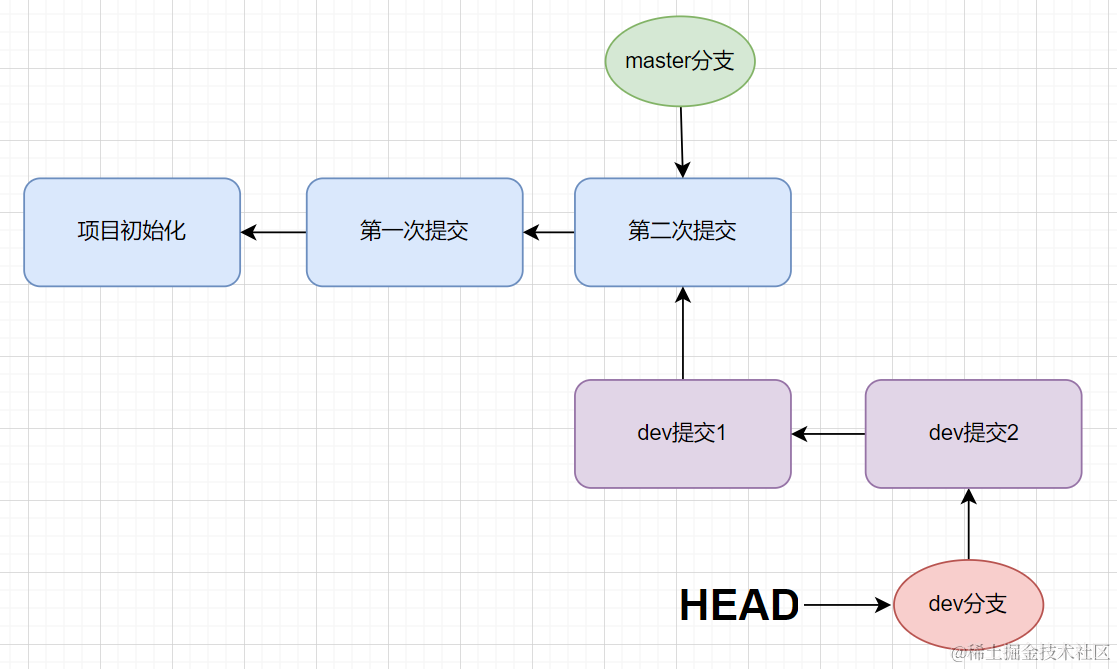
- 当我们在 dev分支进行了改动,并执行了
git add. git commit -m "描述"命令,会发生什么
- 同时我们可以使用一条命令创建分支的同时,并切换过去
git checkout -b prod,这样git的分支就切换到了 prod上面
为什么需要使用分支
- 我们在开发一个项目的时候,通常默认会在 master分支下进行开发
- 当开发到了一定进展的时候,就会发布,并打上tag标签
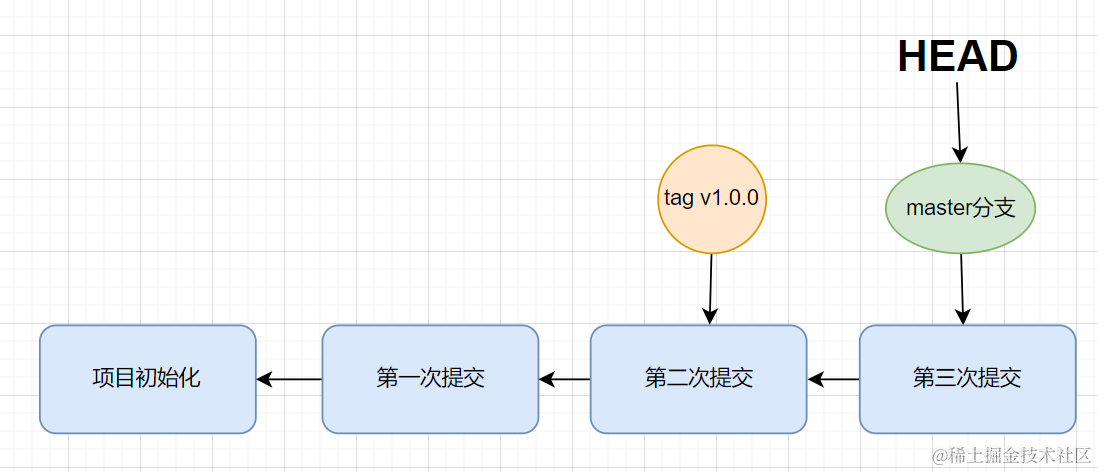
- 但是上线的 v1.0.0版本,此时发现了bug,此时,就需要创建一条新的分支hotfix,用于修复bug
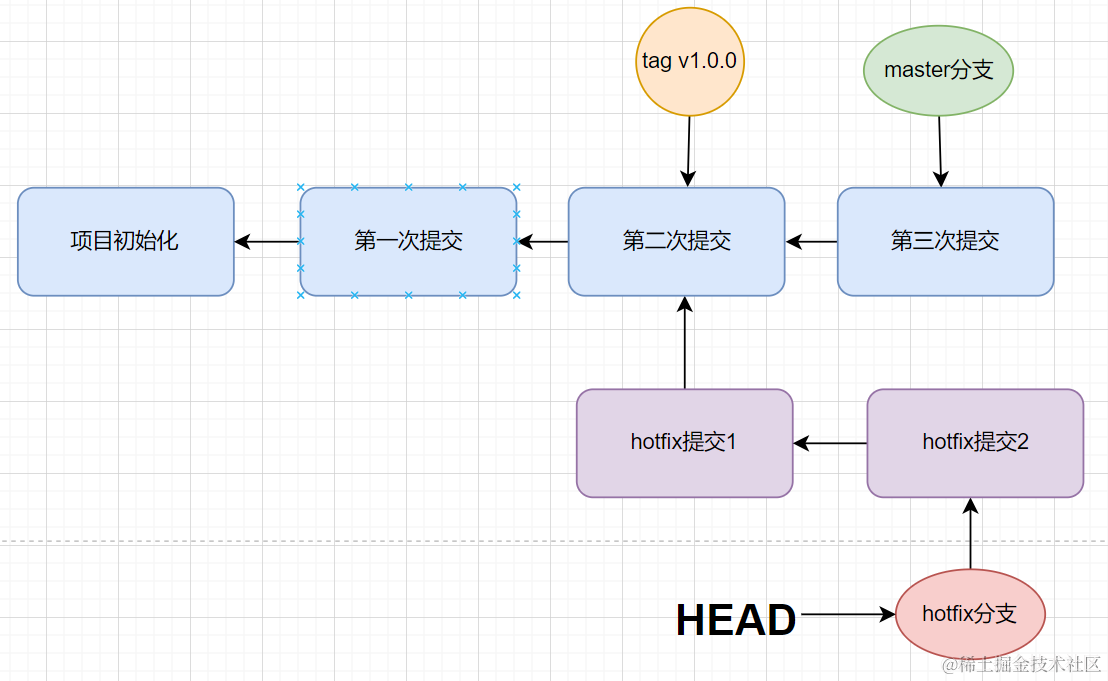
- 同时在后续的版本中,需要将master分支和 hotfix分支的代码进行合并操作
- 首先切换到主分支
git checkout master - 而后通过命令
git merge hotfix进行代码的合并,并提交代码

查看和删除分支
- 查看分支
git branch
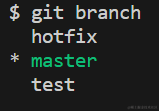
- 查看每个分支的最后一次提交
git branch -v

- 删除一个分支
git branch -d 分支名称- 注意删除的只是这个指针,所提交的文件不会删除
